









1. 写作背景
——刚学到的知识如果不及时记录下来,很快就会被遗忘。
从上个月开始我就开始在Coursera平台学习吴恩达老师开设的深度学习课程。今天我已经学完第一门课程,并已经获得证书。这门课程不像之前的机器学习课程提供了完整的授课ppt,因为担心自己学完后会很快就忘记,以后回忆起来太费劲,所以决定在这里写下自己学习这门课程的笔记。
当然,我只会记录对我将来回忆有帮助的信息。只希望自己以后回忆起来会容易些。
由于前段时间刚学完吴老师的机器学习课程,并且其中有一章专门讲了神经网络,因此学习这门新课会简单轻松很多,所需要的背景基础知识基本都在机器学习课程里学过了。
2. 整体认识
线性回归→逻辑回归→神经网络
2.1 线性回归
线性回归是最简单也是最基础的机器学习算法;线性回归的原理:每个自变量乘以各自相应的系数,求和并加上一个常数项。公式如下:
2.2 逻辑回归
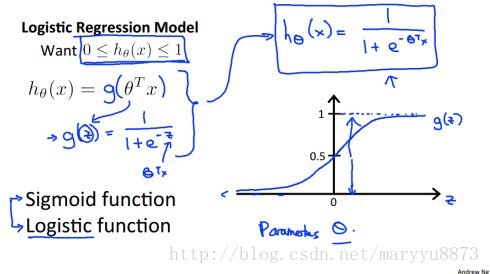
逻辑回归用于分类任务,它在线性回归的计算结果后面添加了一个叫做Sigmoid的激活函数,公式如下:
因为线性回归计算的结果是连续的数值,而分类任务的结果要求是不连续的类别,Sigmoid函数正好可以做到这一点。
2.3 神经网络
神经网络算法也主要用于解决分类任务,并且它的功能更为强大。上面提到的逻辑回归模型可以看做一个简单的单层神经网络模型,即没有隐藏层的神经网络。下图为一个典型的具有一个隐藏层的神经网络模型:
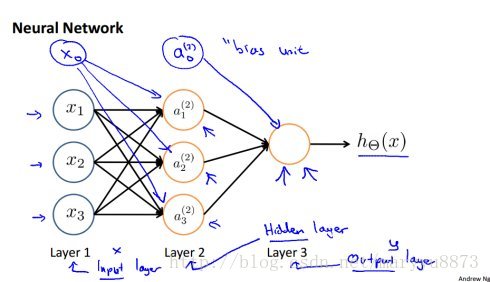
除了输入层外,其它每层的节点都可以看作由上一层所有节点经线性转换,再经激活函数映射所得。这里的激活函数包括之前提到的Sigmoid函数,还包括Relu函数。一般来说,对于神经网络算法,Sigmoid函数一般只用在最后对输出层的映射,中间的隐藏层用到的激活函数为Relu。Relu函数的公式如下:
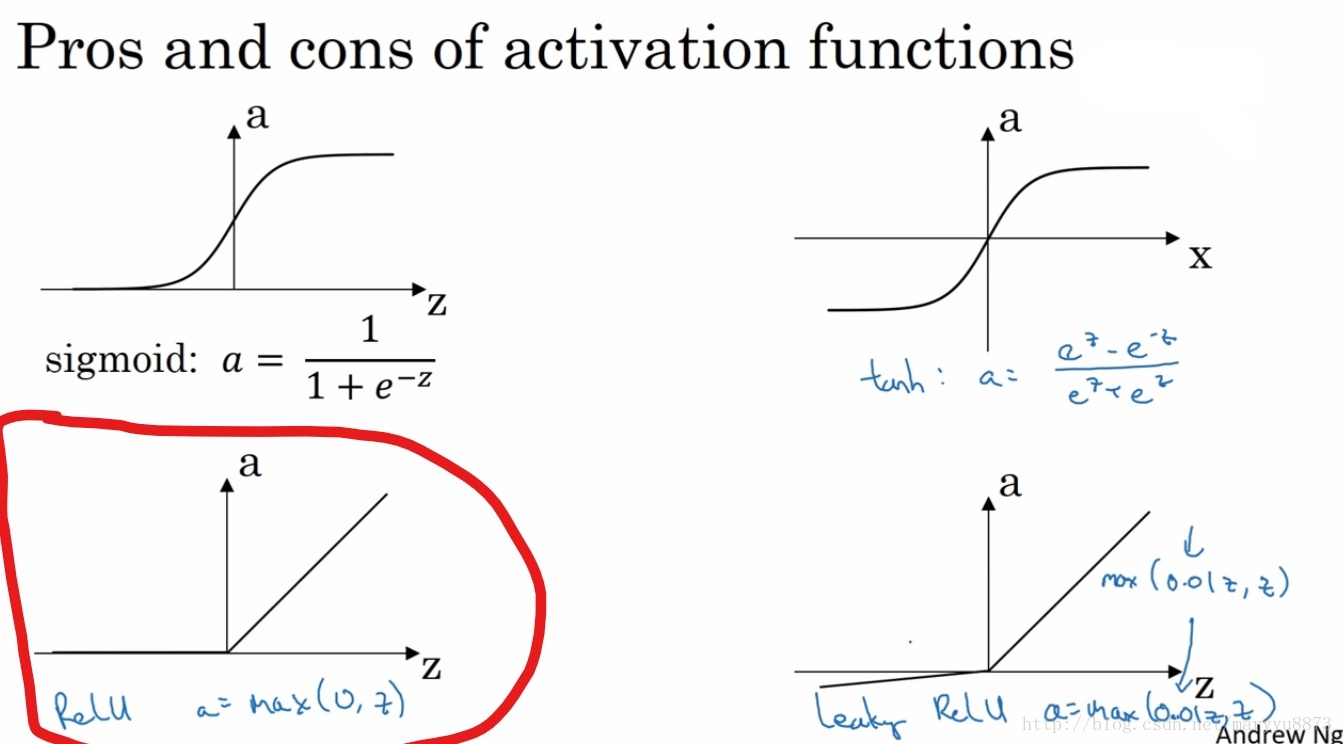
(其它的激活函数暂时没用到,所以先不讨论)
2.3.1 构造浅层神经网络
下面是我们将要构造的模型的结构,即:输入层由两个元素组成;只有一个隐藏层,包含四个节点;输出层只有一个节点。
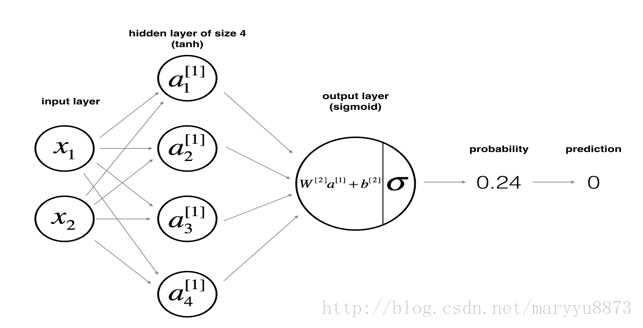
对于任意一个样本,需要经过如下的运算,最后获得预测值。
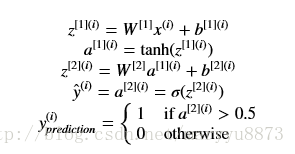
(注:这个模型中,隐藏层的激活函数为
tanh
,输出层的激活函数为
sigmoid
)
计算所有输入样本的损失函数:
搭建神经网络模型的一般思路:
1. 自定义该模型的结构(如输入变量个数、层数、节点数等);
2. 初始化模型的参数;
3. 循环:
3.1 部署前向传播(Forward propagation)
3.2 计算损失值
3.3 部署反向传播,并获得相应的梯度;
3.4 更新参数(梯度下降)
部署反向传播算法是整个环节最难的一部分,以下是相应的公式:

从上图可以看到,在反向传播的计算过程中,用到了中间层的
A
和
以下为该浅层神经网络的中间迭代过程:

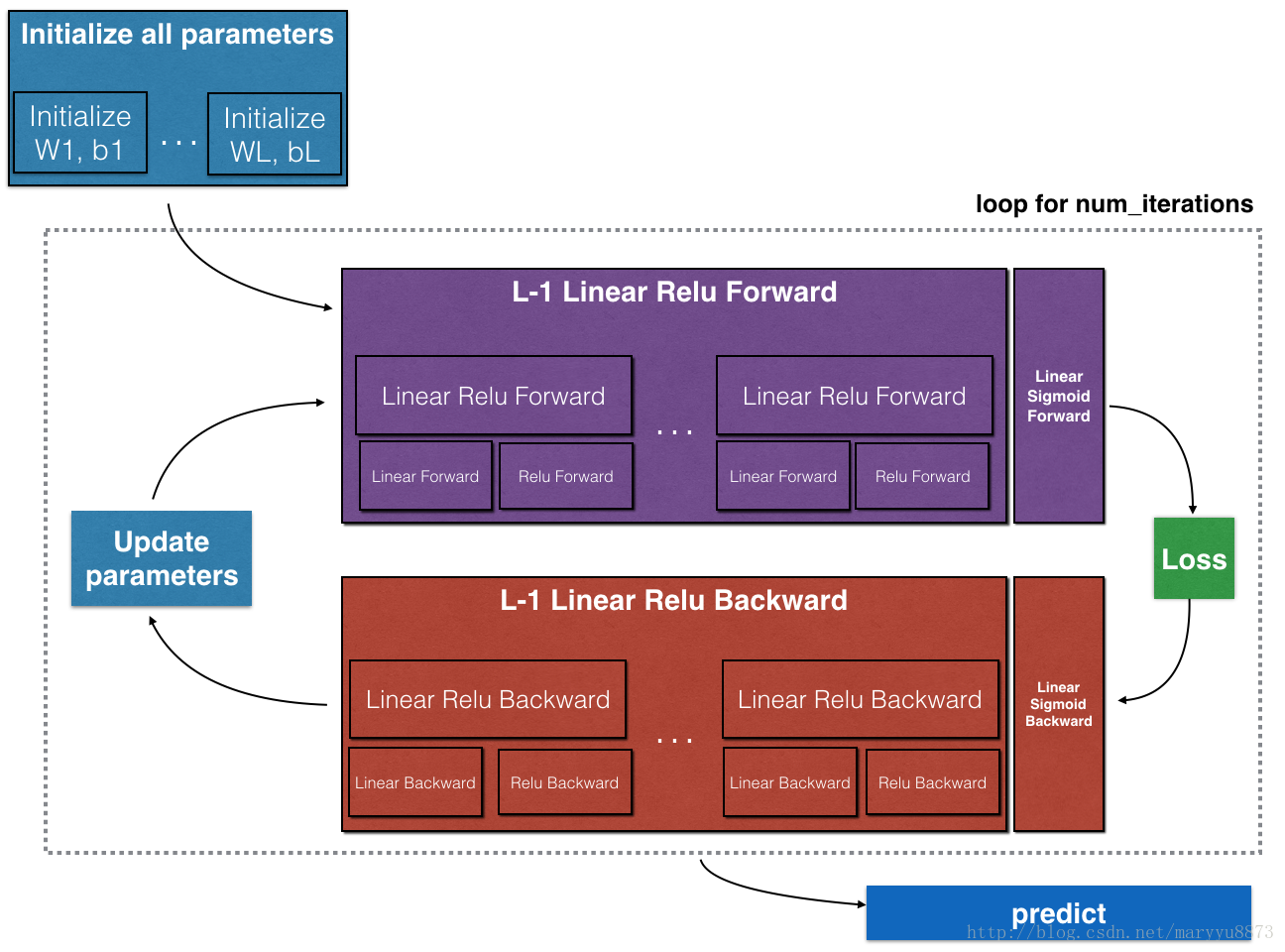
2.3.2 构造深层神经网络
深层神经网络意味着包含多个隐藏层,它是浅层神经网络的升级版,但是整个思路还是一样的。
- 初始化所有的参数;
- 部署前向传播模块;
( 在这里我们将隐藏层的激活函数设为relu,输出层的激活函数选择sigmoid;)
- 计算损失值;
- 部署反向传播模块;
- 更新参数;
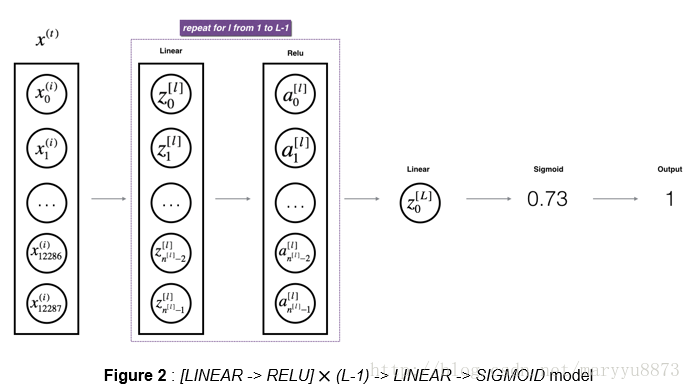
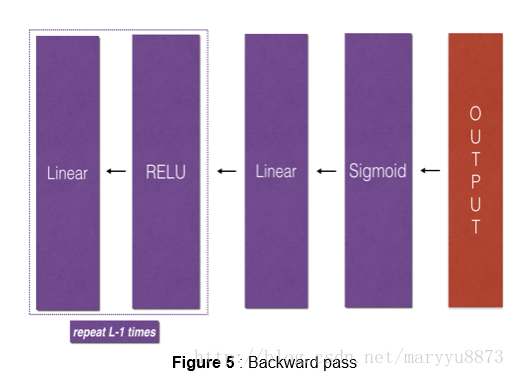
① 前向传播的构造
结构:[LINEAR→RELU]×(L-1)→LINEAR→SIGMOID
( it has L-1 layers using a ReLU activation function followed by an output layer with a sigmoid activation function)
② 损失值计算:
③ 反向传播模块的构造
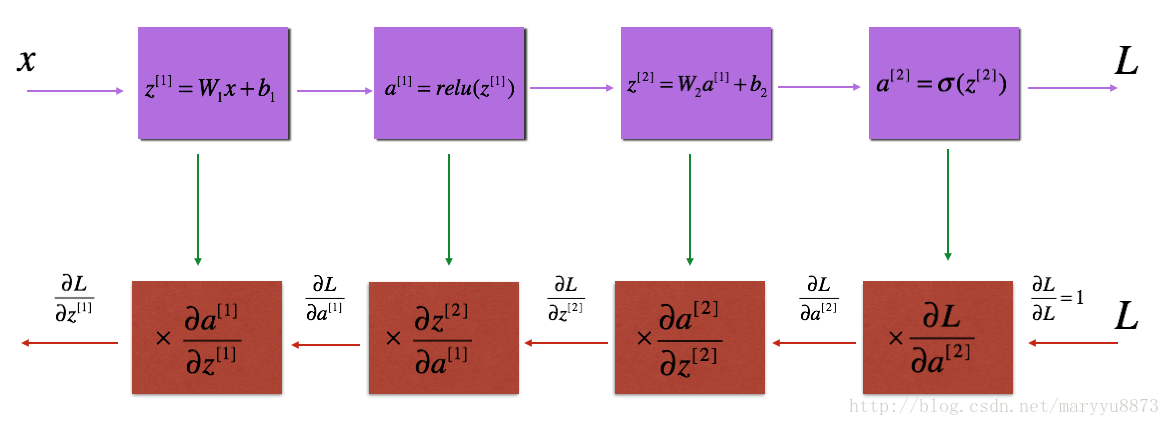
已知 dZ ,如何计算 dW , db , dA ?
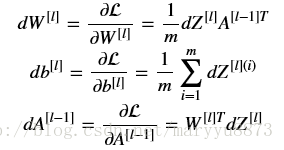
dZ
怎样计算而来:
其中 g,() 代表激活函数的导数。
从上述公式我们发现有一点特别的地方:在每次计算 dW[l] , db[l] 时,相应的却去计算 dA[l−1] ,即前一层的 dA 值。这是为什么呢?
首先,输出层即 L 层的
dAL 计算的代码如下:
dAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL))
并且前一层 dA[l−1] 的计算用到的是当前层的 dW[l] 和 dZ[l] 。因此,为了代码编写方便,把 dA[l−1] , dW[l] , dZ[l] 三个的计算放在一起了。
④ 更新参数
方法前面在浅层神经网络已经讲过。
注:如无特殊说明,以上所有图片均截选自吴恩达在Coursera开设的神经网络课程的讲义。














 854
854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









