







前面文章所使用的方法时间主要花费在定位结点的m_pSibling上面,我们试着在这方面去做优化。
我们还是分为两步:
第一步仍然是复制原始链表上的每个结点N,并创建N’,然后把这些创建出来的结点链接起来。这一次,我们把新创建的每个结点N’链接在原先结点N的后面。
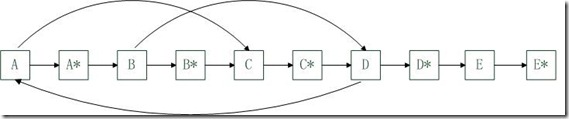
代码如下:
void CloneNodes(ComplexListNode *pHead) {
ComplexListNode* pNode = pHead;
while(pNode != NULL)
{
ComplexListNode* pCloned = new ComplexListNode();
pCloned->m_nValue = pNode->m_nValue;
pCloned->m_pNext = pNode->m_pNext;
pCloned->m_pSibling = NULL;
pNode->m_pNext = pCloned;
pNode = pCloned->m_pNext;
}
}
第二步是设置我们复制出来的链表上的结点的m_pSibling。假设原始链表上的N的m_pSibling指向结点S,那么其对应复制出来的N’是N->m_pNext,同样S’也是S->m_pNext。这就是我们在上一步中把每个结点复制出来的结点链接在原始结点后面的原因。有了这样的链接方式,我们就能在O(1)中就能找到每个结点的m_pSibling了。代码如下:
void ConnectSiblingNodes(ComplexListNode* pHead)
{
ComplexListNode* pNode = pHead;
while(pNode != NULL)
{
ComplexListNode* pCloned = pNode->m_pNext;
if(pNode->m_pSibling != NULL)
{
pCloned->m_pSibling = pNode->m_pSibling->m_pNext;
}
pNode = pCloned->m_pNext;
}
}
第三步是把这个长链表拆分成两个:把奇数位置的结点链接起来就是原始链表,把偶数位置的结点链接出来就是复制出来的链表。要实现这一步,也不是很难的事情。其对应的代码如下:
ComplexListNode* ReconnectNodes(ComplexListNode* pHead){
ComplexListNode* pNode = pHead;
ComplexListNode* pClonedHead = NULL;
ComplexListNode* pClonedNode = NULL;
if(pNode != NULL)
{
pClonedHead = pClonedNode = pNode->m_pNext;
pNode->m_pNext = pClonedNode->m_pNext;
pNode = pNode->m_pNext;
}
while(pNode != NULL) {
pClonedNode->m_pNext = pNode->m_pNext;
pClonedNode = pClonedNode->m_pNext;
pNode->m_pNext = pClonedNode->m_pNext;
pNode = pNode->m_pNext;
}
return pClonedHead;
}我们把上面三步合起来,就是复制链表的完整过程:
ComplexListNode* Clone(ComplexListNode *pHead) {
CloneNodes(pHead);
ConnectSiblingNodes(pHead);
ComplexListNode *pClonedHead = ReconnectNodes(pHead);
return pClonedHead;
}














 1931
1931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









