







本文章收录在黑鲸智能系统知识库-黑鲸智能系统知识库成立于2021年,致力于建立一个完整的智能系统知识库体系。我们的工作:收集和整理世界范围内的学习资源,系统地建立一个内容全面、结构合理的知识库。
作者博客:途中的树
强化学习算法的思路非常简单,以游戏为例,如果在游戏中采取某种策略可以取得较高的得分,那么就进一步「强化」这种策略,以期继续取得较好的结果。这种策略与日常生活中的各种「绩效奖励」非常类似。我们平时也常常用这样的策略来提高自己的游戏水平。——AI百科
强化学习(RL)是机器学习的一个领域,涉及软件代理如何在环境中采取行动以最大化一些累积奖励的概念。该问题由于其一般性,在许多其他学科中得到研究,如博弈论,控制理论,运筹学,信息论,基于仿真的优化,多智能体系统,群智能,统计和遗传算法。。在运筹学和控制文献中,强化学习被称为近似动态规划或神经动态规划。——wiki
强化学习的结构
- 强化学习使用输出 Y ( X i , s α ) Y(X_i,s_\alpha) Y(Xi,sα)产生的效果对接下来的系统(如 机器人系统)产生的影响,计算系统 S S S内部参数的变化,目的是使奖励 r r r 最大化。下面是强化学习算法的基本框架

- 简化一下这个结构我们可以得到下图,其中系统 S α S_\alpha Sα 和学习机制组成了 Agent,评估系统和系统的外部环境组成了环境

Agent - Environment 框架
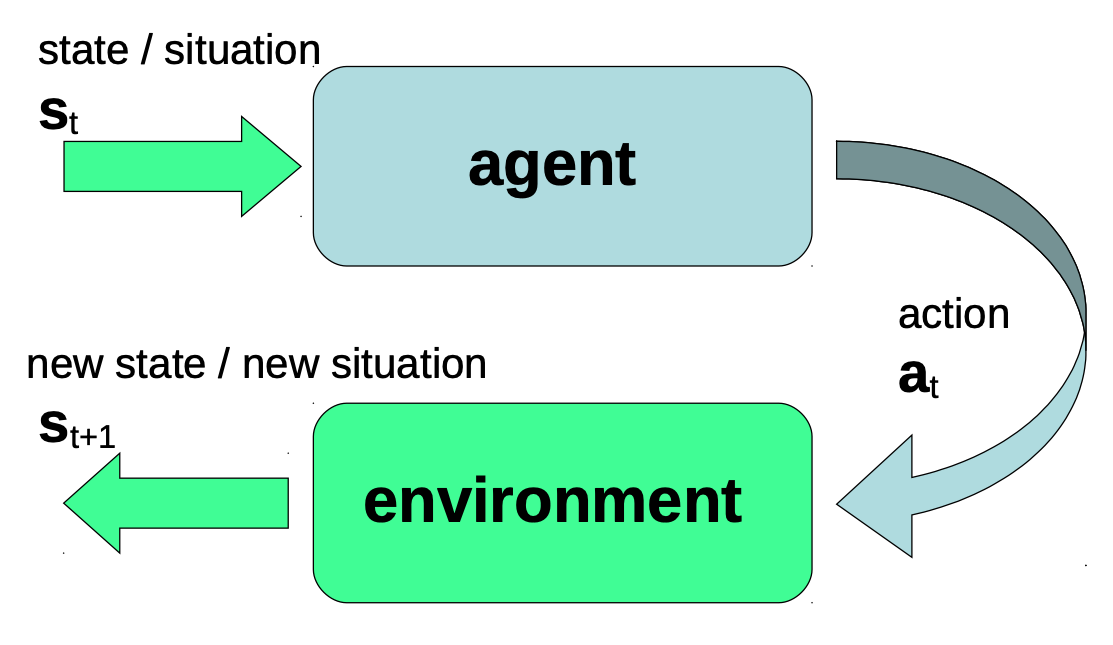
- 由此得到一个Agent - Environment 框架
- Agent: 在时间t 观测到状态(或情况) s s s, 并产生一个内部的行动 a t a_t at
- 参数: 一个内部(世界)模型和一个内部行为策略 π \pi π
- 环境所处的状态或情况 s t s_t st ( s s s 不一定是物理学、数学或工程学中严格的正式定义中的状态空间的表示。一个情况可以是真实状态的一个近似值。)
- 行动 a t a_t at: 从允许的、可能的行动的集合中选取的行动,这个集合通常取决于 s t s_t st
- 处于状态 s t s_t st的环境: 收到来自Agent的行动 a t a_t at,并产生新的状态/情况 s t + 1 s_{t+1} st+1反馈
- 奖励
- 环境从时间t到t+1的过渡变化中,为Agent产生一个反馈(奖励或惩罚)
- 该反馈是环境对行动、状态和一个未知的、取决于内部环境的奖励系统产生的奖励
- r t + 1 r_{t+1} rt+1是在从时间段 t t t过渡到 t + 1 t+1 t+1后产生的奖励信号
- 新的状态 S t + 1 S_{t+1} St+1和奖励都是以离散的时间为基础产生的。

强化学习系统的组成
- Agent
- 包含一个策略 π \pi π 和一组内部变量。
- 环境
- 接收行动 a a a,产生状态 s s s和奖励 r r r,包含一个奖励系统,可能是随机的
- 状态空间/情况空间
S
S
S
- 多维空间, s t , s t + 1 s_t,s_{t+1} st,st+1
- 行动空间
A
A
A
- 可能/允许的行动范畴
- 奖赏系统
- 产生(标量)奖赏 r t , r t + 1 r_t ,r_{t+1} rt,rt+1
强化学习的主要任务
- Agent的目标是
- 在一个足够长的时间内,使奖励量最大化
- 强化学习系统的任务是
- 为Agent生成从状态到行动的映射 π \pi π,使其在给定的环境中获得最大的奖赏量
- 强化学习系统的一个子任务是
- 尽可能多地了解环境和它的奖励行为,以更好地塑造Agent的行为策略 π \pi π。
Agent的目标
- 在一个足够长的时间内,使奖励量最大化
- 设真实的回报奖励是
R
t
∗
R^*_t
Rt∗,这是从时间
t
t
t开始的累积的未来回报
- R t ∗ = r t + 1 + r t + 2 + r t + 3 + . . . + r T R^*_t = r_{t+1} + r_{t+2}+r_{t+3}+...+r_{T} Rt∗=rt+1+rt+2+rt+3+...+rT
- 但是通常我们并不知道真实的回报是多少,所以强化学习算法一般是处理预期的回报
R
t
R_t
Rt和误差
E
(
R
t
)
E(R_t)
E(Rt)
- R t = r t + 1 + r t + 2 + r t + 3 + . . . + r T R_t = r_{t+1} + r_{t+2}+r_{t+3}+...+r_{T} Rt=rt+1+rt+2+rt+3+...+rT
- 未来的回报是无止尽的,所以需要考虑以下两件事
- 时间跨度
T
T
T 的取值
- T T T 是无限还是有限的
- 降低未来的回报的影响
- 远在未来的奖励是否与那些先来的奖励一样有价值?如果不是,需要设置一个discounting factor γ < 1.0 \gamma < 1.0 γ<1.0 d
- R t = r t + 1 + γ r t + 2 + γ 2 r t + 3 + . . . R_t = r_{t+1} + \gamma r_{t+2}+ \gamma^2 r_{t+3}+... Rt=rt+1+γrt+2+γ2rt+3+...
-
R
t
=
∑
k
=
0
T
γ
k
r
t
+
1
+
k
,
0
≤
γ
≤
1.0
R_t = \sum^T_{k=0}\gamma^kr_{t+1+k},0 \leq \gamma \leq 1.0
Rt=∑k=0Tγkrt+1+k,0≤γ≤1.0
- 如果 T T T是无限的则 γ \gamma γ不能大于等于 1 1 1
- 如果 γ = 1 \gamma = 1 γ=1 则 T T T必须是有限的
- 时间跨度
T
T
T 的取值
奖励Reward特殊类型

- 完全延迟奖励pure delayed reward
- 在一些情节性的任务中,将奖励推迟到情节完成后才进行是有意义的:如国际象棋,双陆棋
- 游戏过程中的所有奖励都是0.0,只有最后的奖励
r
T
r_T
rT是不同的:
- r t = r T = 0.0 r_t =r_T =0.0 rt=rT=0.0 当 t < T t<T t<T时或者结果是平局
- r t = + 1.0 r_t=+1.0 rt=+1.0 当胜利时
- r t = − 1.0 r_t=-1.0 rt=−1.0 当失败时
- 使用完全延迟奖励,Agent必须完成完整的情节,然后才能利用反馈来进行学习。
- 游戏过程中的所有奖励都是0.0,只有最后的奖励
r
T
r_T
rT是不同的:
- 在一些情节性的任务中,将奖励推迟到情节完成后才进行是有意义的:如国际象棋,双陆棋
- 完全负奖励 pure negative reward
- 当只提供负面的奖励时,在剧情完成之前,无论Angent做了什么,他就会受到 “惩罚”。
- r t = − 1.0 r_t=-1.0 rt=−1.0 当 t < T t<T t<T时
- r T = 0.0 r_T=0.0 rT=0.0 当到达最后一步时
- 当应用一个完全负奖励时,系统将试图摆脱那些负反馈值。由于每一个行动都会受到惩罚,所以最好的办法是尽快完成这个情景。使用纯负奖励的目的是为了快速解决!
- 当只提供负面的奖励时,在剧情完成之前,无论Angent做了什么,他就会受到 “惩罚”。
- 规避策略 avoidance strategy
- 只在需要的时候给予Agent惩罚,其余时间
r
=
0
r=0
r=0
- r t = − 1.0 r_t=-1.0 rt=−1.0 当 s t ∈ { 特 殊 情 况 } s_t \in \{特殊情况\} st∈{特殊情况}
- r t = 0.0 r_t=0.0 rt=0.0 其余的大多数情况
- 当应用回避型奖励方案时,Agent试图避免特殊的、典型的讨厌的情况。
- 只在需要的时候给予Agent惩罚,其余时间
r
=
0
r=0
r=0
生成策略 π \pi π
- 策略可以将Agent输入的场景 s t s_t st映射道动作 a t a_t at上
- 生成的策略需要完成的目标驱使agent获得尽可能多的正奖励 r i r_i ri,使得总奖励 R t R_t Rt最大化
- 因为奖励是再实施行为
a
t
a_t
at后产生的,因此我们要想办法选取合适的行为
a
t
a_t
at
- 如果我们知道每个行动 a a a的 "价值 "有多大, 就可以把这个信息作为设计策略的基础了
- 在一个强化系统中,衡量价值的参数总是:奖励 r r r和回报 R R R
- 设一个行为的价值函数是
Q
(
a
)
Q(a)
Q(a),行动-价值函数为每个行动分配了一个价值
- 一个行动的 "价值 "是以这个行动的预期回报来衡量的
- 最优行为价值函数记为 Q ∗ ( a ) Q^*(a) Q∗(a)
- 如何获取行为价值函数?
- 通过输入正确的对应关系(监督学习)
- 通过仔细的评估反馈(来自环境)
- 因此在运行前需要给agent一些数据去学习
好策略与坏策略
- 一个精心设计的政策,将以行动价值函数Q(a)为基础进行决策(行动)
- 如果行动-价值函数Q(a)能够很好地代表环境,你可以尝试确定一个最佳政策
- 即使有了最优的行动价值函数Q*(a),确定最优政策也是一个挑战
- 只要你还没有得到一个好的行动价值函数,你就注定要通过试错来找到一个更好的
探索Exploration与利用Exploitation
为了设计一项政策,人们发现有两个主要的设计原则是有用的。组合起来也适用。
- Exploitation 利用
- 使用,利用你已经拥有的知识进行选择
- 最极端的方法是——贪婪行动选择(greedy action selection):选择提出最高回报 R R R的行动。
- Exploration 探索
- 探索新的行动,从而探索新的情况。
- 这可能会带来更好的可能性
- 极端版本是——随机行动选择(蒙特卡洛探索 Monte-Carlo Exploration):从允许的行动中,随机选择一个。
- 开发和探索是形成政策的两个主要范式
- 当你想学习一些关于环境的知识时,探索在强化学习的开始阶段是很有用的。
- 在强化学习的最后阶段,当你已经对环境有了足够的了解,并且当你想收获你的奖励时,开发是比较好的。
- 一个温和的、精心设计的、介于探索和开发之间的混合方法才是最优的设计方法
ε \varepsilon ε-Greddy Action Selection
- 一般的贪婪动作选择算法会选择 a t = a ∗ a_t = a^* at=a∗最优行动
-
ε
−
G
r
e
e
d
y
\varepsilon-Greedy
ε−Greedy 则是只有
(
1
−
ε
)
(1-\varepsilon)
(1−ε)的概率选择最优行为
a
∗
a^*
a∗
- a t = { a t w i t h p r o b a b i l i t y 1 − ε r a n d o m a c t i o n w i t h p r o b a b i l i t y ε a_t = \left \{ \begin{array}{rcl} a_t \ with \ probability\ 1-\varepsilon \\ random\ action\ with \ probability\ \varepsilon \end{array} \right. at={at with probability 1−εrandom action with probability ε
- 通常会把 ε \varepsilon ε 设置成时间依赖性的变量, ε = ε ( t ) \varepsilon=\varepsilon(t) ε=ε(t),并且是随着学习过程递减的
Softmax动作选择
另一个混合exploration和exploitation的方法是Softmax方法
- Softmax行动选择方法通过估计值对行动概率进行分级。
- 最常见的softmax版本使用吉布斯或玻尔兹曼分布来选择概率为
P
r
o
b
(
a
t
)
Prob(a_t)
Prob(at)的行动。
(τ是一个控制参数)- P r o b ( a t ) = e Q t ( a ) / τ ∑ e Q t ( a ) / τ Prob(a_t)= \frac{e^{Q_t(a)/ \tau}}{\sum e^{Q_t(a)/ \tau}} Prob(at)=∑eQt(a)/τeQt(a)/τ















 254
254











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









