








Chapter 4. Working with Key/Value Pairs
Key/Value RDDs are commonly used to perform aggregations(聚合),and often we will do some initial ETL(extract, transform, and load 提取,转换和加载) to get our data into a key/value format. Key/Value RDDs expose new operations(e.g., counting up reviews for each product, grouping together data with the same key, and grouping together two different RDDs ).
键/值RDDS常用于进行聚合,而且往往我们会做一些初步的ETL(提取,转换和加载),让我们的数据到一个键/值格式。键/值RDDS还揭示了新的操作(例如,计算了评论的每个产品,使用相同的密钥数据组合在一起,和两个不同的RDDS组合在一起)。
We also discuss an advanced feature that lets users control the layout of pair RDDs acorss nodes: partitioning. Using controllable partitioning, applications can sometimes greatly reduce communication costs by ensuring that data will be accessed together and will be on the same node. This can provide significant speedups. We illustrate partitioning using the PageRank algorithm as an example. Choosing the right partitioning for a distributed dataset is similar to choosing the right data structure for a local one—— in both cases, data layout can greatly affect performance.
我们还讨论了先进的功能,让用户控制各节点之间对RDDS布局:分区。通过使用可控的分区,确保数据将一起被访问而且在相同节点上,应用程序可以大大降低通信损耗。这可以提供显著的加速。我们以PageRank算法为例说明分区使用。为分布式数据集选择正确的分区是类似于为本地数据选择合适的数据结构一在这两种情况下,数据布局可以极大地影响性能。
Motivation
Spark provides special operations on RDDs containing key/value pairs. These RDDs are called pair RDDs. Pair RDDs are a useful building block in many programs, as they expose operations that allow you to act on each key in parallel or regroup data across the network. For example, pair RDDs have a reduceByKey() method that can aggregate data separately for each key, and a join() method that can merge two RDDs together by grouping elements with the same key. It is common to extract fields from an RDD (representing, for instance, an event time, customer ID, or other identifier) and use those fields as keys in pair RDD operations.
动机
Spark对包含键/值对的RDD提供专项操作。这些RDDS被称为 pair RDDS。pair RDDS在许多项目中是很有用的组成部分,因为它们的操作,使您可以作用于平行的每个键或者通过网络重新组合数据。例如,对RDDS有reduceByKey()方法,该方法可以为每个键单独汇总数据,和一个join()方法,可以通过组合使用相同的key合并两个RDDS在一起。从RDD提取字段(例如,一个事件时间,客户ID,或其它标识符),并使用这些字段作为pair RDD的key来操作,是很常见的。
Creating Pair RDDs
There are a number of ways to get pair RDDs in Spark. Many formats we explore loading from in Chapter 5 will directly return pair RDDs for their key/value data. In others cases we have a regular RDD that we want to turn into a pair RDD. We can do this by running a map() function that returns key/value pairs. To illustrate, we show code that starts with an RDD of lines of text and keys the data by the first word in each line.
The way to build key-value RDDs differs by language. In Python. for the functions on keyed data to work we need to return an RDD composed of tuples(see Example 4-1).
创建 Pair RDDS
在Spark中,有多种方式来获得 pair RDDs。我们在第5章探讨loading时,会有许多格式,将从键/值数据直接返回pair RDDs。在其他情况下,我们有一个标准的RDD,我们要变成pair RDD。我们可以通过运行map()函数,返回键/值对做到这一点。为了说明,我们看一下:开始是一个由文本的行组成的RDD,由每行中的第一个字作为key,生成pair RDD的代码。
可以通过不同的语言建立key/value RDDs。在Python中,对键控数据的功能来工作,我们需要返回元组组成的RDD(见例4-1)。
Example 4-1. Creating a pair RDD using the first word as the key in Python
pairs = lines.map(lambda x: (x.split(" ")[0], x)In Scala, for the functions on keyed data to be available, we also need to return tuples(see Example 4-2). An implicit conversion on RDDs of tuples exists to provide the additional key/value functions.
在Scala中,要使functions on keyed data 可用,我们需要返回元组。对存在元组的RDD进行了一个隐式转换来提供额外的key/pair 函数。
Example 4-2. Creating a pair RDD using the first word as the key in Scala
val pairs = lines.map(x => (x.split(" ")(0),x))Java doesn’t have a built-in tuple type, so Spark’s Java API has users create tuples using the scala.Tuple2 class. This class is very simple: Java users can construct a new tuple by writing new Tuple2(elem1,elem2) and can then access its elements with the ._1() and ._2() methods.
Java users alse need to call special versions of Spark’s functions when creating pair RDDs. For instance, the mapToPair() function should be used in place of the basic map() function. This is discussed in more detail in ‘Java’, but let’s look at a simple case in Example 4-3.
Java没有内置的元组类型,所以Spark的Java API由用户使用scala.Tuple2类创建一个元组。这个类是非常简单的:Java用户可以通过Tuple2(elem1,elem2)构造一个新的元组,然后通过._1()和._2()方法可以访问它的元素。
Java的用户创建pair RDDs时还需要调用Spark函数的特殊版本。例如,mapToPair()函数应代替基本map()函数使用。这在“Java”中有更详细的讨论,让我们看看例4-3,一个简单的例子。
Example 4-3. Creating a pair RDD using the first word as the key in Java
PairFunction<String, String, String> keyData =
new PairFunction<String, String, String>() {
public Tuple2<String, String> call(String x) {
return new Tuple2(x.split(" ")[0], x);
}
};
JavaPairRDD<String, String> pairs = lines.mapToPair(keyData);When creating a pair RDD from an in-memory collection in Scala and Python, we only need to call SparkContext.parallelize() on a collection of pairs. To create a pair RDD in Java from an in-memory collection, we instead use SparkContext.parallelizePair().
Transformations on Pair RDDs
Pair RDDs are allowed to use all the transformations available to standard RDDs. The same rules apply from “Passing Functions to Spark”. Since pair RDDs contain tuples, we need to pass functions that operate on tuples rather than on individual elements.Tables 4-1 and 4-2 summarize transformations on pair RDDs, and we will dive into the transformations in detail later in the chapter.
pair RDDs允许使用所有可用的标准RDDS的转换。同样的规则也适用于“Passing Functions to Spark”。由于pair RDD包含元组,我们需要传入函数的是元组而不是单个元素。表4-1和表4-2中总结的pair RDDs转换,我们将在后面进一步深入了解transformations。
Table 4-1. Transformations on one pair RDD (example: {(1, 2), (3, 4), (3, 6)})
| Function name | Purpose | Example | Result |
|---|---|---|---|
| reduceByKey(func) | Combine values with the same key. | rdd.reduceByKey((x,y)=>x+y) | {(1,2),(3,10)} |
| groupByKey() | Group values with the same key. | rdd.groupByKey() | {(1,[2]),(3,[4,6])} |
| combineByKey(createCombiner, mergeValue, mergeCombiners, partitioner) | Combine values with the same key using a different result type. | See examples 4-12 through 4-14. | |
| mapValues(func) | Apply a function to each value of a pair RDD without changing the key. | rdd.mapValues(x=>x+1) | {(1,3),(3,5),(3,7)} |
| flatMapValues(func) | Apply a function that returns an iterator to each value of a pair RDD, and for each element returned, produce a key/value entry with the old key. Often used for tokenization. | rdd.flatMapValues(x=>(x to 5) | {(1,2),(1,3),(1,4),(1,5),(3,4),(3,5)} |
| keys() | Return an RDD of just the keys. | rdd.keys() | {1,3,3} |
| values() | Return an RDD of just the values. | rdd.values() | {2,4,6} |
| sortByKey() | Return an RDD sorted by the key. | rdd.sortByKey() | {(1,2),(3,4),(3,6)} |
Table 4-2. Transformations on two pair RDDs(rdd = {(1,2),(3,4),(3,6)}, other = {(3,9)})
| Function name | Purpose | Example | Result |
|---|---|---|---|
| subtractByKey | Remove elements with a key present in the other RDD. | rdd.subtractByKey(other) | {(1,2)} |
| join | Perform an inner join between two RDDs. | rdd.join(other) | {(3,(4,9)),(3,(6,9))} |
| rightOuterJoin | Perform a join between two RDDs where the key must be present in the first RDD. | rdd.rightOuterJoin(other) | {(3,(Some(4),9)),(3,(Some(6),9))} |
| leftOuterJoin | Perform a join between two RDDs where the key must be present in the other RDD. | rdd.leftOuterJoin(other) | {(1,(2,None)),(3,(4,Some(9))),(3,(6,Some(9)))} |
| cogroup | Group data from both RDDs sharing the same key. | rdd.cogroup(other) | {(1,([2],[])),(3,([4,6],[9]))} |
We discuss each of these families of pair RDD functions in more detail in the upcoming sections.
Pair RDDs are also still RDDs (of Tuple2 objects in Java/Scala or of Python tuples), and thus support the same functions as RDDs. For instance, we can take our pair RDD from the previous section and filter out lines longer than 20 characters, as shown in Example 4-4 through through 4-6 and Figure 4-1.
Example 4-4. Simple filter on second element in Python
result = pairs.filter(lambda keyValue: len(keyValue[1]) < 20)
Example 4-5. Simple filter on second element in Scala
pairs.filter{case (key, value) => value.length < 20}
Example 4-6. Simple filter on second element in Java
Function<Tuple2<String, String>, Boolean> longWordFilter =
new Function<Tuple2<String, String>, Boolean>() {
public Boolean call(Tuple2<String, String> keyValue) {
return (keyValue._2().length() < 20);
}
};
JavaPairRDD<String, String> result = pairs.filter(longWordFilter);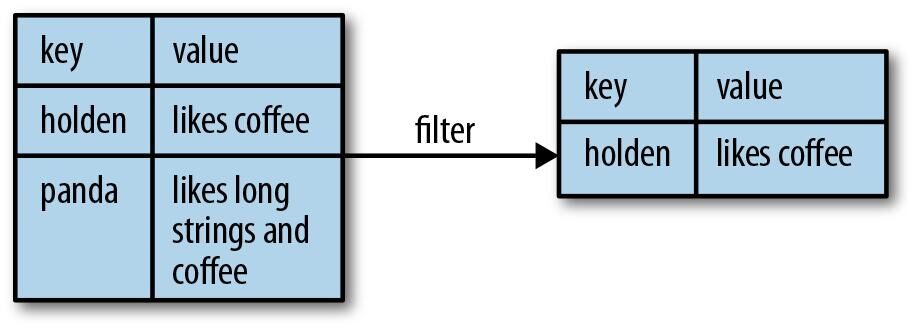
Sometimes working with pairs can be awkward if we want to access only the value part of our pair RDD. Since this is common pattern, Spark provides the mapValues(func)function, which is the same as map{case (x,y):(x,func(y))}. We will use this function in many of our examples.
如果我们只想访问pair RDD的value部分,pair RDD有时候是很尴尬的。。由于这是经常发生的,Spark提供mapValues(func) 函数, 与 map{case (x,y):(x,func(y))} 的功能相同。我们将在很多例子中使用这个函数。
我们现在讨论pair RDD 的函数, 从aggregation开始。
Aggregations
When datasets are described in terms of key/value pairs, it is common to want to aggregate statistics across all elements with the same key. We have looked at the fold(), combine(), and reduce() actions on basic RDDs, and similar per-key transformations exist on pair RDDs. Spark has a similar set of operations that combines values that have the same key. These operations return RDDs and thus are transformations rather than actions.
当数据集用键值对来描述时,希望用相同的键来聚合统计所有元素是很常见的。我们已经看了基础RDD的fold(), combine(), and reduce() actions,pair RDD也存在相似的转换。Spark对相同的key有类似的一套操作来combine values。这些操作返回RDDs,因此是transmations而不是actions。
reduceByKey() is quite similar to reduce(); both take a function and use it to combine values. reduceByKey()runs several parallel reduce operations, one for each key in the dataset, where each operation combines values that have the same key. Because datasets can have very large numbers of keys,reduceByKey() is not implemented as an action that returns a value to the user program. Instead, it returns a new RDD consisting of each key and the reduced value for that key.
reduceByKey()与reduce()相似,都是用一个函数来组合values。reduceByKey() 并行运行多个reduce操作,数据集上的每个key都运行一个reduce,每个操作在相同的key上组合values。由于数据集可以有非常多的key,reduceByKey()不是返回一个一系列key的value给用户的action操作。相反,它返回一个新RDD,包含每个键和该键经过reduced的value。
foldByKey() is quite similar to fold(); both use a zero value of the same type of the data in our RDD and combination function. As withfold(), the provided zero value for foldByKey()should have no impact when added with your combination function to another element.
foldByKey()类似于fold(),都是在RDD中用一个相同类型的数据的 zero value 并且组合函数。与 fold()一样,foldByKey()提供的0值应该对另一个元素的合并函数没有影响。
As Examples 4-7 and 4-8 demonstrate, we can use reduceByKey() along with mapValues() to compute the per-key average in a very similar manner to how fold() and map() can be used to compute the entire RDD average (see Figure 4-2). As with averaging, we can achieve the same result using a more specialized function, which we will cover next.
例4-7和4-8表明,我们可以用reduceByKey()连同mapValues()来计算每个key的平均值,类似的,fold()和map()也可以用来计算RDD的平均值(图4-2)。当处理平均值时,我们可以用更专业的函数得到相同的结果,接下来我们会说到。
Example 4-7 Per-key average with reduceByKey() and mapValues() in Python
rdd.mapValues(lambda x:(x,1)).reduceByKey(lambda x,y:(x[0] + y[0],x[1] + y[1]))
Example 4-8 Per-key average with reduceByKey() and mapValues() in Scala
rdd.mapValues(x=>(x,1)).reduceByKey((x,y)=>(x._1 + y._1, x._2 + y._2))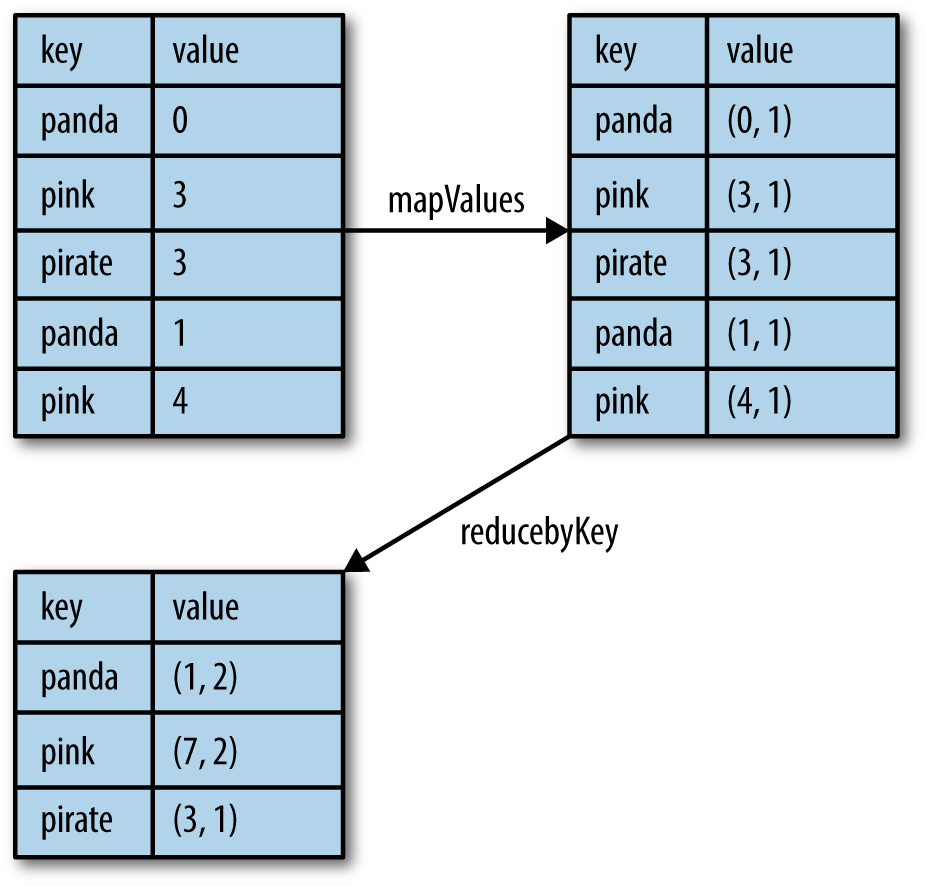
Tip
Those familiar with the combiner concept from MapReduce should note that calling reduceByKey()and foldByKey() will automatically perform combining locally on each machine before computing global totals for each key. The user does not need to specify a combiner. The more general combineByKey() interface allows you to customize combining behavior.
注意:
这些熟悉MapReduce中组合器概念的人应该注意到,调用reduceByKey()和 foldByKey() 将自动执行每台机器上的组合,再计算整个系统中每个键的总值。用户不需要指定一个combiner。更一般的combineByKey()接口允许用户自定义组合的行为。
We can use a similar approach in Examples 4-9 through 4-11 to also implement the classic distributed word count problem. We will use flatMap() from the previous chapter so that we can produce a pair RDD of words and the number 1 and then sum together all of the words using reduceByKey() as in Examples 4-7 and 4-8.
我们可以用例4-9到4-11类似的方法,实现经典的分布式的word count问题。我们将使用上一章讲的flatMap()来产生 字的pair RDD 和 数字1,然后加在一起用reduceByKey(),和例4-7和4-8一样。
Example 4-9. Word Count in Python
rdd.sc.textFile("s3://...")
words = rdd.flatMap(lambda x:x.split(" "))
result = words.map(lambda x:(x,1)).reduceByKey(lambda x, y: x+y)
Example 4-10 Word Count in Scala
val input = sc.textFile("s3://...")
val words = input.flatMap(x => x.split(" "))
val result = words.map(x => (x,1).reduceByKey((x,y) => x + y))
Example 4-11 Word count in Java
JavaRDD<String> input = sc.textFile("s3://...")
JavaRDD<String> words = rdd.flatMap(new FlatMapFunction<String, String>() {
public Iterable<String> call(String x) { return Arrays.asList(x.split(" ")); }
});
JavaPairRDD<String, Integer> result = words.mapToPair(
new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String x) { return new Tuple2(x, 1); }
}).reduceByKey(
new Function2<Integer, Integer, Integer>() {
public Integer call(Integer a, Integer b) { return a + b; }
});Tip
We can actually implement word count even faster by using the countByValue() function on the first RDD: input.flatMap(x => x.split(" ")).countByValue().
我们实际上可以用countByValue() 函数来使word count 更快:
input.flatMap(x => x.split(" ")).countByValue()
combineByKey() is the most general of the per-key aggregation functions. Most of the other per-key combiners are implemented using it. Like aggregate(), combineByKey() allows the user to return values that are not the same type as our input data.
combineByKey() 是最通用的per-key 聚合函数。大多数per-key combiners 都是用它实现的。像 aggregate(), combineByKey() 允许用户返回values和我们输入类型不一样的类型。
To understand combineByKey(), it’s useful to think of how it handles each element it processes. As combineByKey() goes through the elements in a partition, each element either has a key it hasn’t seen before or has the same key as a previous element.
为了理解combineByKey(),想想它是如何处理每个元素是很有用的。因为 combineByKey()在一个分区中穿行,每个元素要么有个key它还没见过,要么之前已经出现过相同的key了。
If it’s a new element, combineByKey() uses a function we provide, called createCombiner(), to create the initial value for the accumulator on that key. It’s important to note that this happens the first time a key is found in each partition, rather than only the first time the key is found in the RDD.
如果它是一个新元素,combineByKey()用我们提供的函数,叫createCombiner(),来创造一个该键累加器的初始值。重要的是要注意,这是在每个分区中第一次发现一个key时调用的,而不是在RDD中第一次发现新元素。
If it is a value we have seen before while processing that partition, it will instead use the provided function, mergeValue(), with the current value for the accumulator for that key and the new value.
如果是一个我们已经在该分区中处理过的value,它会对该key的累加值和当前值用另一个函数mergeValue()。
Since each partition is processed independently, we can have multiple accumulators for the same key. When we are merging the results from each partition, if two or more partitions have an accumulator for the same key we merge the accumulators using the user-supplied mergeCombiners() function.
由于每个分区是独立运算的,对同一个key我们可以有多个累加器。当我们从每个partition中merging结果时,如果2个或更多的分区对同一个key有一个累加器,我们用用户提供的mergeCombiners()函数来合并累加器。
Tip
We can disable map-side aggregation in combineByKey() if we know that our data won’t benefit from it. For example, groupByKey() disables map-side aggregation as the aggregation function (appending to a list) does not save any space. If we want to disable map-side combines, we need to specify the partitioner; for now you can just use the partitioner on the source RDD by passing rdd.partitioner.
注意:
我们可以在combineByKey()中禁用map端的聚合,如果我们知道我们的数据不会从中受益的话。例如,groupByKey() 禁用map端的聚合作为聚合函数(追加到列表中)不保存任何空间。如果我们想禁用map端的组合,我们需要指定分区,现在你可以通过传递rdd.partitioner来使用source RDD上的partitioner。
Since combineByKey() has a lot of different parameters it is a great candidate for an explanatory example. To better illustrate how combineByKey() works, we will look at computing the average value for each key, as shown in Examples 4-12 through 4-14 and illustrated in Figure 4-3.
因为combineByKey()有许多参数,它可以有很多例子。为了更好地说明combineByKey()是如何工作的,我们将着眼于计算每个键的平均值,如实施例4-12至4-14和图4-3所示。
Example 4-12. Per-key average using combineByKey() in Python
sumCount = nums.combineByKey(
(lambda x:(x,1)),
(lambda x,y :(x[0] + y,x[1] +1)),
(lambda x,y:(x[0] + y[0], x[1] + y[1]))
sumCount.map(lambda key,xy:(key, xy[0]/xy[1])).collectAsMap()
Example 4-13. Per-key average using combineByKey() in Scala
val result = input.combineByKey(
(v) => (v,1),
(acc:(Int, Int),v) => (acc._1 +v, acc._2 +1),
(acc1:(Int,Int),acc2:(Int,Int)) => (acc._1 + acc2._1,acc1._2,acc2._2)
).map{case (key,value) => value._1 / value._2.toFloat)}
result.collectAsMap().map(println(_))
Example 4-14. Per-key average using combineByKey() in Java
public static class AvgCount implements Serializable {
public AvgCount(int total, int num) {
total_ = total;
num_ = num; }
public int total_;
public int num_;
public float avg() {
return total_ / (float) num_; }
}
Function<Integer, AvgCount> createAcc = new Function<Integer, AvgCount>() {
public AvgCount call(Integer x) {
return new AvgCount(x, 1);
}
};
Function2<AvgCount, Integer, AvgCount> addAndCount =
new Function2<AvgCount, Integer, AvgCount>() {
public AvgCount call(AvgCount a, Integer x) {
a.total_ += x;
a.num_ += 1;
return a;
}
};
Function2<AvgCount, AvgCount, AvgCount> combine =
new Function2<AvgCount, AvgCount, AvgCount>() {
public AvgCount call(AvgCount a, AvgCount b) {
a.total_ += b.total_;
a.num_ += b.num_;
return a;
}
};
AvgCount initial = new AvgCount(0,0);
JavaPairRDD<String, AvgCount> avgCounts =
nums.combineByKey(createAcc, addAndCount, combine);
Map<String, AvgCount> countMap = avgCounts.collectAsMap();
for (Entry<String, AvgCount> entry : countMap.entrySet()) {
System.out.println(entry.getKey() + ":" + entry.getValue().avg());
}
There are many options for combining our data by key. Most of them are implemented on top of combineByKey() but provide a simpler interface. In any case, using one of the specialized aggregation functions in Spark can be much faster than the naive approach of grouping our data and then reducing it.
有许多方法来通过key组合我们的数据。大多数是在combineByKey的基础上实现的,但提供了一个简单的接口。在任何情况下,在Spark中用专门的聚合函数比幼稚的:先分组再合并方法 快很多。
Tuning the level of parallelism
So far we have talked about how all of our transformations are distributed, but we have not really looked at how Spark decides how to split up the work. Every RDD has a fixed number of partitions that determine the degree of parallelism to use when executing operations on the RDD.
调谐并行的等级
到目前为止,我们已经谈到了我们所有的transmations 是分布的,但是我们还没有真正的了解Spark是如何分割的。当在RDD上发生操作时,每个RDD有一个固定的分区数来决定并行的程度。
When performing aggregations or grouping operations, we can ask Spark to use a specific number of partitions. Spark will always try to infer a sensible default value based on the size of your cluster, but in some cases you will want to tune the level of parallelism for better performance.
当进行聚合或分组操作时,我们请求Spark使用一个具体的分区数。Spark总是会尝试推断基于集群大小的合理的默认值,但在某些情况下,你将要调整并行度以获得更好的性能。
Most of the operators discussed in this chapter accept a second parameter giving the number of partitions to use when creating the grouped or aggregated RDD, as shown in Examples 4-15 and 4-16.
本章讨论的大多数操作接收一个第二参数来提供使用的分区数,当创造分组或聚合的RDD时使用,如例4-15和4-16所示。
Example 4-15. reduceByKey() with custom parallelism in Python
data = [("a", 3), ("b", 4), ("a", 1)]
sc.parallelize(data).reduceByKey(lambda x, y: x + y) # Default parallelism
sc.parallelize(data).reduceByKey(lambda x, y: x + y, 10) # Custom parallelism
Example 4-16. reduceByKey() with custom parallelism in Scala
val data = Seq(("a", 3), ("b", 4), ("a", 1))
sc.parallelize(data).reduceByKey((x, y) => x + y) // Default parallelism
sc.parallelize(data).reduceByKey((x, y) => x + y,10) // Custom parallelismSometimes, we want to change the partitioning of an RDD outside the context of grouping and aggregation operations. For those cases, Spark provides the repartition() function, which shuffles the data across the network to create a new set of partitions. Keep in mind that repartitioning your data is a fairly expensive operation. Spark also has an optimized version of repartition() calledcoalesce() that allows avoiding data movement, but only if you are decreasing the number of RDD partitions. To know whether you can safely call coalesce(), you can check the size of the RDD using rdd.partitions.size() in Java/Scala and rdd.getNumPartitions() in Python and make sure that you are coalescing it to fewer partitions than it currently has.
有时,我们想要在分组和聚合的操作以外改变RDD的分区。对于这些情况,Spark提供了repartition()函数,它shuffle了整个网络中的数据来创造一个新的分区数据集。记住:**将你的数据重分区是一个相当昂贵的操作。**Spark也有repartition()的升级操作:coalesce(),它允许避免数据移动,但只有当你减少分区数的时候有用。你可以检查分区数,Java/Scala中使用rdd.partitions.size(),Python中使用rdd.getNumPartitions(),并确保你是在把原来的分区合并为比现在更少的分区。
Grouping Data
With keyed data a common use case is grouping our data by key, for example, viewing all of a customer’s orders together.
对有键值数据的一种常用操作就是将我们的数据按key分组,例如,查看一个用户的所有订单记录。
If our data is already keyed in the way we want, groupByKey() will group our data using the key in our RDD. On an RDD consisting of keys of type K and values of type V, we get back an RDD of type [K,Iterable[V]].
如果我们的数据已经是按我们想要的方式得到的键值数据,那么我们可以用groupByKey()来分组数据,输入一个RDD,key的类型是K,value的类型是V,返回的是一个 类型为[K,Iterable[V]]的RDD。
groupBy() works on unpaired data or data where we want to use a different condition besides equality on the current key. It takes a function that it applies to every element in the source RDD and uses the result to determine the key.
当数据不是成键值对出现或者我们想在现有的key上使用不同的条件时,可以用groupBy()。该函数提供源RDD中的每个元素并且用该结果来确定key。
Tip
If you find yourself writing code where you groupBy() and then use a reduce() or fold() on the values, you can probably achieve the same result more efficiently by using one of the per-key aggregation functions. Rather than reducing the RDD to an in-memory value, we reduce the data per key and get back an RDD with the reduced values corresponding to each key. For example, rdd.reduceByKey(func) produces the same RDD as rdd.groupByKey().mapValues(value=>value.reduce(func)) but is more efficient as it avoids the step of creating a list of values for each key.
注意:
如果你发现你写的代码中有groupBy() 并且在用reduce() 或 fold()处理values,你也许可以通过使用per-key聚合函数,更高效的达到同样的效果。我们将每个key的数据reduce,然后返回一个reduce后的RDD,而不是将RDD在内存中合并。例如,rdd.reduceByKey(func) 和rdd.groupByKey().mapValues(value=>value.reduce(func)) 的效果相同,但是比后者更有效率,因为它避免了为每个key创建一个values的list这个步骤。
In addition to grouping data from a single RDD, we can group data sharing the same key from multiple RDDs using a function called cogroup().cogroup() over two RDDs sharing the same key type, K, with the respective value types V and W gives us back RDD[(K, (Iterable[V],Iterable[W]))]. If one of the RDDs doesn’t have elements for a given key that is present in the other RDD, the corresponding Iterable is simply empty. cogroup() gives us the power to group data from multiple RDDs.
除了从一个RDD中对数据进行分组,我们还能用cogroup()从多个RDD中共享相同的键从而进行分组。cogroup() 对两个及以上的RDDs共享相同的key type,K,返回给RDD各自的值V和W,即RDD[(K, (Iterable[V],Iterable[W]))]。如果其中的一个RDD没有其他的RDD中给定的键,相应的迭代式就是空的。cogroup() 可以让我们从多个RDD中来进行分组。
cogroup() is used as a building block for the joins we discuss in the next section.
cogroup()被用来作为一个构建join的连接,我们将在下一小节中讨论、
Joins
Some of the most useful operations we get with keyed data comes from using it together with other keyed data. Joining data together is probably one of the most common operations on a pair RDD, and we have a full range of options including right and left outer joins, cross joins, and inner joins.
连接操作是最有用的操作之一,join包括 right outer join, left outer join, cross join 和inner join。
The simple join operator is an inner join. Only keys that are present in both pair RDDs are output. When there are multiple values for the same key in one of the inputs, the resulting pair RDD will have an entry for every possible pair of values with that key from the two input RDDs. A simple way to understand this is by looking at Example 4-17.
inner join 是最简单的连接操作。只返回两个pair RDD中公有的键。当一个输入RDD中一个键有多个值时,输出的RDD将会对每个key的值产生一条记录。该记录中有两个输入RDD中的值。例4-17可以看出来。
Example 4-17. Scala shell inner join
storeAddress = {
(Store("Ritual"), "1026 Valencia St"), (Store("Philz"), "748 Van Ness Ave"),
(Store("Philz"), "3101 24th St"), (Store("Starbucks"), "Seattle")}
storeRating = {
(Store("Ritual"), 4.9), (Store("Philz"), 4.8))}
storeAddress.join(storeRating) == {
(Store("Ritual"), ("1026 Valencia St", 4.9)),
(Store("Philz"), ("748 Van Ness Ave", 4.8)),
(Store("Philz"), ("3101 24th St", 4.8))}
Sometimes we don’t need the key to be present in both RDDs to want it in our result. For example, if we were joining customer information with recommendations we might not want to drop customers if there were not any recommendations yet. leftOuterJoin(other) and rightOuterJoin(other) both join pair RDDs together by key, where one of the pair RDDs can be missing the key.
有时,我们并不需要结果中出现的key是两个RDD中公有的。例如,如果我们将用户的信息和推荐作join时,我们不希望扔掉没有推荐的用户。leftOuterJoin(other) 和 rightOuterJoin(other)都可以通过key产生pair RDD,输入RDD中的一个的key将会忽略。
With **leftOuterJoin()**the resulting pair RDD has entries for each key in the source RDD. The value associated with each key in the result is a tuple of the value from the source RDD and an Option (or Optional in Java) for the value from the other pair RDD. In Python, if a value isn’t present None is used; and if the value is present the regular value, without any wrapper, is used. As with join(), we can have multiple entries for each key; when this occurs, we get the Cartesian product between the two lists of values.
leftOuterJoin()的结果中含有源RDD的每个key。与结果中的每个key关联的值是源RDD的值和另一个RDD的值组成的tuple。在Python中,如果没有值,显示的是None,如果该值是正常的格式,就被使用了。与join()方法相比,对每个key,我们有多条entries;当这种情况发生时,我们说,我们得到了两个值组成的列表的笛卡尔积。
Tip
Optional is part of Google’s Guava library and represents a possibly missing value. We can check isPresent() to see if it’s set, and get() will return the contained instance provided data is present.
rightOuterJoin() is almost identical toleftOuterJoin() except the key must be present in the other RDD and the tuple has an option for the source rather than the other RDD.
We can revisit Example 4-17 and do a leftOuterJoin() and a rightOuterJoin() between the two pair RDDs we used to illustrate join() in Example 4-18.
注意:
可选的是一部分的谷歌的Guava库,并可以表示缺失值。我们可以用isPresent()函数来看,如果它被设置的话,并且会告诉你所包含的示例所提供的的数据是否存在。
rightOuterJoin() 和leftOuterJoin() 基本是相同的,区别是key必须是另一个RDD中存在的,tuple里是对源RDD的值的选项。
我们可以用leftOuterJoin() 和rightOuterJoin()重做一遍例4-17,如例4-18所示。
Example 4-18. leftOuterJoin() and rightOuterJoin()
storeAddress.leftOuterJoin(storeRating) ==
{(Store("Ritual"),("1026 Valencia St",Some(4.9))),
(Store("Starbucks"),("Seattle",None)),
(Store("Philz"),("748 Van Ness Ave",Some(4.8))),
(Store("Philz"),("3101 24th St",Some(4.8)))}
storeAddress.rightOuterJoin(storeRating) ==
{(Store("Ritual"),(Some("1026 Valencia St"),4.9)),
(Store("Philz"),(Some("748 Van Ness Ave"),4.8)),
(Store("Philz"), (Some("3101 24th St"),4.8))}Sorting Data
Having sorted data is quite useful in many cases, especially when you’re producing downstream output. We can sort an RDD with key/value pairs provided that there is an ordering defined on the key. Once we have sorted our data, any subsequent call on the sorted data to collect() or save() will result in ordered data.
得到排序后的数据在许多情况下是很有用的,特别是你想产生后续输出时。我们可以用提供的key/value对来对一个RDD排序,前提是key已经有一个定义好的规则。一旦我们对我们的数据排序,对排完序的任何后续调用来collect()还是save()都会产生有序数据。
Since we often want our RDDs in the reverse order, the sortByKey() function takes a parameter called ascending indicating whether we want it in ascending order (it defaults to true). Sometimes we want a different sort order entirely, and to support this we can provide our own comparison function. In Examples 4-19 through 4-21, we will sort our RDD by converting the integers to strings and using the string comparison functions.
由于我们经常希望我们的RDDs倒序排列, sortByKey()函数有一个参数叫ascending,它来指明我们是否希望进行升序(默认是true)。有时候,我们希望有一个完全不同的排序方法,我们可以使用自己的比较函数。如例4-19到4-21,我们将会通过转换整数到字符串并且用字符串比较函数来进行排序。
Example 4-19. Custom sort order in Python, sorting integers as if strings
rdd.sortByKey(ascending=True, numPartitions=None, keyfunc = lambda x: str(x))
Example 4-20. Custom sort order in Scala, sorting integers as if strings
val input: RDD[(Int, Venue)] = ...
implicit val sortIntegersByString = new Ordering[Int] {
override def compare(a: Int, b: Int) = a.toString.compare(b.toString)
}
rdd.sortByKey()
Example 4-21. Custom sort order in Java, sorting integers as if strings
class IntegerComparator implements Comparator<Integer> {
public int compare(Integer a, Integer b) {
return String.valueOf(a).compareTo(String.valueOf(b))
}
}
rdd.sortByKey(comp)Actions Available on Pair RDDs
As with the transformations, all of the traditional actions available on the base RDD are also available on pair RDDs. Some additional actions are available on pair RDDs to take advantage of the key/value nature of the data; these are listed in Table 4-3.
和转换操作一样,所有基础RDD的action操作也可以用在pair RDD上。可以利用pair RDD的key/value特性得到一些额外的actions。
| Function | Description | Example | Result |
|---|---|---|---|
| countByKey() | Count the number of elements for each key. | rdd.countByKey() | {(1,1),(3,2)} |
| collectAsMap() | Collect the result as a map to provide easy lookup. | rdd.collectAsMap() | Map{(1,2),(3,4),(3,6)} |
| lookup(key) | Return all values associated with the provided key. | rdd.lookup(3) | [4,6] |
还有一些保存RDD的action将在下一章讲。
Data Partitioning (Advanced)
数据分区(提升)
The final Spark feature we will discuss in this chapter is how to control datasets’ partitioning across nodes. In a distributed program, communication is very expensive, so laying out data to minimize network traffic can greatly improve performance. Much like how a single-node program needs to choose the right data structure for a collection of records, Spark programs can choose to control their RDDs’ partitioning to reduce communication. Partitioning will not be helpful in all applications—for example, if a given RDD is scanned only once, there is no point in partitioning it in advance. It is useful only when a dataset is reused multiple times in key-oriented operations such as joins. We will give some examples shortly.
我们在这一章中最后谈论的Spark的特性是如何控制数据集的跨节点分区。在一个分布式程序中,通信的代价是非常昂贵的,所以合理布局我们的数据以使网络流量最小,可以大大提高性能。就像单机程序需要选择合适的数据结构来存储记录,Spark程序也要选择控制他们的RDD的分区来减少通信。分区不会对所有的程序都有所帮助,比如,如果一个RDD只扫描一次,那么事先划分分区是没有意义的。这只有当一个数据集重复使用多次以key为导向的操作,如join时,才有用。我们将会给些例子。
Spark’s partitioning is available on all RDDs of key/value pairs, and causes the system to group elements based on a function of each key. Although Spark does not give explicit control of which worker node each key goes to (partly because the system is designed to work even if specific nodes fail), it lets the program ensure that a set of keys will appear together on some node. For example, you might choose to hash-partition an RDD into 100 partitions so that keys that have the same hash value modulo 100 appear on the same node. Or you might range-partition the RDD into sorted ranges of keys so that elements with keys in the same range appear on the same node.
Spark的分区可以对所有的key/value键值对产生作用,也对基于每个key的函数产生的分组有用。虽然Spark并没有明确指明哪个node计算哪个key(部分原因是因为该系统的设计,万一特定的节点没有工作的)。它确保程序会在某些节点上运行键值对。例如,你可以选择将一个RDD散列到100分区,使具有相同hash值的模发现在相同的节点上。或者你也已随机将RDD分区到一个key有序的范围,这样在相同范围的keys的元素出现在同一个节点上。
As a simple example, consider an application that keeps a large table of user information in memory—say, an RDD of (UserID, UserInfo) pairs, where UserInfo contains a list of topics the user is subscribed to. The application periodically combines this table with a smaller file representing events that happened in the past five minutes—say, a table of (UserID, LinkInfo) pairs for users who have clicked a link on a website in those five minutes. For example, we may wish to count how many users visited a link that was not to one of their subscribed topics. We can perform this combination with Spark’s join() operation, which can be used to group the UserInfo and LinkInfo pairs for each UserID by key. Our application would look like Example 4-22.
举一个简单的例子,考虑一个应用程序,在内存中放一个巨大的用户信息表,也就是说,一个(UserID,UserInfo)的pair RDD,UserInfo 包括一个用户订阅列表。















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









