









非监督学习:
非监督学习和监督学习的最大区别是不需要先验知识,无需人为干涉。
Kmeans -----笔者按照自己的理解写了kmeans也许不对,全当写轮子练手。
Kmeans计算的步骤:
1、 在数据集中随机选择K个聚类中心,K<len(data);
2、 计算每个点到聚类中心的距离,用一个数组储存(len(data),k),如果距离K1(第一个聚类中心)较近的点就标记为1(这里笔者距离阈值为15),距其它聚类中心的标记依次类推
3、 重新计算聚类中心(以标记(i=1,2,3……)对应的数据点的均值作为新的聚类中心)
重复
2
、
3
,通过设定迭代次数或者当聚类中心稳定时来终止程序。
Kmeans 代码:
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
def kmean(data,k,iternum):
# k_center 初始化,在样本m中随机选择k个聚类中心
index1=np.random.randint(0,len(data),(k,1)) #m*n,k<=m
k_center=np.zeros((k,data.shape[1]))
for i in range(len(index1)):
k_center[i]=data[index1[i]]
# 迭代
for i in range(iternum):
distance=np.zeros((len(data),k))
for i in range(k):
for j in range(len(data)):
distance[j,i]=np.linalg.norm(data[j]-k_center[i])
# index2=[]
for i in range(k):
# index2.append(np.where(error[:,i]<15))
k_center[i]=np.sum(data[np.where(distance[:,i]<15)[0],:],axis=0)/len(np.where(distance[:,i]<15)[0])
#注意,np.where 返回的是一个元组
for i in range(iternum):
distance=np.zeros((len(data),k))
for i in range(k):
for j in range(len(data)):
distance[j,i]=np.linalg.norm(data[j]-k_center[i])
return k_center
data=np.array([[ 12, 34],
[234, 44],
[ 21, 34],
[ 12, 2],
[10,8],
[19,20],
[30,10],
[100,232]])
center=kmean(data,2,100)
plt.plot(data[:,0],data[:,1],'r+',markersize=12)
plt.plot(center[:,0],center[:,1],'g^')PCA- 算法原理很简单
其实质:旋转坐标系,将坐标系旋转到方差大的方向。
步骤:
1、首先数据中心化,即是去均值,目的是中心矩能反应数据的离散程序。
2、计算中心化后的协方差矩阵
3、计算协方差矩阵的特征值和特征向量
4、将特征值由大到小的排列,将维后的维度k取决于特征值的贡献率,如果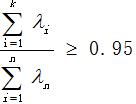
5、降维后的数据为:
PCA特点及其作用:(遥感中的K-L变换)
1、 无损变换,变换前后能量保持不变---图像压缩
2、 可逆变换,具有反变换---图像复原
3、 变换后的数据正交---去相关
4、 第1主分量大于85%,前三个主分量之和大于95%--特征提取
5、 能量主要在低频,前三个主分量以能量为主,其它主分量是噪声------去噪
总之,PCA的作用是压缩数据和增加类别的可分性。
pca 代码:
# -*- coding: utf-8 -*-
import numpy as np
def pca(data):#data:m*n
data=np.transpose(data)#变成 特征*样本
mean_data=data-np.average(data,axis=0)#中心化,中心矩
cov_matix=np.cov(mean_data)#协方差,n*n
u,d,v=np.linalg.svd(cov_matix)#
sum=0
index=0
for i in range(len(d)):
sum+=d[i]
contribution=sum/np.sum(d)
if contribution>=0.95:
index=i
break
return np.transpose(u[:,:index+1])@data#切片的上界要减1
data=np.array([[ 12, 34],
[234, 44],
[ 21, 34],
[ 12, 2],
[10,8],
[19,20],
[30,10],
[100,232]])
z=pca(data)















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









