







VS2015+CUDA8.0环境配置
Anyway,在这里记录下正确的配置方式:
1、首先,上官网下载对应vs版本的CUDA toolkit:
https://developer.nvidia.com/cuda-toolkit-50-archive
(记住vs2010对应CUDA5.0,vs2013对应CUDA7.5,vs2015对应CUDA8.0)
2、接着,直接安装,记得在安装过程中如果你不想换你原有的显卡驱动的话,就选择自定义不安装driver;否则如果你直接选“精简”又不安装驱动,则CUDA安装无法成功。
3、安装完成之后,进入C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0 之后可以看到有好几个文件夹:bin、lib 、include等等,这就表明安装成功了
4、接下来,看看如何创建一个利用cuda编程的项目,打开vs创建项目时,你可以看到有了新的项目类型:

但是我们这里教你如何在一个空项目中编译cu文件,所以我们还是 创建一个vc++的空项目,接着创建一个新的cpp文件和cu文件
test.cpp代码如下:
#include <time.h>
#include <stdlib.h>
#include <stdio.h>
//这里不要忘了加引用声明
extern "C" void MatrixMultiplication_CUDA(const float* M, const float* N, float* P, int Width);
//构造函数...
//析构函数...
// 产生矩阵,矩阵中元素0~1
void matgen(float* a, int Width)
{
int i, j;
for (i = 0; i < Width; i++)
{
for (j = 0; j < Width; j++)
{
a[i * Width + j] = (float)rand() / RAND_MAX + (float)rand() / (RAND_MAX*RAND_MAX);
}
}
}
//矩阵乘法(CPU验证)
void MatrixMultiplication(const float* M, const float* N, float* P, int Width)
{
int i, j, k;
for (i = 0; i < Width; i++)
{
for (j = 0; j < Width; j++)
{
float sum = 0;
for (k = 0; k < Width; k++)
{
sum += M[i * Width + k] * N[k * Width + j];
}
P[i * Width + j] = sum;
}
}
}
double MatrixMul_GPU()
{
float *M, *N, *Pg;
int Width = 1024; //1024×1024矩阵乘法
M = (float*)malloc(sizeof(float)* Width * Width);
N = (float*)malloc(sizeof(float)* Width * Width);
Pg = (float*)malloc(sizeof(float)* Width * Width); //保存GPU计算结果
srand(0);
matgen(M, Width); //产生矩阵M
matgen(N, Width); //产生矩阵N
double timeStart, timeEnd; //定义时间,求时间差用
timeStart = clock();
MatrixMultiplication_CUDA(M, N, Pg, Width); //GPU上计算
timeEnd = clock();
free(M);
free(N);
free(Pg);
return timeEnd - timeStart;
}
double MatrixMul_CPU()
{
float *M, *N, *Pc;
int Width = 1024; //1024×1024矩阵乘法
M = (float*)malloc(sizeof(float)* Width * Width);
N = (float*)malloc(sizeof(float)* Width * Width);
Pc = (float*)malloc(sizeof(float)* Width * Width); //保存CPU计算结果
srand(0);
matgen(M, Width); //产生矩阵M
matgen(N, Width); //产生矩阵N
double timeStart, timeEnd; //定义时间,求时间差用
timeStart = clock();
MatrixMultiplication(M, N, Pc, Width); //CPU上计算
timeEnd = clock();
free(M);
free(N);
free(Pc);
return timeEnd - timeStart;
}
//
int main()
{
printf("CPU use time %g\n", MatrixMul_CPU());
printf("GPU use time %g\n", MatrixMul_GPU());
system("pause");
return 0;
}
CUDAtest.cu
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#define TILE_WIDTH 16
// 核函数
// __global__ static void MatrixMulKernel(const float* Md,const float* Nd,float* Pd,int Width)
__global__ void MatrixMulKernel(const float* Md, const float* Nd, float* Pd, int Width)
{
//计算Pd和Md中元素的行索引
int Row = blockIdx.y * TILE_WIDTH + threadIdx.y; //行
int Col = blockIdx.x * TILE_WIDTH + threadIdx.x; //列
float Pvalue = 0.0;
for (int k = 0; k < Width; k++)
{
Pvalue += Md[Row * Width + k] * Nd[k * Width + Col];
}
//每个线程负责计算P中的一个元素
Pd[Row * Width + Col] = Pvalue;
}
// 矩阵乘法(CUDA中)
// 在外部调用,使用extern
extern "C" void MatrixMultiplication_CUDA(const float* M, const float* N, float* P, int Width)
{
cudaSetDevice(0); //设置目标GPU
float *Md, *Nd, *Pd;
int size = Width * Width * sizeof(float);//字节长度
cudaMalloc((void**)&Md, size);
cudaMalloc((void**)&Nd, size);
cudaMalloc((void**)&Pd, size);
//Copies a matrix from the memory* area pointed to by src to the memory area pointed to by dst
cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice);
cudaMemcpy(Nd, N, size, cudaMemcpyHostToDevice);
//
dim3 dimGrid(Width / TILE_WIDTH, Width / TILE_WIDTH); //网格的维度
dim3 dimBlock(TILE_WIDTH, TILE_WIDTH); //块的维度
MatrixMulKernel <<< dimGrid, dimBlock >>>(Md, Nd, Pd, Width);
cudaMemcpy(P, Pd, size, cudaMemcpyDeviceToHost);
//释放设备上的矩阵
cudaFree(Md);
cudaFree(Nd);
cudaFree(Pd);
}接下来就是第三方库的链接了,首先呢,你得右击项目,打开项目属性
分别在可执行文件目录下输入:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\bin
在包含目录下输入:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\include
在库目录下输入:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\lib\Win32

之后在链接器/输入/附加依赖项中输入:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\lib\Win32目录下的所有lib文件的文件名
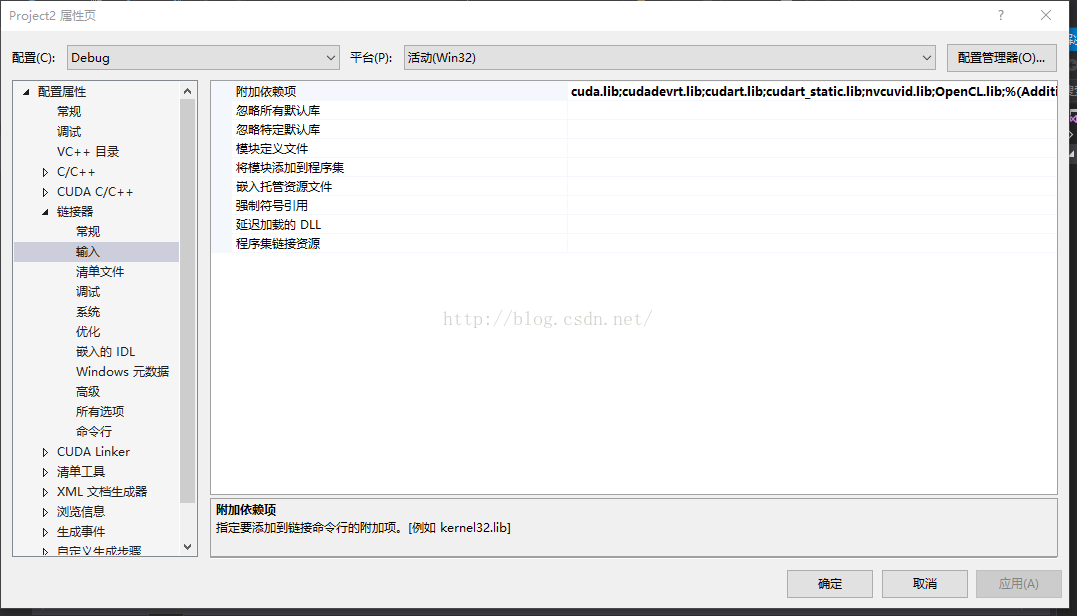
这时,如果你急于立马编译的话,你就会发现报错了:大致的意思是extern修饰的函数被应用,无法解析的外部命令
因为这时其实编译器没有编译cu文件,所以cpp文件中无法引用cu文件里的函数。
最关键的一步来了:
右击项目,点击生成依赖 项,选择“生成自定义”,然后勾选cuda
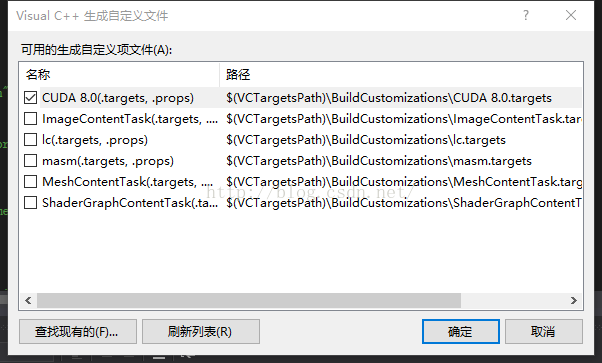
之后右击test.cu文件打开属性,修改“项目类型”如下:
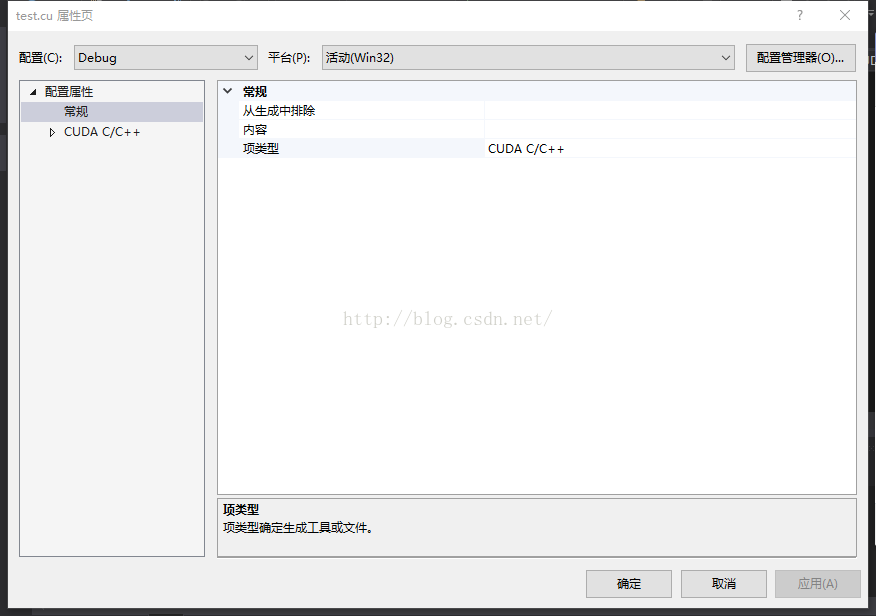
大功告成,愉快的调试吧

















 916
916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









