







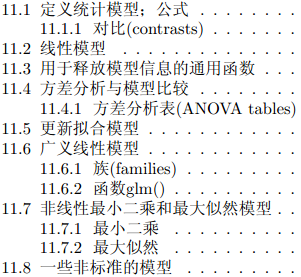
1定义统计模型的公式
下面统计模型的模板是一个基于独立的方差齐性数据的线性模型
其中y是响应向量,X是模型矩阵(model matrix)或者设计矩阵(design ma-
trix)。X的列 是决定变量(determining variable)。通常,列都是1,用来定义截距(intercept)项。
在给予正式的定义前,举一些的例子可能更容易了解全貌。
假定y,x,x0,x1,x2,...是数值变量,X是一个矩阵,而A,B,C,...是因子。下
面的例子中,左边给出公式,右边给出该公式的统计模型的描述。
y~x
y~1+x
二者都反映了y对x的简单线性模型。第一个公式包含了一个隐式的截距项,而第二个则是一个显式的截距项。
y~0+x
y~-1+x
y~x-1
log(y)~x1+x2
y~poly(x,2)
y~1+x+I(x^2)
y~X+poly(x,2)
y~A
y~A+x
y~A*B
y~A+B+A:B
y~B%in%A
y~A/B
y~(A+B+C)^2
y~A*B*C-A:B:C
y~A*x
y~A/x
y~A/(1+x)-1
y~A*B+Error(C)
操作符~用来定义R的模型公式(model formula)。一个普通的线性模型式可以表示为
response~op 1 term 1 op 2 term 2 op 3 term 3...
其中response是一个作为响应变量的向量或者矩阵,或者是一个值为向量/矩阵的表达式。op i是一个操作符。它要么是+要么是-,分别表示在一个模型中加入或者去掉某一项(公式第一项的操作符可选)。term i可以(1)是一个向量,矩阵表达式或者1,(2)因子,(3)是一个由因子,向量或矩阵通过公式操作符连接产生的公式表达式(formula expression)。
基本上,公式中的项决定了模型矩阵中的列要么被加入要么被去除。1表示截距项,并且默认就已加入模型矩阵,除非显式地去除这一选项。
公式操作符(formula operators)在效果上和用于程序Glim和Genstat中的Wilkinson&Rogers标记符(notation)相似。一个不可避免的改变是操作符.在R里面变成了:,因为点号在R里面是合法的命名字符。
这些符号总结如下(参考Chambers&Hastie,1992,p.29):
Y~M
M 1+M 2
M 1-M 2
M 1:M 2
M 1%in%M 2
M 1*M 2
M 1/M 2
M^n
I(M)
注意,在常常用来封装函数参数的括弧中的操作符按普通的四则运算法则解
释。I()是一个恒等函数(identity function),它使得常规的算术运算符可以用在模型公式中。还要特别注意模型公式仅仅指定了模型矩阵的列项,暗含了对参数项的指定。在某些情况下可能不是这样,如非线性模型的参数指定。
1对照
我们至少要知道模型公式是如何指定模型矩阵的列项的。对于连续变量这是比较简单的,因为每一个变量对应于模型矩阵的一个列(如果模型中包含截距,会在矩阵中列出值都是1的一列)。
对于一个k-水平的因子A该如何处理呢?无序和有序因子给出的结论是不一样的。对于无序因子,因子第2,...,第k不同水平的指标产生k?1列。(因此隐含的参数设置就是把其他水平和第一个水平的响应程度进行比较)。对于有序因子,k-1列是在1,...,k上的正交项(orthogonal polynomial),并且忽略常数项。
尽管这里的回答有点复杂,但这不是事情的全部。首先在含有一个因子项的模型中忽略截距项,这一项将会被编入指示所有因子水平的k列中。其次整个行为可以通过options设置参数contrasts而改变。R的默认设置为
options(contrasts=c("contr.treatment","contr.poly"))
提这些内容的主要原因是R和S对无序因子采用不同的默认值。S采用Helmert对照。因此,当你需要比较你的结果和某本书上或论文上用SPLUS代码的结果时,你必须设置
options(contrasts=c("contr.helmert","contr.poly"))
这是一个经过认真考虑的改变。因为处理对照(treatment contrast)(R默认)对于新手是比较容易理解的。
这还没有结束,因为在各个模型的各个项中对照方式可以用函数contrasts和C重新设置。
我们还没有考虑交互作用项:这些交互作用项将会产生各分量项的乘积。
尽管细节是复杂的,R里面的模型公式在要求不是太离谱的情况下可以产生统计专家所期望的各种模型。提供模型公式的各种扩展特性是让R更灵活。例如,利用关联项而非主要效应的模型拟合常常会产生令人惊讶的结果,不过这些仅仅为统计专家们设计的。
2线性模型
对于常规的多重模型(multiple model)拟合,最基本的函数是lm()。下面是调
用它的方式的一种改进版:
>fitted.model<-lm(formula,data=data.frame)
例如
>fm2<-lm(y~x1+x2,data=production)
将会拟合y对x1和x2的多重回归模型(和一个隐式的截距项)。
一个重要的(技术上可选)参数是data=production。它指定任何构建这个模型的变量首先必须来自数据框production。这里不需要考虑数据框production是否被绑定在搜索路径中。
3提取模型信息的泛型函数
lm()的返回值是一个模型拟合结果对象;技术上就是属于类"lm"的一个结果列表。关于拟合模型的信息可以用适合对象类"lm"的泛型函数显示,提取,图示等等。这包括
add1 coef effects kappa predict residuals
alias deviance family labels print step
anova drop1 formula plot proj summary
其中一些常用的泛型函数可以简洁描述如下。
anova(object 1,object 2)
coef(object)
deviance(object)
formula(object)
plot(object)
predict(object,newdata=data.frame)提供的数据框必须有同原始变量一样标签的变量。结果是对应于data.frame中决定变量预测值的向量或矩阵。
predict.gam(object,
newdata=data.frame)
print(object)
residuals(object)
step(object)
summary(object)
4方差分析和模型比较
aov(formula,data=data.frame)和函数lm()非常的相似,在泛型函数提取模型信息部分列出的泛型函数同样适用。
需要注意的是aov()还允许分析多误差层次(multiple error strata)的模型,如
裂区实验设计(split plot experiments),利用区组内信息进行的平衡不完全区组设
计(balanced incomplete block design)等。模型公式
response mean.formula+Error(strata.formula)
指定了一个多层次实验设计,误差层由strata.formula定义。最简单的情况是,strata.formula是单因素的。它定义了一个双层次的实验,也就是研究在这些因子的水平内或者水平间的实验响应。
例如,已知所有的决定变量因子,模型公式可以设计如下:
>fm<-aov(yield~v+n*p*k+Error(farms/blocks),data=farm.data)
这常常用来描述一个同时含有均值模型v+n*p*k和三个误差层次(“农田之间”,“农田内但在区组之间”和“区组内”)的实验。
方差表的分析实际上是为拟合模型序列(sequence)进行的。在模型序列的特定地方增加特定的项会使残差平方和降低。因此仅仅在正交实验中,模型中增加项的次序是没有影响的。
在多层实验设计(multistratum experiments)中,程序首先把响应值依次投射到各个误差层次上,并且用均值模型去拟合各个投射。细节内容可以参考Chambers&Hastie(1992)。
除了使用常规的方差分析表(ANOVA table),你还可以直接用函数anova()来比较两个模型。这种方法更为灵活。
>anova(fitted.model.1,fitted.model.2,...)
结果将是一个方差分析表以显示依次加入的拟合模型的差异。需要比较的拟合模
型常常是等级序列(hierarchical sequence)。这个和默认的设置实际上没有差别,只是使它更容易理解和控制。
5更新拟合模型
函数update()是一个非常便利的函数。它允许拟合一个比原先模型增加或减少一个项的模型。它的形式是
>new.model<-update(old.model,new.formula)
在new.formula中,公式中包含的句点,.,仅仅表示“旧的公式模型中的对应部
分”。例如
>fm05<-lm(y~x1+x2+x3+x4+x5,data=production)
>fm6<-update(fm05,.~.+x6)
>smf6<-update(fm6,sqrt(.)~.)
这将分别拟合从数据框production中得到的五个变量的多重回归模型,拟合额外增加一个变量的六个回归量的模型,和进一步对响应值进行平方根变换后的模型拟合。
注意参数data=在最开始调用模型拟合函数的时候指定。这个信息将会通过拟合模型对象传递给函数update()及其相关者。
符号.同样可以用在其他情况下,不过含义有点不同。如
>fmfull<-lm(y~.,data=production)
它将会拟合响应量y对数据框production中所有变量回归的模型。
其他研究逐步回归的函数是add1(),drop1()和step()。从字面上就可以看出这些函数的意义,更细节的内容可以参考在线帮助文档。
6广义线性模型
广义线性建模是线性建模的一种发展,它通过一种简洁而又直接的方式使得线性模型既适合非正态分布的响应值又可以进行线性变换。广义线性模型是基于下面一系列假设前提的:
(1)有一个有意思的响应变量y和一系列刺激变量(stimulus variable)x1,x2,...。
这些刺激变量决定响应变量的最终分布。
(2)刺激变量仅仅通过一个线性函数影响响应值y的分布。该线性函数称为线性预测器(linear predictor),常常写成
η=β1x1+β2x2+···+βpxp,
因此xi当且仅当βi=0时对y的分布没有影响。
(3)y分布的形式为
其中 是尺度参数(scale parameter)(可能已知),对所有观测恒定,A是一个先验的权重,假定知道但可能随观测不同有所不同,μ是y的均值。也就是说假定y的分布是由均值和一个可能的尺度参数决定的。
(4)均值μ是线性预测器的平滑可逆函数(smooth invertible function):
μ=m(η),η=m-1(μ)=l(μ)
其中的反函数(inverse function)l()被称为关联函数(link function)。
这些假定比较宽松,足以包括统计实践中大多数有用的统计模型,同时也足够严谨,使得可以发展参数估计和统计推论(estimation and inference)中一致的方法(至少可以近似一致)。读者如果想了解这方面最新的进展,可以参考McCullagh&Nelder(1989)或者Dobson(1990)。
6.1族
R提供了一系列广义线性建模工具,从类型上来说包括高斯(gaussian),二项式,泊松(poisson),逆高斯(inverse gaussian)和伽马(gamma)模型的响应变量分布以及响应变量分布无须明确给定的拟似然(quasi-likelihood)模型。在后者,方差函数(variance function)可以由均值的函数指定,但在其它情况下,该函数可以由响应变量的分布得到。每一种响应分布允许各种关联函数将均值和线性预测器关联起来。这些自动可用的关联函数如下表所示:
族名字
Binomial
Gaussian
Gamma
inverse.aussian
poisson
quasi
inverse,log,1/mu^2,sqrt
这些用于模型构建过程中的响应分布,关联函数和各种其他必要的信息统称为广义线性模型的族(family)。
6.2 glm()函数
既然响应的分布仅仅通过单一的一个线性函数依赖于刺激变量,那么用于线性模型的机制同样可以用于指定一个广义模型的线性部分。但是族必须以一种不同的方式指定。
R用于广义线性回归的函数是glm(),它的使用形式为
>fitted.model<-glm(formula,family=family.generator,data=data.frame)
和lm()相比,唯一的一个新特性就是描述族的参数family.generator。它其实是一个函数的名字,这个函数将产生一个函数和表达式列表用于定义和控制模型的构建与估计过程。尽管这些内容开始看起来有点复杂,但它们非常容易使用。
这些名字是标准的。程序给定的族生成器可以参见族部分表格中的“族名”。当选择一个关联函数时,该关联函数名和族名可以同时在括弧里面作为参数设定。在拟(quasi)家族里面,方差函数也是以这种方式设定。
一些例子可能会使这个过程更清楚。
gaussian族
命令
>fm<-glm(y~x1+x2,family=gaussian,data=sales)
和下面的命令结果一致
>fm<-lm(y~x1+x2,data=sales)
但是效率上,前者差一点。注意,高斯族没有自动提供关联函数设定的选项,因此不允许设置参数。如一个问题需要用非标准关联函数的高斯族,那么只能采用我们后面讨论的拟族。
二项式族
考虑Silvey(1970)提供的一个人造的小例子。
在Kalythos的Aegean岛上,男性居民常常患有一种先天的眼科疾病,并且随着年龄的增长而变的愈明显。现在搜集了各种年龄段岛上男性居民的样本,同时记录了盲眼的数目。数据展示如下:
Age:20 35 45 55 70
No.:tested:50 50 50 50 50
No.:blind:6 17 26 37 44
我们想知道的是这些数据是否吻合logistic和probit模型,并且分别估计各个模型的LD50,也就是一个男性居民盲眼的概率为50%时候的年龄。
如果y和n分别是年龄为x时的盲眼数目和检测样本数目,两种模型的形式都为
y~B(n,F(β0+β1x))
其中在probit模型中,F(z)=Φ(z)是标准的正态分布函数,而在logit模型(默认)中,F(z)=ez/(1+ez)。这两种模型中,
LD50=-β0/β1
,即分布函数的参数为0时所在的点。
第一步是把数据转换成数据框,
>kalythos<-data.frame(x=c(20,35,45,55,70),n=rep(50,5),y=c(6,17,26,37,44))
在glm()拟合二项式模型时,响应变量有三种可能性:
(1)如果响应变量是向量,则假定操作二元(binary)数据,因此要求是0/1向量。
(2)如果响应变量是双列矩阵,则假定第一列为试验成功的次数第二列为试验失败
的次数。
(3)如果响应变量是因子,则第一水平作为失败(0)考虑而其他的作为‘成功’(1)考虑。
这里,我们采用的是第二种惯例。我们在数据框中增加了一个矩阵:
>kalythos$Ymat<-cbind(kalythos$y,kalythos$n-kalythos$y)
为了拟合这些模型,我们采用
>fmp<-glm(Ymat~x,family=binomial(link=probit),data= kalythos)
>fml<-glm(Ymat~x,family=binomial,data=kalythos)
既然logit的关联函数是默认的,因此我们可以在第二条命令中省看拟合结果,我们使用
>summary(fmp)
>summary(fml)
两种模型都拟合的很好。为了计算LD50,我们可以利用一个简单
>ld50<-function(b)-b[1]/b[2]
>ldp<-ld50(coef(fmp));ldl<-ld50(coef(fml));c(ldp,ldl)
从这些数据中得到的年龄分别是43.663年和43.601年。
Poisson模型
Poisson族默认的关联函数是log。在实际操作中,这一族常常用于拟合计数资料的Poisson对数线性模型。这些计数资料的实际分布往往符合二项式分布。这是一个非常重要而又庞大的话题,我们不想在这里深入展开。它甚至是非-高斯广义模型内容的主要部分。
有时候,实践中产生的Poisson数据在对数或者平方根转化后可当作正态数据处理。作为后者的另一种选择是,一个Poisson广义线性模型可以通过下面的方式拟合:
>fmod<-glm(y~A+B+x,family=poisson(link=sqrt),data=worm.counts)
拟似然模型
对于所有的族,响应变量的方差依赖于均值并且拥有作为乘数(multiplier)的尺度参数。方差对均值的依赖方式是响应分布的一个特性;例如对于poisson分布Var[y]=μ。
对于拟似然估计和推断,我们不是设定精确的响应分布而是设定关联函数和方差函数的形式,因为关联函数和方差函数都依赖于均值。既然拟似然估计和gaussian分布使用的技术非常相似,因此这一族顺带提供了一种用非标准关联函数或者方差函数拟合gaussian模型的方法。
例如,考虑非线性回归的拟合
y=θ1z1/(z2-θ2)+e
同样还可以写成
y=1/(β1x1+β2x2)+e
其中x1=z2/z1,x2=-1/x1, β1=1/θ1 andβ2=θ2/θ1。假如有适合的数据框,我们可以如下进行非线性拟合
>nlfit<-glm(y~x1+x2-1,
family=quasi(link=inverse,variance=constant),
data=biochem)
如果需要的话,读者可以从其他手册或者帮助文档中得到更多的信息。
7非线性最小二乘法和最大似然法模型
特定形式的非线性模型可以通过广义线性模型(glm())拟合。但是许多时候,我们必须把非线性拟合的问题作为一个非线性优化的问题解决。R的非线性优化程序是optim(),nlm()和nlminb()(自R2.2.0开始)。二者分别替换SPLUS的ms()和nlminb()但功能更强。我们通过搜寻参数值使得缺乏度(lack-of-fit)指标最低,如nlm()就是通过循环调试各种参数值得到最优值。和线性回归不同,程序不一定会收敛到一个稳定值。nlm()需要设定参数搜索的初始值,而参数估计是否收敛在很大程度上依赖于初始值设置的质量。
7.1最小二乘法
拟合非线性模型的一种办法就是使误差平方和(SSE)或残差平方和最小。如果观测到的误差极似正态分布,这种方法是非常有效的。
下面是例子来自Bates&Watts(1988),51页。具体数据是:
>x<-c(0.02,0.02,0.06,0.06,0.11,0.11,0.22,0.22,0.56,0.56,1.10,1.10)
>y<-c(76,47,97,107,123,139,159,152,191,201,207,200)
被拟合的模型是:
>fn<-function(p)sum((y-(p[1]*x)/(p[2]+x))^2)
为了进行拟合,我们需要估计参数初始值。一种寻找合理初始值的办法把数据图形化,然后估计一些参数值,并且利用这些值初步添加模型曲线。
>plot(x,y)
>xfit<-seq(.02,1.1,.05)
>yfit<-200*xfit/(0.1+xfit)
>lines(spline(xfit,yfit))
当然,我们可以做的更好,但是初始值200和0.1应该足够了。现在做拟合:
>out<-nlm(fn,p=c(200,0.1),hessian=TRUE)
拟合后,out$minimum是误差的平方和(SSE),out$estimate是参数的最小二乘估计值。为了得到参数估计过程中近似的标准误(SE),我们可以:
>sqrt(diag(2*out$minimum/(length(y)-2)*solve(out$hessian)))
上述命令中的2表示参数的个数。一个95%的信度区间可以通过±1.96 SE计算得到。我们可以把这个最小二乘拟合曲线画在一个新的图上:
>plot(x,y)
>xfit<-seq(.02,1.1,.05)
>yfit<-212.68384222*xfit/(0.06412146+xfit)
>lines(spline(xfit,yfit))
标准包stats提供了许多用最小二乘法拟合非线性模型的扩充工具。我们刚刚拟合过的模型是Michaelis-Menten模型,因此可以利用下面的命令得到类似的结论。
>df<-data.frame(x=x,y=y)
>fit<-nls(y~SSmicmen(x,Vm,K),df)
>fit
Nonlinear regression model
model:
data:
Vm
212.68370711
residual sum-of-squares:
>summary(fit)
Formula:
Parameters:
Estimate
Vm
K
Residual standard error: 10.93 on 10 degrees of freedom
Correlation of Parameter Estimates:
Vm
K 0.7651
7.2最大似然法
最大似然法(Maximum likelihood)也是一种非线性拟合方法。它甚至可以用在误差非正态的数据中。这种方法估计的参数将会使得对数似然值最大或者负的对数似然值最小。下面的例子来自Dobson(1990),pp.:108–111。这个例子对剂量-响应数据拟合logistic模型(当然也可以用glm()拟合)。数据是:
>x<-c(1.6907,1.7242,1.7552,1.7842,1.8113,1.8369,1.8610,1.8839)
>y<-c(6,13,18,28,52,53,61,60)
>n<-c(59,60,62,56,63,59,62,60)
要使负对数似然值最小,则:
>fn<-function(p)
sum(-(y*(p[1]+p[2]*x)-n*log(1+exp(p[1]+p[2]*x))+log(choose(n,y))))
我们选择一个适当的初始值,开始拟合:
>out<-nlm(fn,p=c(-50,20),hessian=TRUE)
拟合后,out$minimum就是负对数似然值,out$estimate就是最大似然拟合的参数值。为了得到拟合过程近似的标准误,我们可以:
>sqrt(diag(solve(out$hessian)))
参数估计的95%信度期间可由估计值±1.96 SE计算得到。
8一些非标准模型
我们简单提一下R里面某些用于某些特殊回归和数据分析问题的工具。
(1)混合模型(Mixed models)。用户捐献包nlme里面提供了函数lme()和nlme()。这些函数可以用于混合效应模型(mixed-effects models)的线性和非线性回归。也就是说在线性和非线性回归中,一些系数受随机因素的影响。这些函数
需要充分利用公式来描述模型。
(2)局部近似回归(Local approximating regressions)。函数loess()利用局部加权回归进行一个非参数回归。这种回归对显示一组凌乱数据的趋势和描述大数据集的整体情况非常有用。函数loess和投影跟踪回归(projection pursuit regression)的代码一起放在标准包stats中。
(3)稳健回归(Robust regression)。有多个函数可以用于拟合回归模型,同时尽量不受数据中极端值的影响。在推荐包MASS中的函数lqs为高稳健性的拟合提供了最新的算法。另外,稳健性较低但统计学上高效的方法同样可以在包MASS中得到,如函数rlm。
(4)累加模型(Additive models)。这种技术期望可以通过决定变量的平滑累加函数(smooth additive function)构建回归函数。一般来说,每个决定变量都有一个平滑累加函数。用户捐献的包acepack里面的函数avas和ace以及包mda里面的函数bruto和mars为这种技术提供了一些例子。这种技术的一个扩充是用户捐献包gam和mgcv里面实现的广义累加模型。
(5)树型模型(Tree-based models)。除了利用外在的全局线性模型预测和解释数据,还可以利用树型模型递归地在决定性变量的判断点上将数据的分叉分开。这样做会把数据最终分成几个不同组,使得组内尽可能相似而组间尽可能差异。这样常常会得到一些其他数据分析方法不能产生的的信息。模型可以用一般的线性模型形式指定。该模型拟合函数是tree(),而且许多泛型函数,如plot()和text()都可以很好的用于树型模型拟合结果的图形显示。R里面的树型模型函数可以通过用户捐献的包rpart和tree得到。














 554
554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









