






《强化学习》 第一讲 简介
简介
强化学习是机器学习的一个分支。具体来说,机器学习分为:监督学习,非监督学习,强化学习。
不同于其他机器学习,RL有几个特点:
1.没有监督者,只有奖励信号(reward)
2.反馈是延迟的,不一定是实时的
3.时间序列是一个非常重要的因素
4.代理者(agent)的行为动作(action)影响后续接收到的数据
奖励(Reward)
Rt是一个标量的反馈信号,表明了agent进行第t步的好坏。agent的工作就是最大化累计奖励。
RL是基于奖励假设的:所有的目标都可以被描述为最大化累计奖励。
序列决策(sequential decision making)
目标是选择action使得总体的未来奖励最大化
这些动作可能会有长期的影响
奖励可能是延迟的
有时候牺牲暂时的奖励来获取更多的长期奖励
代理者和环境(agent and environment)
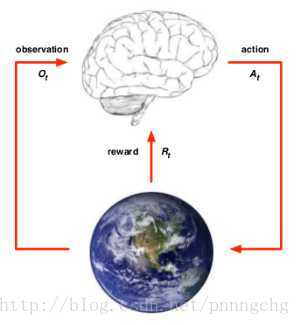
具体来说:
对于agent:对环境有一个观测值Qt,给出一个动作At,得到一个奖励Rt
对于环境:收到一个动作At,给出观测值Qt+1,奖励Rt+1
历史和状态(History and state)
历史是观测值、动作和奖励的序列
状态是历史的函数
环境状态:环境状态是环境的私有呈现,例如环境用来选择下一个观测值或者奖励的数据。通常来说,环境状态对agent是不可见的,即使可见,也通常包含了不相关的信息。
个体状态:是agent的私有呈现,例如agent用来选择下一个动作的信息
信息状态:也叫作马尔科夫状态,包含了历史上的所有信息
马尔科夫(Markov)

在给定现在状态的情况下,未来是独立于过去的。一旦现在的状态已知,历史就可以被丢弃。
环境状态是markov,我们可以想象,当前的状态包含了决定下一个状态的所有信息,因此我们可以抛弃之前的所有状态信息。一个完整的历史也是markov的。
完全可观测的环境(Fully Observable Environment)
agent直接观测环境状态。这种情况下,观测值Qt=环境状态t=agent状态t
通常,这是马尔科夫决策过程(MDP)
部分可观测环境(Partially Observable Environment)
agent不直接观测环境
例如:带有摄像头的机器人并不被告知它的确切位置;贸易agent只能观察现有的价格;扑克机器人只能观察牌桌上摊开的牌
通常,这时部分可观测马尔科夫决策过程(POMDP)
这时,agent必须构建自己的状态呈现形式,例如:
1.完全记住历史,用历史代替agent的状态
2.Beliefs of environment state:利用已有经验(数据),用各种个体已知状态的概率分布作为当前时刻的个体状态的呈现
3.Recurrent neural network:不需要知道概率,只根据当前的个体状态以及当前时刻个体的观测,送入循环神经网络(RNN)中得到一个当前个体状态的呈现
强化学习Agent的主要组成部分
策略(Policy),价值函数(Value function),模型(Model)
Policy
表明了agent能够采取的行动,行为函数,以它的状态作为输入,以它下一步的行动作为输出,注意action可以是state确定函数,也可以是随机函数
Value Function
agent在某种状态下的好坏,采取某种行动后的好坏。在这种状态下采取那种行动那么预期的奖励是多少,评估在某种情形下做的怎么样。当面对两个不同的状态时,个体可以用一个Value值来评估这两个状态可能获得的最终奖励区别,继而指导选择不同的行为,即制定不同的策略。同时,一个价值函数是基于某一个特定策略的,不同的策略下同一状态的价值并不相同。
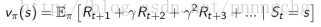
Model
预测感知环境的变化
个体对环境的一个建模,它体现了个体是如何思考环境运行机制的(how the agent think what the environment was.),个体希望模型能模拟环境与个体的交互机制。
model会预测两个东西:一个是下一个状态的概率,另一个是即时奖励。
model在RL中不是必须的。应该注意到,model的概念只是针对agent而言的,环境本身并不是一个model,也并不需要model的概念。
RL Agent的分类
自我理解Agent像是人类大脑,进行强化学习时,我们需要确定选择什么样大脑进行决策,比如是工程师还是商人还是艺术家的思维方式来解决这个问题。主要的agent分为3类:
1.基于价值选择函数Value Based:只有对状态的价值选择函数,没有直接的策略函数。策略函数有价值函数间接得到。
2.基于策略函数Policy Based:个体中行为直接由策略函数产生,个体并不维护一个对各状态价值的估计函数。
3.演员-评判家形式 Actor-Critic:个体既有价值函数、也有策略函数。两者相互结合解决问题。
另外,基于agent是否使用model可以将agent分为:model-free和model-based,其中model-free不去理解环境的变化
学习和规划(learning and planning)
学习:初始环境未知,agent与环境进行交互,过程中逐渐改善policy
规划:环境的model已知,agent与model进行交互,逐步改善policy
常见的强化学习思路是:首先对环境进行学习,产生一个model,然后根据这个model进行规划。
探索和利用(Exploration and Exploitation)
强化学习是一个试错的学习过程,agent需要在与环境的交互中发现好的policy,而且过程中不会失去太多的reward,探索更多的是去发现环境的信息,利用则是根据已知信息去最大化reward。两者是一个平衡的过程。
例如去饭馆吃饭,探索可能意味着这一次选择新的餐厅尝试新的菜品,而利用则意味着这次继续选择老地方。
预测和控制(Prediction and Control)
预测:给定policy,预测未来。可以看做是在给定策略下求解价值函数。
控制:找到最好的policy,优化未来。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









