






什么是惩罚项?
机器学习中,损失函数后接的补充项就是惩罚项。
训练中希望得到简洁,泛化能力强的模型。随着训练使用的数据越多,特征维度也多,模型泛化能力会变差,也就是过拟合,为了掌握一种平衡增加惩罚项
L1正则化
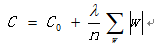
L1正则项,是指权重中各个向量的绝对值之和,可以产生稀疏矩阵,只有少量参数决定结果,模型抗噪性比较好。
系数矩阵:(特征矩阵内部分特征为非0,比如上百万个特征,只有部分是非零的,做分类或者预测的时候模型只关注非零特征就可
L2正则化:
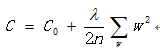
L2正则项,是权重中各个**向量平方和,**可以防止过拟合,用到全部参数。
如何使用惩罚项**
一般最开始先不加惩罚,等模型训练结束后,再使用正则项改进
惩罚系数λ一般可以设置为1、5、10、15、20……这样的值进行尝试,也可以用1、100、50、25(75)这种二分法的方法尝试,去观察当前的λ是不是有效的提高了准确率
加惩罚项代码
keras中加L2惩罚

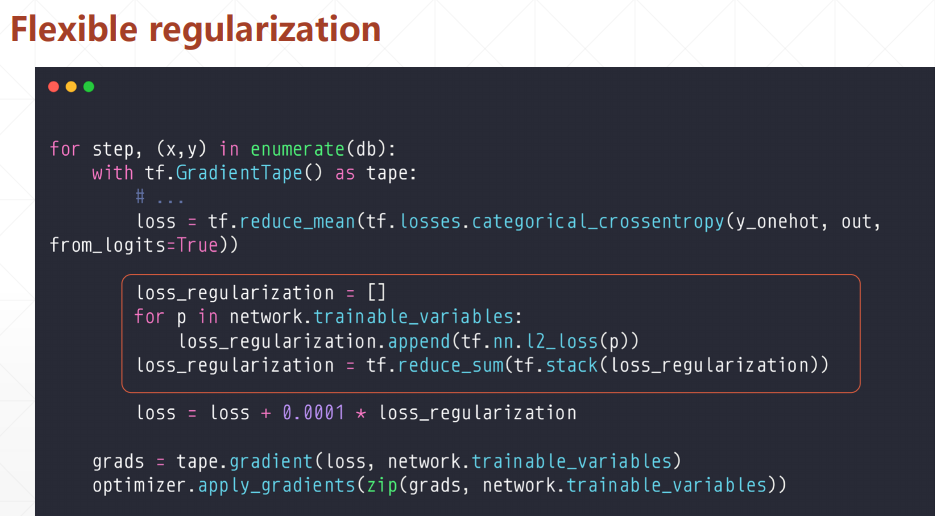
tf中加L2正则















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









