







 本文介绍了支持向量机(SVM)的工作原理,包括如何在数据线性不可分时处理分类问题,以及在多类问题中的应用。通过R语言实现SVM,详细讲解了线性SVM和径向SVM,并使用cats数据集进行二元分类实例。此外,还探讨了参数调优和绘制网格图以展示SVM分类效果。
本文介绍了支持向量机(SVM)的工作原理,包括如何在数据线性不可分时处理分类问题,以及在多类问题中的应用。通过R语言实现SVM,详细讲解了线性SVM和径向SVM,并使用cats数据集进行二元分类实例。此外,还探讨了参数调优和绘制网格图以展示SVM分类效果。
支持向量机是一个相对较新和较先进的机器学习技术,最初提出是为了解决二类分类问题,现在被广泛用于解决多类非线性分类问题和回归问题。继续阅读本文,你将学习到支持向量机如何工作,以及如何利用R语言实现支持向量机。
支持向量机如何工作?
简单介绍下支持向量机是做什么的:
假设你的数据点分为两类,支持向量机试图寻找最优的一条线(超平面),使得离这条线最近的点与其他类中的点的距离最大。有些时候,一个类的边界上的点可能越过超平面落在了错误的一边,或者和超平面重合,这种情况下,需要将这些点的权重降低,以减小它们的重要性。
这种情况下,“支持向量”就是那些落在分离超平面边缘的数据点形成的线。
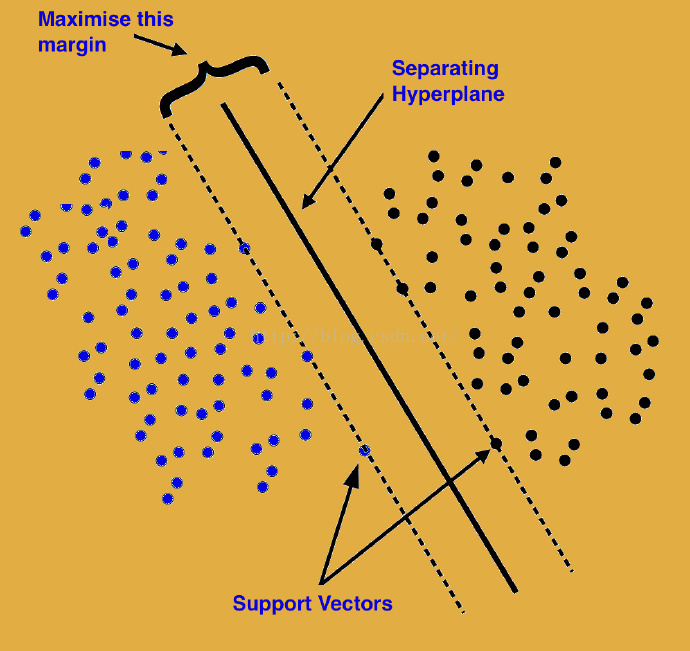
无法确定分类线(线性超平面)时该怎么办?
此时可以将数据点投影到一个高维空间,在高维空间中它们可能就变得线性可分了。它会将问题作为一个带约束的最优化问题来定义和解决,其目的是为了最大化两个类的边界之间的距离。
我的数据点多于两个类时该怎么办?
此时支持向量机仍将问题看做一个二元分类问题,但这次会有多个支持向量机用来两两区分每一个类,直到所有的类之间都有区别。
工程实例
让我们看一下如何使用支持向量机实现二元分类器,使用的数据是来自MASS包的cats数据集。在本例中你将尝试使用体重和心脏重量来预测一只猫的性别。我们拿数据集中20%的数据点,用于测试模型的准确性(在其余的80%的数据上建立模型)。
|
1
2
3
4
|
# Setup
# 先需要安装SVM包e1071;
library
(
e1071
)
data
(
cats
,
package
=
"MASS"
)
inputData
<
-
data
.
frame
(
cats
[
,
c
(
2
,
3
)
]
,
response
=
as
.
factor
(
cats
$
Sex
)
)
# response as factor
|
线性支持向量机
传递给函数svm()的关键参数是kernel、cost和gamma。Kernel指的是支持向量机的类型,它可能是线性SVM、多项式SVM、径向SVM或Sigmoid SVM。Cost是违反约束时的成本函数,gamma是除线性SVM外其余所有SVM都使用的一个参数。还有一个类型参数,用于指定该模型是用于回归、分类还是异常检测。但是这个参数不需要显式地设置,因为支持向量机会基于响应变量的类别自动检测这个参数,响应变量的类别可能是一个因子或一个连续变量。所以对于分类问题,一定要把你的响应变量作为一个因子。
|
1
2
3
4
5
6
|
# linear SVM
svmfit
<
-
svm
(
response
~
.
,
data
=
inputData
,
kernel
=
"linear"
,
cost
=
10
,
scale
=
FALSE
)
# linear svm, scaling turned OFF
print
(
svmfit
)
plot
(
svmfit
,
inputData
)
compareTable
<
-
table
(
inputData
$
response
,
predict
(
svmfit
)
)
# tabulate
mean
(
inputData
$
response
!=
predict
(
svmfit
)
)
# 19.44% misclassification error
|

径向支持向量机
径向基函数作为一个受欢迎的内核函数,可以通过设置内核参数作为“radial”来使用。当使用一个带有“radial”的内核时,结果中的超平面就不需要是一个线性的了。通常定义一个弯曲的区域来界定类别之间的分隔,这也往往导致相同的训练数据,更高的准确度。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









