







Backpropagation算法
1.首先总结4个方程
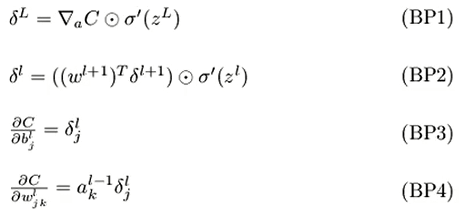
分别介绍:
![]()

1.BP1:输出层的delta 也就是∂C/∂z,根据链接法则,∂C/∂z = ∂C/∂a * ∂a/∂z 注意这个*指的是点乘 也就是对应的元素相乘,而不是矩阵乘法
而对于
不同Cost函数 有不同的
对应的
2.算完该输出层的delta 再求该层的BP3和BP4


∂C/∂b=delta
∂C/∂w = delta与前一层的输出值也就是a进行点乘
为什么:
这是因为根据链接法则,
∂C/∂w =∂C/∂z * ∂z/∂w
z= wx + b
∂z/∂w = x 也就是上一层的a
用代码表示:
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta,activations[-2].transpose())
nabla_w[-1] = np.dot(delta,activations[-2].transpose())
接下来进行隐藏层的遍历
首先算出该层的delta
非输出层的误差依赖于其下一层误差

也就是说 计算该层delta需要 下一层的W 与 下一层的delta进行点乘
然后在计算BP3和BP4
用代码表示
for l in xrange(2,self.num_layers):
z = zs[-l]
sp = sigmoid_prime[z]
delta = np.dot(self.weights[-l+1].transpose(),delta) * sp
nabla_b[-l] = delta
nabla_w[-l]= np.dot(delta,activations[-l-1].transpose())
num_layers:神经网络的层数
为什么bp算法快?
Backpropagation算法的优势在于让我们在一前一后遍历神经网络的时候,就可以把所有的偏导数计算出来
Backpropagation算法总结

用代码表示:
def backprop(self,x,y):
activation = x
activations = [x]
zs = []
for b,w in zip(self.biases,self.weights):
z = np.dot(w,activation)+b
zs.append(z)
activation = sigmoid(zs)
activations.append(activation)
#backward pass
delta = self.cost_derivatice(activations[-1],y) * sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta,activations[-2].transpose())
for l in xrange(2,self.num_layers):
z = zs[-l]
sp = sigmoid_prime[z]
delta = np.dot(self.weights[-l+1].transpose(),delta) * sp
nabla_b[-l] = delta
nabla_w[-l]= np.dot(delta,activations[-l-1].transpose())
return(nabla_b,nabla_w)














 401
401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









