







先来个实例:
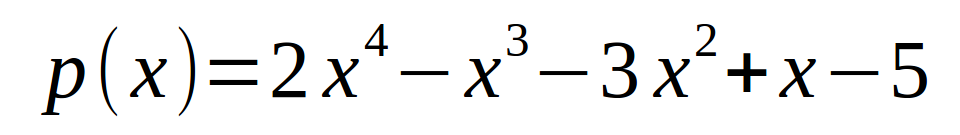
计算x=7时p(x)的值.
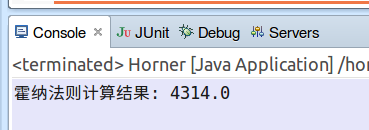
解法1:我们想到的就是直接将x=7代入方程,然后算出结果:4314.(效率不高)
解法2: 使用霍纳法则:
步骤:
1.建立二维表格,将公式的系数填入第一行(即使对应项系数为0也要填写).
2.对于第二行,除了第一个单元格直接填写系数外,其他单元格的值的计算方式都是:
x的值* 前一单元格的值+本单元格对应于公式的系数
(比如第二个单元格: 7* 2 + (-1 ) = 13.其中x的值为7, 2是前一单元格的值, 本单元格对上的系数为-1 .)
计算结果就是最后一个单元格的值:4314.
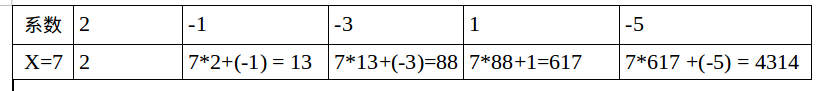
你可能会想为什么表格的规律会是这样.
其实霍纳法也是从上面的多项式通过提取x得来的.
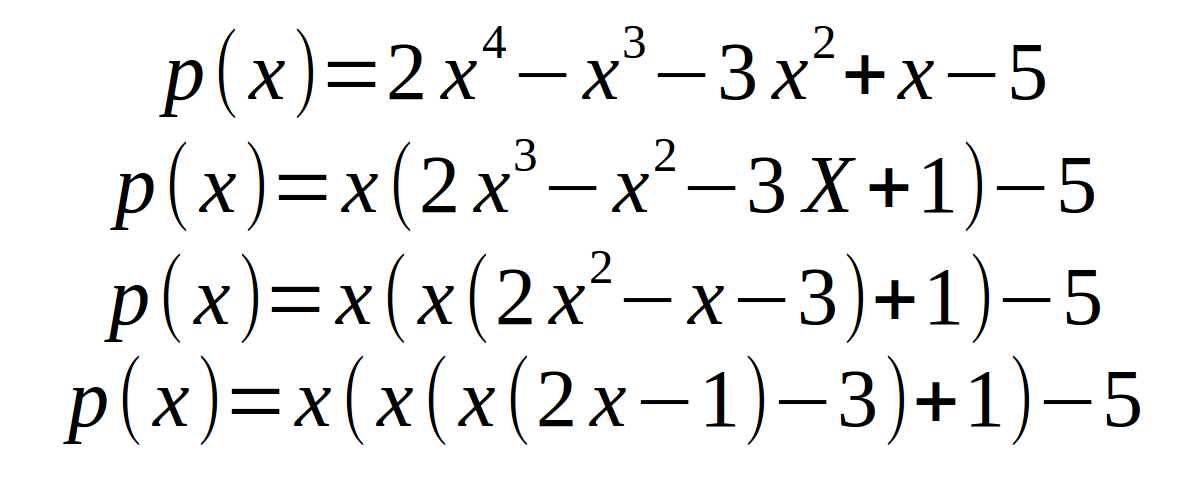
其中上面表格的第二行的计算过程如下:
第一个单元格的值时上图中最里面的那个X的值,第二个单元格是由(2X-1)算出来的,第三个单元格由X(2X-1)-3算出来的.依次类推.
霍纳法的伪代码:
Horner(P[0..n],X)
//输入:一个n次多项式的系数数组P[0..n] (从高位到低位),以及一个数字X
p <–P[0] //第一个单元格的值
for i <–0 to n do
p<–x*p + P[i] //迭代产生每一个单元格的结果,迭代结束后得到最后一个单元格的结果也是多项式关于X的最终计算结果
return p //返回值就是多项式关于X的计算结果
该算法的时间复杂度为: n
霍纳法与普通代入运算有什么优势? 效率高
就拿上面例子说,普通代入时单单第一项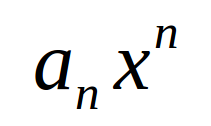
但是霍纳法则计算所有项只需n次运算就完成,效率妥妥的.
以下是本人的java实现霍纳法则代码:
package com.shusheng.Horner;
public class Horner {
public static void main(String[] args) {
double[] P = {2,-1,-3,1,-5};
double x = 7;
System.out.println("霍纳法则计算结果: "+horner(P, x));
}
/**
* 霍纳法则
* @param P 该数组装多项式参数,从高位到低位
* @param x 要代入多项式求值的x值
* @return 多项式关于x的值
*/
public static double horner(double[] P, double x) {
int pSize = P.length;
double temp = P[0];//表格的第一个值
for(int i=1;i<pSize;i++){
temp = x*temp + P[i];
}
return temp;
}
}















 914
914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









