







 本文分析了车辆分析的关键需求,包括车辆轨迹查询、地理位置检索、多维碰撞查询等,并对Hadoop、Spark、Storm、Solr等大数据技术在车辆缉查布控系统的优缺点进行了比较。最终提出延云YDB的混合方案,通过整合多个系统的优势,实现高效稳定的车辆数据分析能力。
本文分析了车辆分析的关键需求,包括车辆轨迹查询、地理位置检索、多维碰撞查询等,并对Hadoop、Spark、Storm、Solr等大数据技术在车辆缉查布控系统的优缺点进行了比较。最终提出延云YDB的混合方案,通过整合多个系统的优势,实现高效稳定的车辆数据分析能力。
自2012年以来,公安部交通管理局在全国范围内推广了机动车缉查布控系统(简称卡口系统),通过整合共享各地车辆智能监测记录等信息资源,建立了横向联网、纵向贯通的全国机动车缉查布控系统,实现了大范围车辆缉查布控和预警拦截、车辆轨迹、交通流量分析研判、重点车辆布控、交通违法行为甄别查处及侦破涉车案件等应用。在侦破肇事逃逸案件、查处涉车违法行为、治安防控以及反恐维稳等方面发挥着重要作用。
随着联网单位和接入卡口的不断增加,各省市区部署的机动车缉查布控系统积聚了海量的过车数据。截至目前,全国32个省(区、市)已完成缉查布控系统联网工作,接入卡口超过50000个,汇聚机动车通行数据总条数超过2000亿条。以一个中等规模省市为例,每地市每日采集过车信息300万条,每年采集过车信息10亿条,全省每年将汇聚超过200亿条过车信息。如何将如此海量的数据管好、用好成为各省市所面临的巨大挑战。
随着车辆网以及汽车卡口应用的不断扩大,车辆数据的不断积累。对于原始数据的存储、处理、查询是一个很大的考验,为此我们需要一个能实时处理、多维度查询的分布式计算的平台。
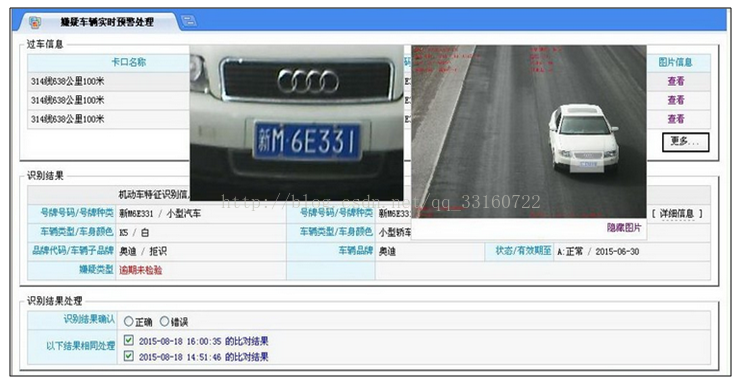
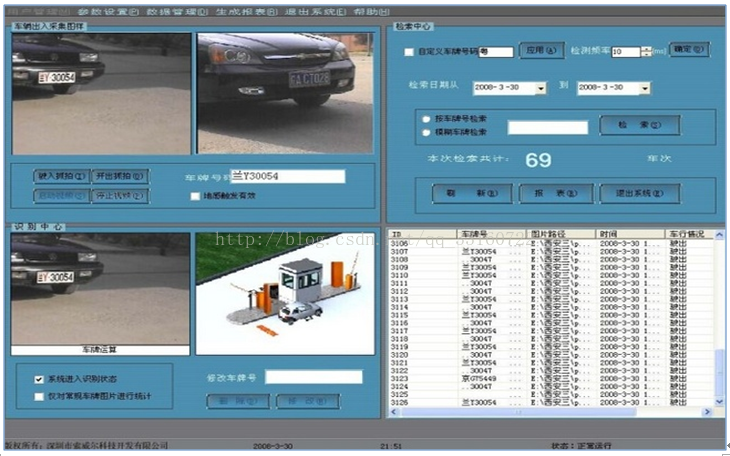
一、 关键需求分解
1. 车辆轨迹查询
能够根据输入的车牌号,或通过车牌号模糊查询对车辆进行状态查询、订单轨迹追踪。过车记录查询,过车轨迹查询,落脚点分析,进行轨迹回放。
2. 地理位置检索
能够根据经纬度坐标快速的进行经纬度的过滤,如指定一个坐标,快速圈定周边10公里内的车辆。
3. 多维碰撞, 多维度查询
要求可以有5个条件的维度查询,最常用的是时间,终端号,类型。
可以根据多个维度进行任意条件的组合过滤,进行数据碰撞。
也可以根据多个地理坐标进行车辆碰撞分析。
4. 车辆出行规律分析,
可以按照一辆车,或一批车辆进行统计分析,了解车辆的出行规律,出行时间,频繁出入地点。
5. 出行规律异常车辆分析
选定某一区域的,周边陌生人/车的识别。出行规律异常的人/车识别。
6. 伴随分析
人车轨迹拟合,判断是否有代驾行为,有尾随,盯梢识别。
7. 数据碰撞分析
能够根据根据多个地理位置以及时间进行数据碰撞,连环时间进行数据碰撞分析。
8. 重点车辆分析
根据统计一定区域范围内的客运、危险品运输、特殊车辆等重点车辆通行数量,研判发现通行规律。对在路段内行驶时间异常的车辆、首次在本路段行驶的重点车辆、2到5点仍在道路上行驶的客运车辆等进行预警提示。
9. 车辆出入统计分析
挖掘统计一段时间内在某一个区域内(可设定中心城区、地市区域、省市区域、高速公路等区域)、进出区域、主要干道的经常行驶车辆、“候鸟”车辆、过路车辆的数量以及按车辆类型、车辆发证地的分类统计。
二、 关键技术能力要求
1. 数据规模-数据节点数
能够承载日均数百亿条增量,数据要可以长久保留
也要支撑未来三到五年,每天百亿,甚至数千亿条数据增量。
每个数据节点每天能处理20亿的数据量。
2. 查询与统计功能灵活性
根据不同的厂商,车型,往往在逻辑上有较大的区别,他们业务的不同查询逻辑也会有较大的区别,故一个查询系统要求非常灵活,可以处理复杂的业务逻辑,算法,而不是一些常规的简单的统计。
能支持复杂SQL
当业务满足不了需求的时候可以拓展SQL,自定义开发新的逻辑,udf,udaf,udtf。
要能支持模糊检索
对于邮箱、手机号、车牌号码、网址、IP地址、程序类名、含有字母与数字的组合之类的数据会匹配不完整,导致数据查不全,因分词导致漏查以及缺失数据,对于模糊检索有精确匹配要求的场景下,业务存在较大的风险
多维分析多维碰撞
要求可以有5个条件的维度查询,最常用的是时间,终端号,类型。
3. 检索与并发性能
每次查询在返回100条以内的数据时能在1秒内返回,并发数不少于200(6个节点以内)。对于并发数要做到随着节点数的增加可以按比例增加。
4. 数据导入与时效性
对数据时效性要求较高,要求某一车辆在经过产生数据后,可达到分钟级别内系统可查可分析。对检索性能要求很高,以上典型需求均要求能够在秒级内返回结果及明细。
采用SQL方式的批量导入,也要支持kafka的流式导入
5. 稳定性-与单点故障
易于部署,易于扩容,易于数据迁移;
多数据副本保护,硬件不怕硬件损坏;
服务异常能自动检测及恢复,减轻运维人员经常需要半夜起床的痛苦;
系统不能存在任何单点故障,当某个服务器存在问题时不能影响线上业务。
数据过百亿后,不能频繁的OOM,也不能出现节点调片的情况。
系统出现异常后,可以自动侦探服务异常,并自动重启恢复服务,不能每次调片都要运维 人员半夜去机房重启。需要服务有自动迁移与恢复的特性,大幅减少运维人员驻场的工作量。
提供了导入与查询的限流控制,也提供了过载保护控制,甚至在极端场景提供了有损查询与有损服务
6. 要有较高的排序性能
排序可以说是很多日志系统的硬指标(如按照时间逆序排序),如果一个大数据系统不能进行排序,基本上是这个系统属于不可用状态,排序算得上是大数据系统的一个“刚需”,无论大数据采用的是hadoop,还是spark,还是impala,hive,总之排序是必不可少的,排序的性能测试也是必不可少的。
7. 用户接口
尽量是SQL接口。如果是程序接口学习成本与接入成本均较高。
8. 方便与周边系统的导入导出
能与现有的常见系统如hadoop,hive ,传统数据库,kafka等集成,方便数据导入导出。
支持原始数据的任意维度导出
可以全表,也可以通过过滤筛选局部导出
支持数据经过各种组合计算过滤后的导出
可以将Y多个表与其他系统的多个表,进行组合筛选过滤计算后在导出
可以将多个数据从一张表导入到、另外一张表
可以将数据导出到别的系统里面(如hive,hbase,数据库等)
也可以将其他系统的数据导入到当前系统里面。
可以导出成文件,也可以从文件导入。
可以从kafka流式导入,也可以写插件,导出到kafka。
9. 数据存储与恢复
数据不能存储在本地磁盘,迁移难,恢复也难。
1).磁盘读写没有很好的控速机制,导入数据没有良好的流量控制机制,无法控制流量,而生产系统,磁盘控速与流量控速是必须的,不能因为业务高峰对系统造成较大的冲击,导致磁盘都hang住或挂掉。
2).本地硬盘局部坏点,造成局部数据损坏对于系统来说可能无法识别,但是对于索引来说哪怕是仅仅一个byte数据的读异常,就会造成索引指针的错乱,导致检索结果数据丢失,甚至整个索引废掉,但是本地磁盘不能及时的发现并修正这些错误。
3).数据存储在本地磁盘,一旦本地将近20T的存储盘损坏,需要从副本恢复后才能继续服务,恢复时间太长。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 7847
7847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









