







有a,b,c,d四个人,现在有X,Y,Z三个不规则酒杯,X,Y容量为8两,现在已装满酒,Z容量为3两,为空杯.现在要求四个人每人都能平均喝到4两酒,请说出该怎么喝?写出算法,并打印出每步X,Y,Z杯内的酒多少和四个人每人所喝的酒?
这道题的来源不可考。在网上搜《编程之美》烙饼问题的相关资料的时候看到了这道题,之前没接触过算法,手算想了一会儿居然没有算出来~ 想了大概一天的时间,终于把代码搞定了。
想了大概一天的时间,终于把代码搞定了。
此题类似于《编程之美》中烙饼问题所采用的剪枝+分支定界,关键是对问题过程的处理。只要把问题过程理清,找好边界条件和退出条件,问题自然迎刃而解。我们先找边界条件,显然
a)每个人都喝到4两酒肯定是程序执行完成的条件,
b)为了避免重复进入之前某种状态,我们需要判断当前状态是否出现过。
再明确我们倒酒的过程,这里只需要弄清可以倒酒的状态分类。首先,对X、Y、Z三个酒杯的状态和a、b、c、d四个人喝酒的状态要区别对待:
a)当且仅当某人当前的酒量和酒杯中酒量之和小于等于4,此人才能喝酒。显然,这才是最终可以满足边界条件a的过程
b)在三个酒杯之间互相倒酒,要注意每个酒杯都不能溢出
c)如果此状态之前出现过,说明这种状态之下走不通,就没有必要在此状态之下继续进行。另外,X和Y酒杯由于容量一样,在其他状态相同的情况下,可视为相同的状态。
理解了这些,写出代码就比较容易。
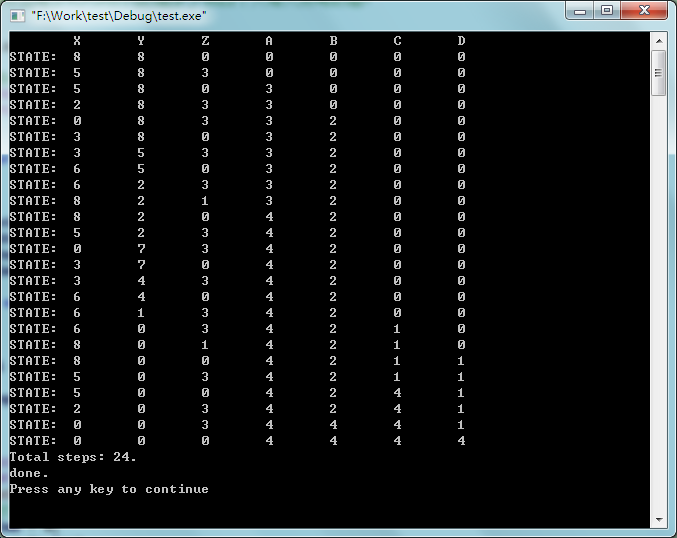
/* 有a,b,c,d四个人,现在有X,Y,Z三个不规则酒杯,X,Y容量为8两,现在已装满酒,
* Z容量为3两,为空杯.现在要求四个人每人都能平均喝到4两酒,请说出该怎么喝?
* 写出算法,并打印出每步X,Y,Z杯内的酒多少和四个人每人所喝的酒?
*/
#include <stdio.h>
/* 递归调用退出条件:每人都喝到4两,或者回到中间的某个状态 */
#define MAX_STATES 1024 /* 保存中间状态,如果是之前的某个状态就退出 */
#define MAX_STEPS 100 /* 保存最终采用的步骤 */
typedef struct
{
unsigned char StateArray[7]; /* StateArray 0~2 represent X, Y, Z;
3~6 represent A, B, C, D*/
}STATE;
static int StateIndex;
static int PourStepState[MAX_STATES]; /* 类似于栈结构,中间状态 */
static int MaxSteps;
static STATE PrintStepIndex[MAX_STEPS]; /* 最终采用的状态 */
static __inline void PrintPourSteps(STATE TempState)
{
int i;
++MaxSteps;
for(i = 0; i < 7; i++)
{
PrintStepIndex[MaxSteps].StateArray[i] = TempState.StateArray[i];
}
}
#define STATE_EXIST 1
#define STATE_NOT_EXIST 0
static int CheckState(STATE TempState)
{ /* 检查当前状态,如果是之前的状态则直接返回,否则保存当前状态 */
int i, TempSum = 0;
for(i = 0; i < 7; i++)
{
TempSum = TempSum * 10 + TempState.StateArray[i];
}
for(i = StateIndex; i > 0; i--)
{
if(TempSum == PourStepState[i])
return STATE_EXIST;
if(TempState.StateArray[0] == (PourStepState[i]/100000)%10 &&
TempState.StateArray[1] == PourStepState[i]/1000000 &&
TempSum%100000 == PourStepState[i]%100000)
{ /* 对X和Y的状态不做区分 */
return STATE_EXIST;
}
}
PourStepState[++StateIndex] = TempSum;
return STATE_NOT_EXIST;
}
static __inline void PourStepNext(STATE *TempState, STATE *PreState)
{
int i;
for(i = 0; i < 7; i++)
{
TempState->StateArray[i] = PreState->StateArray[i];
}
return;
}
#define POUR_SUCCEED 1
#define POUR_FAIL 0
/* 分清处理步骤,注意顺序先尝试X,Y,Z向A,B,C,D中倒,然后进行
* X,Y,Z之间的处理,否则容易出现死循环或者中间过程过度展开
*/
int DoPouring(STATE PreState)
{
int i, j;
STATE TempState;
for(i = 0; i <= 2; i++)
{
for(j = 3; j < 7; j++)
{
if(PreState.StateArray[i] + PreState.StateArray[j] <= 4 && PreState.StateArray[i])
{
PourStepNext(&TempState, &PreState);
TempState.StateArray[j] += TempState.StateArray[i];
TempState.StateArray[i] = 0;
if(TempState.StateArray[3] == 4 && TempState.StateArray[4] == 4 &&
TempState.StateArray[5] == 4 && TempState.StateArray[6] == 4)
{
PrintPourSteps(TempState);
return POUR_SUCCEED;
}
if(CheckState(TempState) == STATE_NOT_EXIST)
{
if(DoPouring(TempState) == POUR_SUCCEED)
{
PrintPourSteps(TempState);
return POUR_SUCCEED;
}
}
}
}
}
if(PreState.StateArray[1] < 8 && PreState.StateArray[0]) /* X --> Y */
{
if(PreState.StateArray[0] + PreState.StateArray[1] > 8)
{
PourStepNext(&TempState, &PreState);
TempState.StateArray[0] = TempState.StateArray[0] + TempState.StateArray[1] - 8;
TempState.StateArray[1] = 8;
}
else
{
PourStepNext(&TempState, &PreState);
TempState.StateArray[1] += TempState.StateArray[0];
TempState.StateArray[0] = 0;
}
if(CheckState(TempState) == STATE_NOT_EXIST)
{
if(DoPouring(TempState) == POUR_SUCCEED)
{
PrintPourSteps(TempState);
return POUR_SUCCEED;
}
}
}
if(PreState.StateArray[2] < 3 && PreState.StateArray[0]) /* X --> Z */
{
if(PreState.StateArray[0] + PreState.StateArray[2] > 3)
{
PourStepNext(&TempState, &PreState);
TempState.StateArray[0] = TempState.StateArray[0] + TempState.StateArray[2] - 3;
TempState.StateArray[2] = 3;
}
else
{
PourStepNext(&TempState, &PreState);
TempState.StateArray[2] += TempState.StateArray[0];
TempState.StateArray[0] = 0;
}
if(CheckState(TempState) == STATE_NOT_EXIST)
{
if(DoPouring(TempState) == POUR_SUCCEED)
{
PrintPourSteps(TempState);
return POUR_SUCCEED;
}
}
}
if(PreState.StateArray[0] < 8 && PreState.StateArray[1]) /* Y --> X */
{
if(PreState.StateArray[0] + PreState.StateArray[1] > 8)
{
PourStepNext(&TempState, &PreState);
TempState.StateArray[1] = TempState.StateArray[0] + TempState.StateArray[1] - 8;
TempState.StateArray[0] = 3;
}
else
{
PourStepNext(&TempState, &PreState);
TempState.StateArray[0] += TempState.StateArray[1];
TempState.StateArray[1] = 0;
}
if(CheckState(TempState) == STATE_NOT_EXIST)
{
if(DoPouring(TempState) == POUR_SUCCEED)
{
PrintPourSteps(TempState);
return POUR_SUCCEED;
}
}
}
if(PreState.StateArray[2] < 3 && PreState.StateArray[1]) /* Y --> Z */
{
if(PreState.StateArray[1] + PreState.StateArray[2] > 3)
{
PourStepNext(&TempState, &PreState);
TempState.StateArray[1] = TempState.StateArray[1] + TempState.StateArray[2] - 3;
TempState.StateArray[2] = 3;
}
else
{
PourStepNext(&TempState, &PreState);
TempState.StateArray[2] += TempState.StateArray[1];
TempState.StateArray[1] = 0;
}
if(CheckState(TempState) == STATE_NOT_EXIST)
{
if(DoPouring(TempState) == POUR_SUCCEED)
{
PrintPourSteps(TempState);
return POUR_SUCCEED;
}
}
}
if(PreState.StateArray[0] < 8 && PreState.StateArray[2]) /* Z --> X */
{
if(PreState.StateArray[0] + PreState.StateArray[2] > 8)
{
PourStepNext(&TempState, &PreState);
TempState.StateArray[2] = TempState.StateArray[0] + TempState.StateArray[2] - 8;
TempState.StateArray[0] = 8;
}
else
{
PourStepNext(&TempState, &PreState);
TempState.StateArray[0] += TempState.StateArray[2];
TempState.StateArray[2] = 0;
}
if(CheckState(TempState) == STATE_NOT_EXIST)
{
if(DoPouring(TempState) == POUR_SUCCEED)
{
PrintPourSteps(TempState);
return POUR_SUCCEED;
}
}
}
if(PreState.StateArray[1] < 8 && PreState.StateArray[2]) /* Z --> Y */
{
if(PreState.StateArray[1] + PreState.StateArray[2] > 8)
{
PourStepNext(&TempState, &PreState);
TempState.StateArray[2] = TempState.StateArray[1] + TempState.StateArray[2] - 8;
TempState.StateArray[1] = 8;
}
else
{
PourStepNext(&TempState, &PreState);
TempState.StateArray[1] += TempState.StateArray[2];
TempState.StateArray[2] = 0;
}
if(CheckState(TempState) == STATE_NOT_EXIST)
{
if(DoPouring(TempState) == POUR_SUCCEED)
{
PrintPourSteps(TempState);
return POUR_SUCCEED;
}
}
}
return POUR_FAIL;
}
int main()
{
int i, j;
STATE OriginalState;
StateIndex = 0;
MaxSteps = 0;
for(i = 0; i < MAX_STATES; i++)
PourStepState[i] = 0;
OriginalState.StateArray[0] = 8;
OriginalState.StateArray[1] = 8;
for(i = 2; i < 7; i++)
OriginalState.StateArray[i] = 0;
DoPouring(OriginalState);
printf("\tX\tY\tZ\tA\tB\tC\tD\nSTATE:");
for(j = 0; j < 7; j++)
{
printf("\t%d", OriginalState.StateArray[j]);
}
printf("\n");
for(i = MaxSteps; i > 0; i--)
{
printf("STATE:");
for(j = 0; j < 7; j++)
printf("\t%d", PrintStepIndex[i].StateArray[j]);
printf("\n");
}
printf("Total steps: %d.\ndone.\n", MaxSteps);
return 0;
}














 2357
2357

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









