








在上一节的课程中,我们讲到
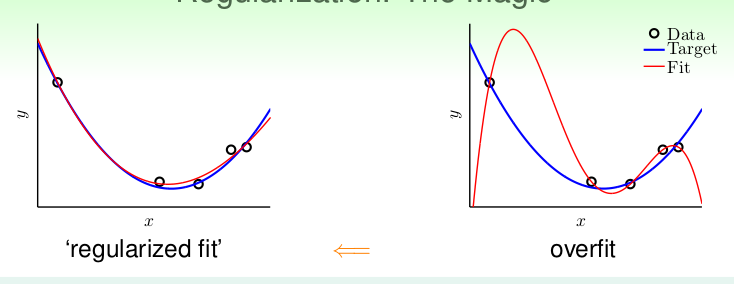
右图用的是10次方程去拟合,左图用的是2次方程去拟合。很显然10次方程发生过拟合现象。那么我们就选择化简模型,将10次模型转化为2次模型。
我们先假设将x域映射到z域的函数
Φ(x)
为(对于所有的非线性模型,都存在映射函数
Φ(x)
)
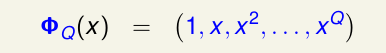
那么10次模型和2次模型的表达式分别为
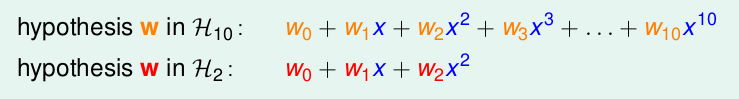
通过比较,可以发现,要想把10次模型转化为2次模型,只需将
w3,w4,...,w10
都设为0即可。即

所以,我们的方法就是,加约束条件。
所以我们的转化就是

但是,我们发现,完全把10次降为2次太过头了。比如也许模型
x6+x+1=0
比模型
x2+x+1=0
要好。所以,我们就把约束条件放松一些,即我们希望
w10,w9,...,w0
只要有8为0就行了,而不是一定
w10,w9,...,w3
为0.
即变为

其实,对于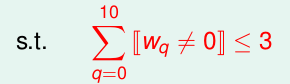

其实这样还有个好处:他又把要求放松了一些。他不是要求一定要有8个w为0,而是要求所有的权重平方和小于C就行。C是我们自己给的。
为了简单,我们现在只考虑线性模型
那么他的
Ein
为
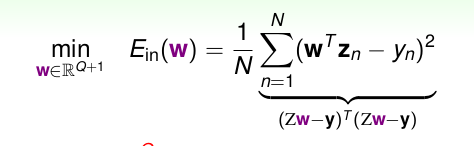
他的约束条件为

总结就是
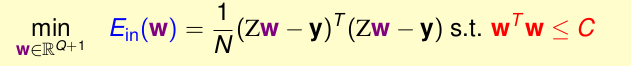
如果没有约束条件的话,那么要想最小化
Ein
,那么只需求出沿着梯度的方向一只滚到谷底就行,但是现在有了约束条件
不难发现,
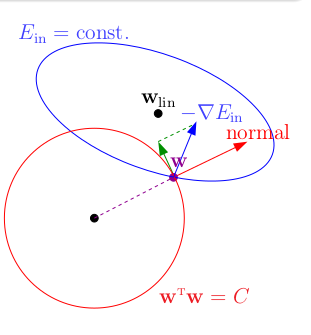
一般情况下,离谷底最近的点是在圆的边界上面的。那在什么时候有最优解呢?就是不能再下降的时候。梯度方向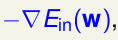
所以我们就将
转化为了

这样做的好处,就是他对于w是线性的,可以直接求出来

这称为岭回归
在模型是线性回归,且加上权重平方和作为惩罚函数的(即 ||w||2 )就是岭回归。
一般模型
我们上面讲的是认为模型是线性回归,所以
Ein
已经给好了。那么现在处理其他模型情况。

我们回想一下,我们以前想最小化
Ein
,那么我们令他的梯度为0就行。所以我们把上面的式子就认为是某一函数的梯度,求这个梯度为0,就是想最小化某一个函数,这个函数就是上面式子的积分

所以可以总结为

注意:
λ
很小的时候(比如0.001),就可以使得模型很大程度避免过拟合,大了(比如1),反而会欠拟合。
λ
是人为给定的,具体取值方法见下一讲。
λ
越大,就会使得模型权重w减小,模型抖动就小,就越简单。
我们回想一下,我们先前有假设映射函数为
当数据都处于[-1,1]之间时,对于高次幂
xQn
的数据,就会比其他次幂小的多。如果我们模型需要高次幂,但是
xQn
很小,那么就必须增大权重来提高其影响力,但是惩罚函数又会限制权重的增大,这就照成了问题。方法就是让
Φ(x)
内的向量是互相正交的,即Legendre polynomials。

选择最好的惩罚函数
- 根据我们想要的target function f来选
比如,我知道我的f(x)是偶函数,那么我就希望我的g内偶次幂的权重大。即我要尽可能降低我奇次幂的权重。即把惩罚函数设为 - 如果我希望我们模型光滑,简单,那就用L1规范
- 如果我希望我的模型任意达到最优,就是效果好,那就用L2规范
L1要求低,精度低,但计算量小



L1,L2 规范
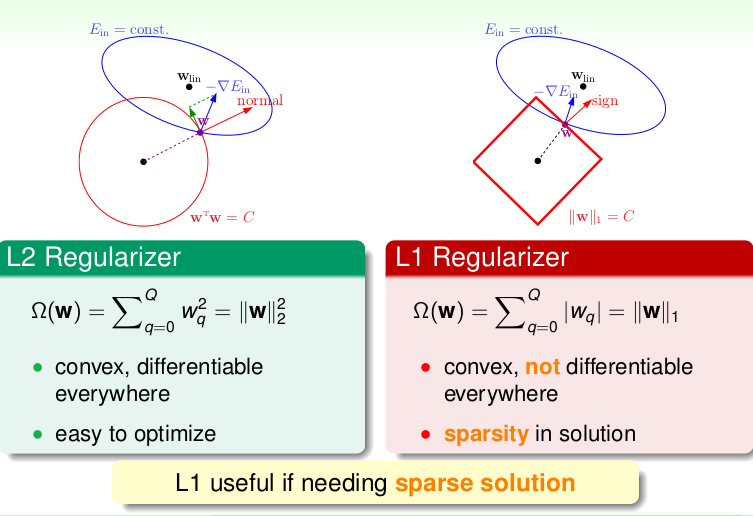
L1要求低,精度低,但计算量小
那如何选择 λ 呢?见下一讲















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









