







计算机系统设计者的基本任务是提高处理机指令的执行速度,而采取的主要措施是指令级的并行性,即让多条指令同时参与解释的过程。常用的有三种方法:
- 采用流水线技术,称为流水线处理机或超流水线处理机(SuperPipelining)。
- 在一个处理机中设置多个独立的功能部件,例如,在一个处理机中设置独立的定点算术逻辑部件、浮点加法部件、乘除法部件、访问存储器部件以及分支操作部件等,称为多操作部件处理机或超标量处理机(Superscalar)。也可以把超流水线技术与超标量技术结合起来,称为超标量超流水线处理机。
- 超长指令字(VeryLongInstructionWord,VLlW)技术,在一条指令中设置有多个独立的操作字段,每个字段可以分别独立地控制各个功能部件并行工作。
标量流水工作原理
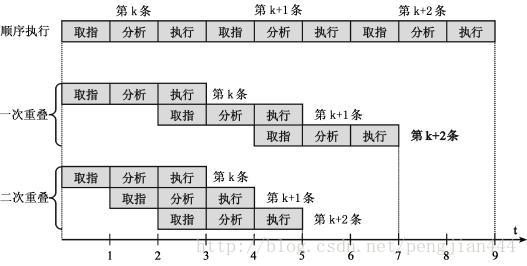
指令的重叠解释方式
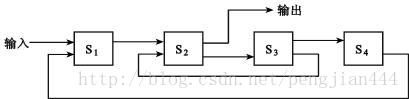
将一个指令的执行过程分为多个阶段,一般把一条指令的解释过程分为3个(取指、分析和执行)或5个(取指、译码、执行、访存和写回)阶段。然后执行过程如下图:
先行控制技术
先行控制(Look-Ahead)技术最早在IBM公司研制的STRETCH计算机中采用。目前,许多处理机中都已经采用了这种技术,包括超流水线处理机和超标量处理机等。
先行控制技术的关键是缓冲技术和预处理技术,以及这两者的结合。通过对指令流和数据流的预处理和缓冲,能够尽量使指令分析器和指令执行部件独立地工作,并始终处于忙碌状态,以提高处理器中部件的利用率。同时,先行控制技术也是解决指令重叠解释过程中,取指令、分析指令和执行指令三个部件访问主存冲突的根本办法。
缓冲技术是指在工作速度不固定的两个功能部件之间设置缓冲栈,用以平滑它们的工作速度。
预处理技术是把进入运算器的指令都预处理成 寄存器—寄存器型指令 ,它与缓冲技术相结合,为进入运算器的指令准备好所需的全部操作数。
先行控制技术的处理机结构如图
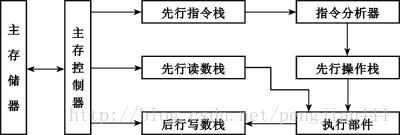
先行指令栈: 实为先行指令缓冲栈(或称指令缓冲栈),由一个指令缓冲寄存器堆和独立的控制逻辑构成。它可以把后续的指令“先行”取出,存放在缓冲栈中,从而为指令分析器分析新的指令做好准备。在有先行指令缓冲栈的处理机中,要设置两个程序计数器,一个是先行程序计数器PC1,用来指示到主存储器中取指令,另一个是现行程序计数器,它也就是原来意义上的程序计数器PC,用来记录指令分析器当前正在分析的指令地址。
先行操作栈: 是对指令分析器提供的指令进行预处理,即将所有指令转换为寄存器—寄存器型指令,以提高执行部件的处理速度。
先行读数栈和后行写数栈是两个数据缓冲栈,由若干个寄存器组成。其作用表现为两个方面:一是与先行操作栈配合,完成指令预处理过程中的操作数的读取;二是解决指令重叠解释过程中各功能部件同时访问主存而发生的冲突。
主存储器的访问源有三个,即先行指令栈、先行读数栈和后行写数栈。在一般处理机中, 存储控制器把这三个访问源的优先次序由高到低安排为:后行写数栈、先行读数栈、先行指令栈。
标量流水工作原理
首先,什么叫做标量处理机:只有标量数据表示和标量指令系统的处理机称为标量处理机。
分析标量流水线一般采用时空图法,一般的时空图如下:
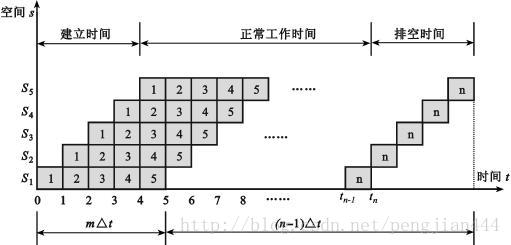
其工作状态分为三个时间阶段:建立时间,正常工作时间,排空时间。假设每个任务完成的时间都相等,则完成n个人物所需要的总时间为:
T = m Δt + ( n - 1 )Δt
标量流水线的分类
- 按照处理级别分类
- 指令级: 指令级流水则是把一条指令解释过程分成多个子过程,如前面所提到的:取指、译码、执行、访存及写回5个子过程。
- 操作部件级:操作部件级流水是将复杂的算术逻辑运算组成流水工作方式。例如,可将浮点加法操作分成求阶差、对阶、尾数相加以及结果规格化4个子过程。
3.* 处理机级*: 处理机级流水是一种宏流水,其中每个处理机完成某一专门任务。各个处理机处理所得到的结果需存放在与下一个处理机所共享的存储器中。
按功能分类
- 单功能流水线只完成一种功能。如浮点加法或乘法流水线。
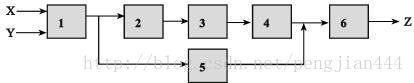
多功能流水线则可完成多种功能,它允许在不同时间,甚至同一时间内在流水线内连接不同功能段来实现不同的功能。下图是一个示例:
- 按工作方式分类
- 静态流水线: 在静态流水线中, 同一时间内它只能以一种功能方式工作。它可以是单功能的 ,也可以是多功能的。当是多功能流水线时 , 即从一种功能方式变为另一种功能方式时 , 必须先排空流水线 , 然后为另一种功能设置初始条件后方可使用。
- 动态流水线:动态流水线则允许在同一时间内将不同的功能段连接成不同的功能子集(前提条件是功能部件的使用不发生冲突),以完成不同的运算功能。
- 按连接方式分类
- 线性流水线中,从输入到输出,对于一个任务每个功能段只允许经过一次,不存在反馈(或前馈)回路。
- 非线性流水方式中则存在反馈(或前馈)回路,因此从输入到输出过程中,一个任务将数次通过流水线中的某些功能段。
-
标量流水线性能分析
+* 吞吐率*: 流水线的吞吐率(ThoughputRate,TP)是指单位时间内从流水线中流出的任务(结果)数。
+ 效率: 流水线的效率(Efficiency)是指流水线中的各功能段(或设备)的利用率。
+ 加速比: 加速比(SpeedupRatio)是指采用流水方式后的工作速度与等效的顺序串行方式的工作速度之比。
标量流水线控制障碍
要使得流水线有较好的性能,就应该让流水线能够畅通流动而不发生断流。但是流水线中通常都存在着一些相关性问题分别是:资源或结构相关,数据相关和控制相关。此外中断同样可能使得流水线断流。
相关
- 资源或结构相关:当有多条指令进入流水线后在同 一机器周期内争用同一功能部件所发生的相关 ( 冲突 ) 。
数据相关:这是由于流水线中的各条指令的重叠操作使得原来对操作数的访问顺序发生了变化,从而导致了数据相关的冲突。
解决这种数据相关的方法 :
- 推迟后续指令进入流水线。即遇到数据相关时 , 就停顿后继指令的运行 , 直至前面指令的结果已经生成。
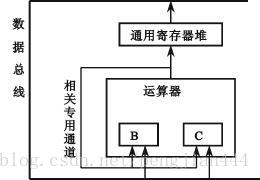
- 采用定向技术 , 又称为旁路技术或相关专用通路技术
根据指令间的对同一寄存器读和写操作的先后次序关系,数据相关冲突可分为读与写 ( RAW ) 、写与读 ( WAR ) 和写与写 ( WAW) 三种类型。
+RAW:
[1] MUL R1 , R2 ; ( R 1 ) × ( R 2 ) →R 1
[2] ADD R3 , R1 ; ( R 1 ) + ( R 3 ) →R 3
//[2]读取的应该是被[1]写入的新的r1的值,如果以流水的方式并行的话,[2]可能读到[1]写入之前的r1的数据。
//这个时候应该等[1]处理完r1之后[2]再来读取r1新的值。
- WAR:
[1] MUL R1 , R2; ( R 1 ) × ( R 2 ) →R 1
[2] MOV R2 , # 00 H ; 0→ R 2
// 如果r2先被[2]先入新的值,然后[1]再去读取的话,这个时候的数据已经被r2修改了,而r1应该读取的是r2被修改之前的值。
// 这个时候应该等[1]读取完r2, [2]才能修改r2的值。 - WAW:
[1] MUL R1, R2 ; ( R 1 ) × ( R 2 ) →R 1
[2] MOV R1 , #00H ; 0→ R 1
// 两条指令执行完之后r1的之应该是[2]写入的值,但是如果以流水的方式并行的话,可能最后的结果是[1]写入的值。
- WAR:
控制相关:是指进入流水线的转移指令(尤其是条件转移指令)与其后续指令之间存在相关。
中断处理: 中断会引起流水线断流,但出现概率比条件转移的概率要低得多,且又是随机发生的。所以,流水计算机处理中断主要是如何处理好断点现场的保存和恢复,而不是如何缩短流水线的断流时间。
所谓不精通断点法处理,是指不论指令i在流水线的哪一段发生中断,未进入流水线的后续指令不再进入,已在流水线的指令仍继续流完,然后才转入中断处理程序。这样,断点就不一定是i,可能是i+1或i+2,i+3,…,即断点是不精确的。仅当指令i在第1段响应中断时,断点才是精确的。
不精确断点法不利于编程和程序的排错。
所谓精通断点法处理,是指不论指令i是在流水线中哪一段响应中断,给中断处理程序的现场全都是对应i的,i之后流入流水线的指令的原有现场都能恢复。














 1064
1064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









