









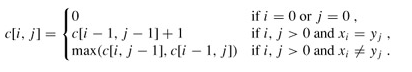
回溯输出最长公共子序列过程(一图胜千言):
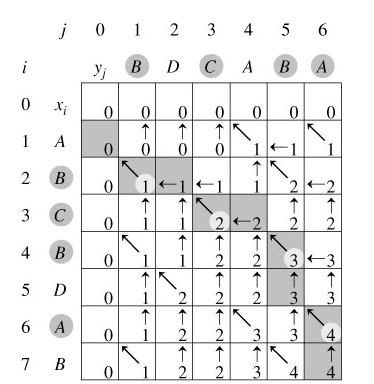
算法分析:
由于每次调用至少向上或向左(或向上向左同时)移动一步,故最多调用(m + n)次就会遇到i = 0或j = 0的情况,此时开始返回。返回时与递归调用时方向相反,步数相同,故算法时间复杂度为Θ(m + n)。
代码:
#include <stdio.h>
#include <string.h>
int c[1005][1005];
int fun(int a,int b)
{
return a>b?a:b;
}
int main()
{
char a[1005],b[1005];
while(scanf("%s %s",a,b)!=EOF)
{
memset(c,0,sizeof(c));
int la=strlen(a),lb=strlen(b);
int i,j;
int max=0;
for(i=0;i<=la;i++)
{
for(j=0;j<=lb;j++)
{
if(i==0 || j==0)
c[i][j]==0;
else if(a[i-1]==b[j-1])//注意,判断是位数错开了了一位
c[i][j]=c[i-1][j-1]+1;
else
c[i][j]=fun(c[i][j-1],c[i-1][j]);
}
}
printf("%d\n",c[la][lb]);
}
return 0;
}/*
公式:
/ 0 if i<0 or j<0
c[i,j]= c[i-1,j-1]+1 if i,j>=0 and xi=xj //xi-->a[i-1] yi-->b[i-1]
\ max(c[i,j-1],c[i-1,j] if i,j>=0 and xi≠xj
*/















 6533
6533

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









