





https://github.com/jindongwang/transferlearning/blob/master/data/dataset.md
迁移学习常用的数据集
数据集Office-31,Office+Caltech,VLSC都可以在该项目下找到)
一. Office-31
(Object recognition数据集)
包含了31类的数据,全部是Office的数据,数据来源为A(Amazon), W(Webcam) 和D(DSLR),BenchMark如下图所示:

二.Office+Caltech
(Object recognition数据集)
包含有2533个样本,包含(C A W D)四种数据库的数据, C(Caltech), A(Amazon), W(Webcam) 和D(DSLR),其中C有1123个,A有958个,W有295个,D有157个,数据集提供了SURF特征和DeCAF(A Deep Convolutional Activation Featurefor Generic Visual Recognition)特征

同一类物体在不同数据集中的具体实例
三.MNIST+USPS
手写体数字识别数据,随机从Mnist数据和USPS数据中选取的。Mnist每张图为28*28大小,一共70000张图片,10类数字。Usps数据集图片大小为16*16,共20000张图,10类数字,数据的下载网站为:sam roweis : data
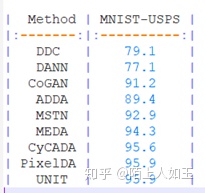
BenchMark
四.Animals-with-Attributes
下载网址Animals with Attributes 2,包含了37322个图片,有50种动物,同时提供了样本预先提取好的特征以及属性列表,该数据集可用于迁移学习和zero-shot,使用的时候需要引用https://doi.org/10.1109/TPAMI.2018.2857768,Zero-Shot Learning—A Comprehensive Evaluation of the Good, the Bad and the Ugly
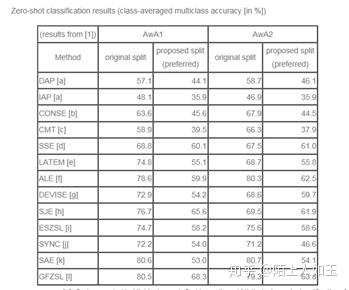

Benchmark以及示意图
五. Office-Home
2017CVPR发布的新的数据集,包含65种物体,主要面向domain adaptation领域的研究,网站地址:Page Redirection,包含有Artistic images, Clip Art, Product images and Real-World images

六.VisDA
VisDA: The Visual Domain Adaptation Challenge(2017),VisDA2017: Visual Domain Adaptation Challenge面向视觉领域适应任务,包括了目标分类和目标的分割,该比赛已经比了好几届了,目前2020年的任务也出来了,VisDA2020: Visual Domain Adaptation Challenge,不过今年的任务主要关注的是行人重识别。
1)分类任务

2)分割任务


















 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









