






HDFS分布式存储系统
HDFS存储架构

文件存储系统原理
文件存储在磁盘上,磁盘读取数据靠的是机械运动。
- 当需要从磁盘读取数据时,系统会将数据逻辑地址传给磁盘,磁盘的控制电路按照寻址逻辑将逻辑地址翻译成物理地址,即确定要读的数据在哪个磁道,哪个扇区。为了读取这个扇区的数据,需要将磁头放到这个扇区上方,
- 为了实现这一点,磁头需要移动对准相应磁道,这个过程叫做寻道,所耗费时间叫做寻道时间,然后磁盘旋转将目标扇区旋转到磁头下,这个过程耗费的时间叫做旋转时间。
- 最后是对读取数据的传输。
所以每次读取数据花费的时间可以分为 寻道时间、旋转延迟、传输时间 三个部分
HDFS读取文件的时间就可以分为寻址时间和数据传输时间,如果文件太小,在名称节点的映射列表会过大,影响寻址时间,寻址时间如果大于传输时间,就没有意义了。所以设置成大文件。
如果Block设置过大,在MapReduce任务中,Map或者Reduce任务的个数小于集群机器数量,会使得作业运行效率很低。
链接:https://www.codercto.com/a/69093.html
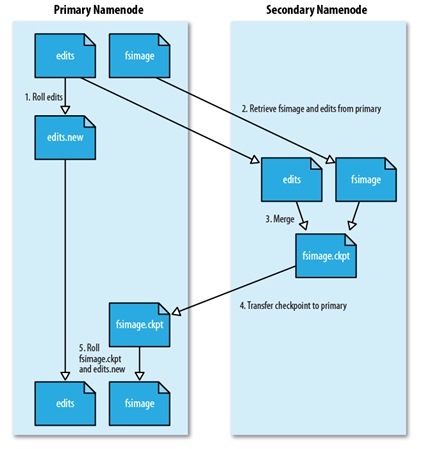
secondary namenode 的工作流程
-
secondDaryNameNode会定期与NameNode通信,暂停EditLog,创建新的EditNew,瞬间完成 。
-
FsImage和EditLog会不断增大,secondDaryNameNode可以解决这个问题,它会定期拉取这两个文件,进行一个合并过程,通过执行EditLog文件,得到最新的FsImage,推送到NameNode, 代替原有的FsImage,同时使用editNew代替原有EditLog文件。
-
secondDaryNameNode 还可以作为冷备份,在NameNode宕机后使用它进行恢复
-
链接:https://www.codercto.com/a/69093.html
HDFS写数据流程

-
客户端通过调用DistributedFileSystem的create方法,创建一个新文件。
-
客户端向NameNode请求创建新文件
DistributedFileSystem通过RPC(远程过程调用)调用NameNode,去创建一个没有blocks关联的新文件。创建前,NN会进行各种校验,如果校验通过,NN就会记录下新文件,否则抛出I/O异常。
-
客户端将数据切分为packet
前两步结束后会返回一个FSDataOutputStream对象,客户端开始写数据到FSDataOutputStream,FSDataOutputStream会把数据切成一个个小packet,然后排成data queue。
-
客户端从NameNode处获取DateNode信息,开始向DN1传输数据
DataStreamer (负责把Packet传输到DateNote)会去处理接受 data queue,它先问询 NameNode 这个新的 block 最适合存储的在哪几个DataNode里,比如重复数是3,那么就找到3个最适合的 DataNode,把它们排成一个 pipeline。DataStreamer 把 packet 按队列输出到管道的第一个 DataNode 中,第一个 DataNode又把 packet 输出到第二个 DataNode 中,以此类推。
-
各节点向客户端返回ack信息
DFSOutputStream 还有一个队列叫 ack queue,传输时将dataQuene中的Packet按顺序发送,发送后放入到ackQuene队列,等待节点应答,客户端收到全部节点的应答后,在ackQuene中删除该Packet;如果应答超时,则将该Packet回滚至dataQuene,重新建立通道,剔除故障节点后继续传输
-
客户端收回全部ack消息后,关闭数据写入
客户端完成写数据后,调用close方法关闭写入流。
-
客户端通知NameNode文件上传完毕
通知 NameNode 把文件标示为已完成。
注意:
-
此为一个block上传流程,全部block上传则重复4-5步骤
-
上传过程中如果有节点出现故障会跳过此节点,HDFS后续会自行补全副本数量。
-
只要有一个DN节点收到了数据,DN上报NN已经收完此块,NN就认为当前块已经传输成功。
HDFS读数据流程

-
客户端调用FileSystem的open方法获取一个DistributedFileSystem实例。
-
通过NameNode获得block信息
DistributedFileSystem通过RPC(远程过程调用)获得文件的第一批block的locations,同一个block按照重复数返回多个locations,这些locations按照Hadoop拓扑结构排序,按照就近原则进行排序。
-
按照就近原则,选取DateNode进行连接
前两步结束后会返回一个FSDataInputStream对象,通过调用read方法时,该对象会找出离客户端最近的DataNode并连接。
-
读取下一个block
如果第一个block块数据读取完成,就会关闭指向第一个block块的DataNode连接,接着读取下一个block块。
-
关闭数据读取
如果第一批blocks读取完成,FSDataInputStream会向NN获取下一批blocks的locations,然后重复3、4步骤,直到所有blocks读取完成,这时就会关闭所有的流。















 3017
3017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









