









这里我们爬取的小说是网站:笔趣阁,其中一本小说:一念永恒。
(一)准备阶段
1、网站URL:http://www.biqukan.com/1_1094/
2、浏览器:搜狗
3、我们打开网址,找到搜狗浏览器的审查元素(F12),可以看到class为”listmain”的div标签中的内容是我们想要的小说每个章节的链接地址。
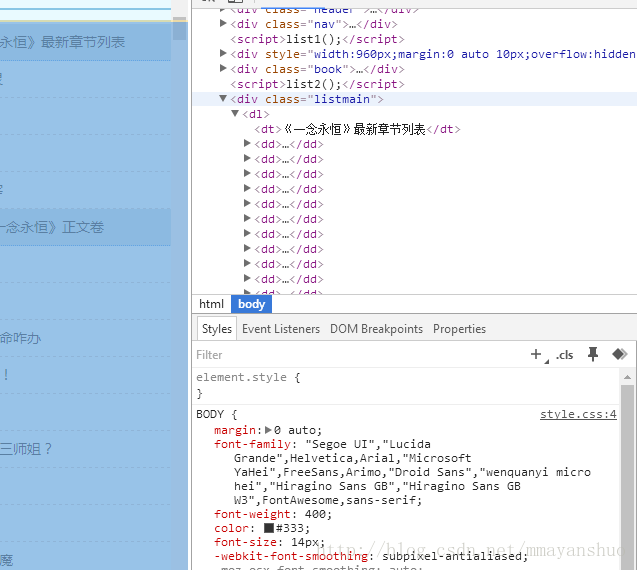
4、我们单击其中一个章节的链接。我们发现,每个章节的正文内容放在class为”content”的div 标签中。
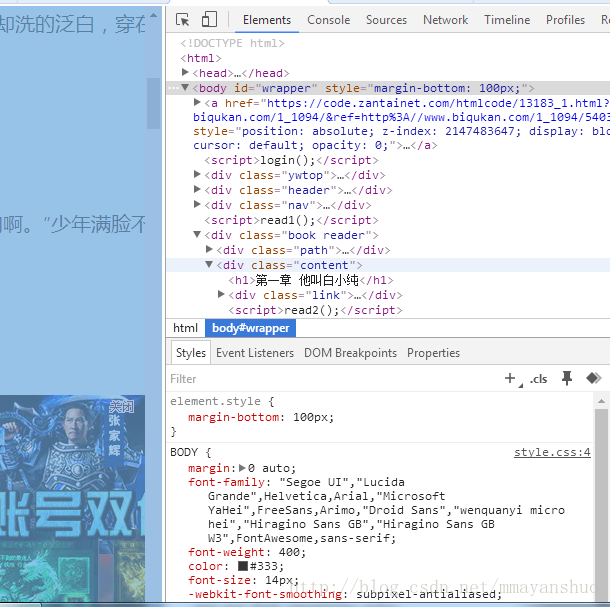
有了这些了解,接下来就可以编写代码。
(二)代码实现:
这里我们将整个代码工程写了四个文件,对应有四个类。
文件shenmu_main.py是程序运行的入口。
shenmu_main.py:
# -*- coding: utf-8 -*-
"""
主程序
"""
from xiaoshuo import shenmu_parse
from xiaoshuo import ProcessPoolDownload
from xiaoshuo import shenmu_downloader
class SpiderMain(object):
def __init__(self):
self.Htmldownloader= shenmu_downloader.HtmlDownLoader()
self.parse = shenmu_parse.HtmlParse()
self.PoolDown = ProcessPoolDownload.PoolDownLoader()
def TheStart(self,target_url):
#一念永恒小说目录地址
target_html=self.Htmldownloader.downloader(target_url)
new_urls=self.parse.parse(target_html)
self.PoolDown.oneprocess(new_urls)
#self.PoolDown.ThreadDown(new_urls)
if __name__ == "__main__":
target_url = 'http://www.biqukan.com/1_1094/'
Spider=SpiderMain()
Spider.TheStart(target_url)
shenmu_downloader.py实现了下载小说整个主页面,也就是包含小说各个章节链接的页面。
# -*- coding: utf-8 -*-
"""
Created on Fri Dec 29 18:12:11 2017
@author: Administrator
"""
from urllib import request,error
class HtmlDownLoader(object):
def downloader(self,target_url,retry_count=3):
if target_url is None:
return None
try:
#User-Agent
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
target_req = request.Request(url = target_url, headers = head)
target_response = request.urlopen(target_req)
target_html = target_response.read().decode('gbk','ignore')
#print("整个页面"+target_html)
except error.URLError as e:
print("HtmlDownLoader download error:",e.reason)
target_html=None
if retry_count>0: #重试下载
if hasattr(e, 'code') and 500 <= e.code < 600:
return self.downloader(target_url,retry_count-1)
return target_html
shenmu_parse.py解析shenmu_downloader传递来的HTML。分析出各个章节的链接地址返回。
# -*- coding: utf-8 -*-
"""
用BeautifulSoup分析小说每个章节的链接
"""
from bs4 import BeautifulSoup
import queue
class HtmlParse(object):
def parse(self,target_html,html_encode="utf-8"):
if target_html is None:
return
#print(target_html)
#创建BeautifulSoup对象
listmain_soup = BeautifulSoup(target_html,'lxml')
#搜索文档树,找出div标签中class为listmain的所有子标签
chapters = listmain_soup.find_all('div',class_ = 'listmain')
#使用查询结果再创建一个BeautifulSoup对象,对其继续进行解析
download_soup = BeautifulSoup(str(chapters), 'lxml')
# print(download_soup)
new_urls=self._get_new_urls(download_soup)
return new_urls
def _get_new_urls(self,download_soup):
#print(download_soup)
#new_urls集合用于存储每章的链接
new_urls=queue.Queue()
#开始记录内容标志位,只要正文卷下面的链接,最新章节列表链接剔除
begin_flag = False
#遍历dl标签下所有子节点
for child in download_soup.dl.children:
#滤除回车
if child != '\n':
#找到《神墓》正文卷,使能标志位
if child.string == u"《一念永恒》正文卷":
begin_flag = True
#爬取链接并下载链接内容
if begin_flag == True and child.a != None:
download_url = "http://www.biqukan.com" + child.a.get('href')
new_urls.put(download_url)
return new_urls
ProcessPoolDownload.py实现了从各个章节链接下载小说正文,并写入txt文件中。下载方式有单进程和多线程。
# -*- coding: utf-8 -*-
"""
下载每个章节的内容
"""
from urllib import request
from multiprocessing import Pool
from multiprocessing import Lock
from threading import Thread #线程
from bs4 import BeautifulSoup
import sys
import threading
import datetime
import queue
class PoolDownLoader(object):
def __init__(self):
self.new_urls=queue.Queue()
self.lock=threading.Lock()
self.lock1=threading.Lock()
def WriteText(self,download_name,texts):
file = open('一念永恒1.txt', 'a', encoding='utf-8')
soup_text = BeautifulSoup(str(texts), 'lxml')
write_flag = True
file.write(download_name + '\n\n')
for each in soup_text.div.text.replace('\xa0',''):
if each == 'h':
write_flag = False
if write_flag == True and each != ' ':
file.write(each)
if write_flag == True and each == '\r':
file.write('\n')
file.write('\n\n')
#打印爬取进度
print("已下载:"+download_name + '\r')
def funcDown(self,download_url):
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19'
download_req = request.Request(url = download_url, headers = head)
download_response = request.urlopen(download_req)
download_html = download_response.read().decode('gbk','ignore')
soup_texts = BeautifulSoup(download_html, 'lxml')
h1=soup_texts.h1.string
texts = soup_texts.find_all(id = 'content', class_ = 'showtxt')
#print(h1)
self.lock.acquire()
self.WriteText(h1,texts)
self.lock.release()
def PoolDown(self,new_urls):
lock = Lock()
p=Pool(processes=4,initargs=(lock,))
for download_url in new_urls:
#print(download_url)
p.apply_async(self.funcDown,args=(download_url,))
p.close()
p.join()
print("小说下载完成,已写入文档!\n")
def ThreadDown(self,new_urls):
starttime=datetime.datetime.now()
self.new_urls=new_urls
threads=[]
while threads or self.new_urls:
for thread in threads:
if not thread.isAlive():
threads.remove(thread)
while len(threads)<8 and not self.new_urls.empty():
new_url=self.new_urls.get()
thread =threading.Thread(target=self.funcDown,args=(new_url,))
thread.setDaemon(True)
thread.start()
threads.append(thread)
#thread.join()
endtime=datetime.datetime.now()
print("下载小说共用了;",(endtime-starttime).seconds)
def oneprocess(self,new_urls):
starttime=datetime.datetime.now()
self.new_urls=new_urls
while not self.new_urls.empty():
new_url=new_urls.get()
self.funcDown(new_url)
endtime=datetime.datetime.now()
print("下载小说共用了:",(endtime-starttime).seconds)
(三)结果分析:
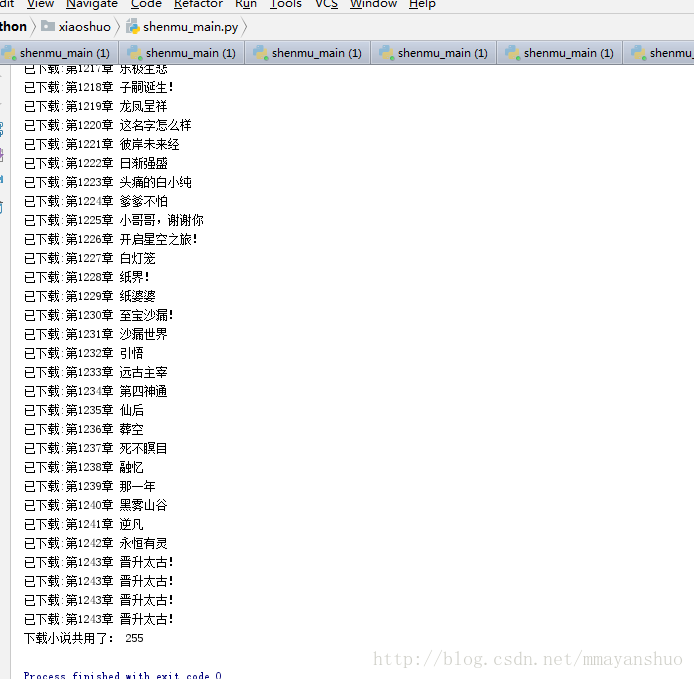
单进程结果: 可以看到单进程,是严格按照顺序下载的,下载时间较短。
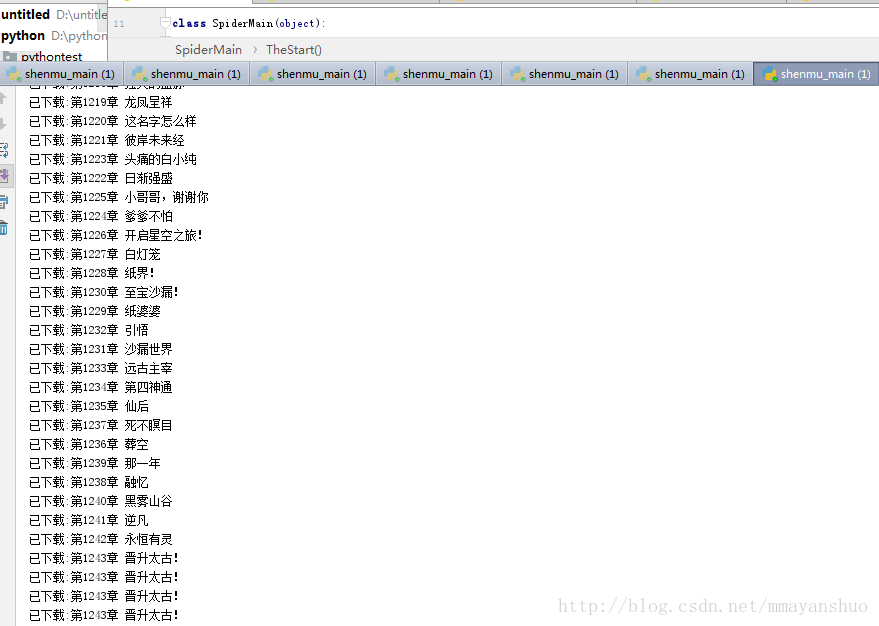
多线程结果: 可以看到多线程,不是严格按照顺序下载的,下载时间比单进程要长,是因为在写入文档时加了线程锁,大型工程多线程肯定要比单进程要高效。
(四)技术讲解:
先占个坑,以后写。














 1767
1767











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









