







 本文介绍了Hadoop的分布式文件系统HDFS的架构,包括NameNode、DataNode和Client的角色,强调了HDFS的设计目标是面向超大文件和高容错性,采用中心总控式架构,支持write-once-read-many的访问模型。
本文介绍了Hadoop的分布式文件系统HDFS的架构,包括NameNode、DataNode和Client的角色,强调了HDFS的设计目标是面向超大文件和高容错性,采用中心总控式架构,支持write-once-read-many的访问模型。
本文以 Hadoop 提供的分布式文件系统(HDFS)为例来进一步展开解析分布式存储服务架构设计的要点。
架构目标
任何一种软件框架或服务都是为了解决特定问题而产生的。还记得我们在 《分布式存储 - 概述》一文中描述的几个关注方面么?分布式文件系统属于分布式存储中的一种面向文件的数据模型,它需要解决单机文件系统面临的容量扩展和容错问题。
所以 HDFS 的架构设计目标就呼之欲出了:
- 面向超大文件或大量的文件数据集
- 自动检测局部的硬件错误并快速恢复
基于此目标,考虑应用场景出于简化设计和实现的目的,HDFS 假设了一种 write-once-read-many 的文件访问模型。这种一次写入并被大量读出的模型在现实中确实适应很多业务场景,架构设计的此类假设是合理的。正因为此类假设的存在,也限定了它的应用场景。
架构总揽
下面是一张来自官方文档的架构图:
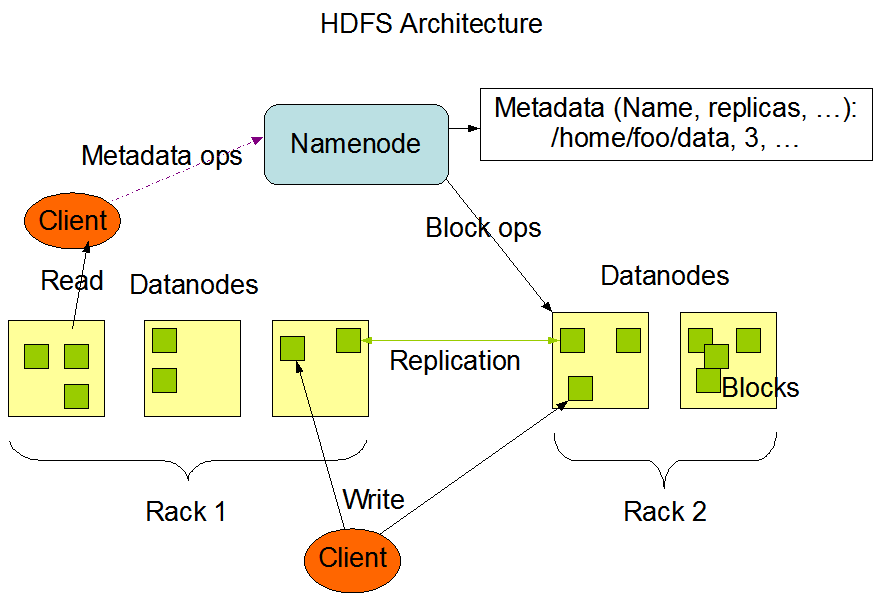
从图中可见 HDFS 的架构包括三个部分,每个部分有各自清晰的职责划分。
- NameNode
- DataNode
- Client
从图中可见,HDFS 采用的是中心总控式架构,NameNode 就是集群的中心节点。
NameNode
NameNode 的主要职责是管理整个文件系统的元信息(Metadata),元信息主要包括
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1356
1356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









