






PCA-kmeans
pca与kmeans都是无监督算法。pca主要用于数据的降维及可视化,kmeans可以对相似的特征进行聚类。
pca处理的二维矩阵数据,行数代表样本的个数,列数代表特征的个数,特征的个数等于维数。
我这里准备了711个土壤体积含水量数据,特征有12个即1~12月的含水量。
部分数据见下图:
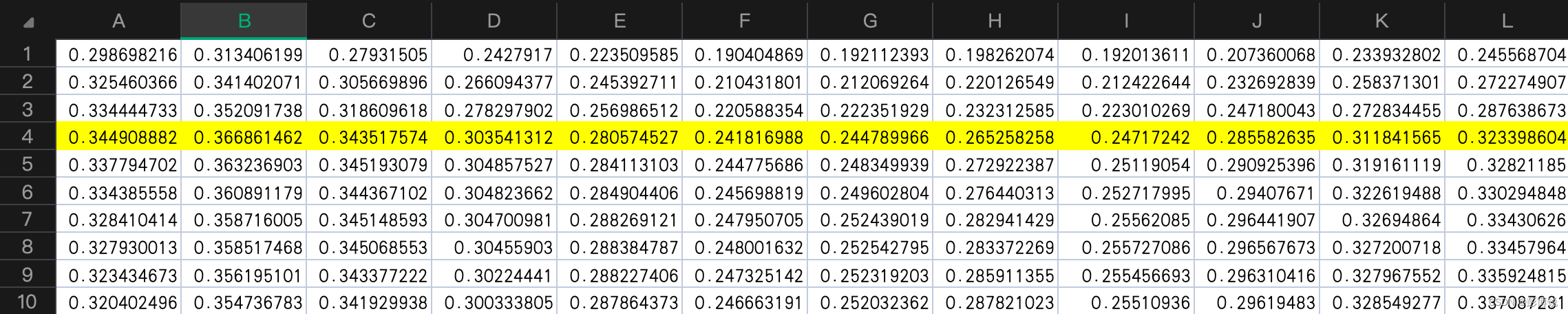
1、读入excel数据转为二维矩阵
此py文件名为read_xlsx.py
读入上述准备的excel数据转为二维矩阵。
import openpyxl
def read_excel(file_path):
# 打开Excel文件
workbook = openpyxl.load_workbook(file_path)
# 获取第一个工作表
sheet = workbook.active
# 获取行数和列数
rows = sheet.max_row
cols = sheet.max_column
# 初始化二维数组
data = []
# 逐行读取数据并添加到二维数组中
for i in range(1, rows + 1):
row_data = []
for j in range(1, cols + 1):
cell_val = sheet.cell(row=i, column=j).value
row_data.append(cell_val)
data.append(row_data)
# 关闭Excel文件
workbook.close()
return data
2、PCA降维
此py文件名为pca_process.py。
由于特征数比较少,我发现一个特征的可解释性方差就达到了99%,为了后续可视化,我采取了降维到2个特征。不确定降维的维数可以画学习曲线。
from sklearn.decomposition import PCA
from read_xlsx import read_excel
data = read_excel('./data.xlsx')
# 创建PCA对象,指定降维后的纬度
pca = PCA(n_components=2)
# 查看可解释性方差
pca.fit(data)
# 查看每个主成分解释的方差比例
explained_variance_ratio = pca.explained_variance_ratio_
# 打印结果
# print("每个主成分解释的方差比例:")
# print(explained_variance_ratio) # [0.99167984 0.006052 ] 说明一个特征就能很好的代表原始数据
# 对数据进行PCA处理
pca_result = pca.fit_transform(data)
# 输出降维后的结果
# print(pca_result)
3、确定kmeans簇的数量
此py文件名为elbow_method.py。
有几簇就代表有几类。这里采用肘部法来确定簇的数量。选择转折点作为簇的数量。
# 确定kmeans簇的数量
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from pca_process import pca_result
# 创建一个列表保存不同簇数量的成本
costs = []
for i in range(1, 11):
kmeans = KMeans(n_clusters=i)
kmeans.fit(pca_result)
costs.append(kmeans.inertia_)
# 绘制肘部法图形 最终发现选择2簇比较合理
plt.plot(range(1, 11), costs, marker='o')
plt.title('Elbow Method for Optimal K')
plt.xlabel('Number of Clusters')
plt.ylabel('Cost (Inertia)')
plt.show()
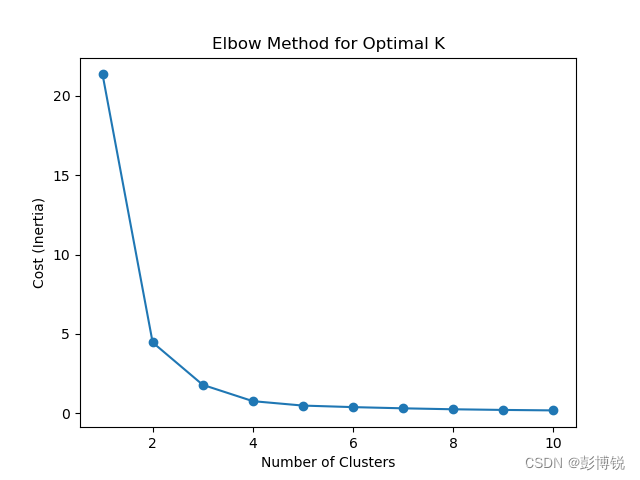
可以看到2处有明显的转折,所以选择2作为簇的数量。
4、kmeans聚类处理
此py名称为kmeans_process.py。
特征比较相似的点会聚集在一块。
pca降维到二维进行可视化,然后利用kmeans给点着色。
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from pca_process import pca_result
# 创建K均值聚类对象,选择聚类簇的数量
kmeans = KMeans(n_clusters=2)
# 对PCA降维后的数据进行K均值聚类
kmeans_result = kmeans.fit_predict(pca_result)
# 获取每个数据点的簇分配信息
labels = kmeans.labels_
# 打印每个数据点所属的簇
# for i, label in enumerate(labels):
# print(f"Data point {i+1} is assigned to cluster {label}")
# 绘制K均值聚类结果的散点图,通过kmeans的结果来着色数据点
plt.figure(figsize=(15, 6))
plt.scatter(pca_result[:, 0], pca_result[:, 1], c=kmeans_result, cmap='viridis', edgecolor='k', s=50)
plt.title('K-means Clustering after PCA')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
# 标记每个点的原始数据,避免标签重叠
for i, txt in enumerate(labels):
# if i % 2 == 0: # 仅对偶数编号的点添加注释
plt.annotate(f'{i + 1}', (pca_result[i, 0], pca_result[i, 1]),
textcoords="offset points", xytext=(5, -5), arrowprops=dict(arrowstyle='->'))
plt.show()
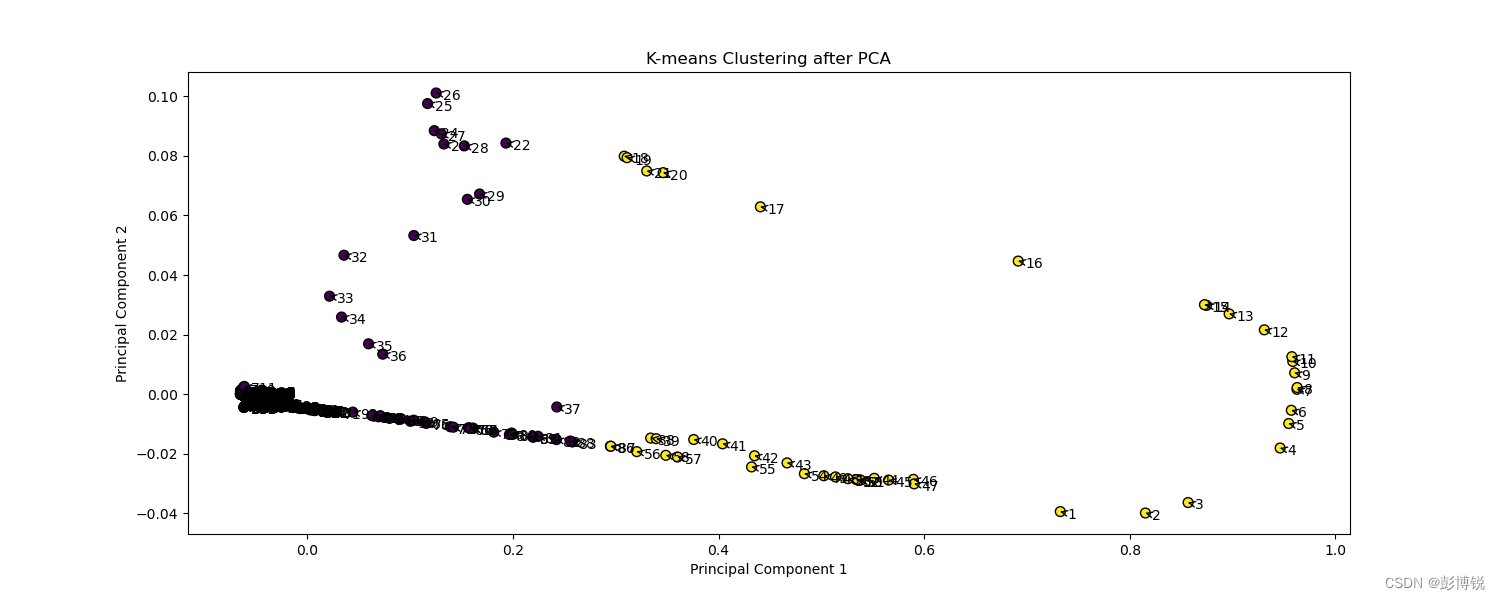
可以看到右边的4号点、中间的17号点、左边的32点相差较大,所以它们的特征也就会相差较大。而4、5、6号点这种比较接近的点特征就比较相似。
5、特征分析
此py文件名为data_plot.py。
我将4、17、32号点的年土壤体积含水量绘制出来,进而看看它们之间特征有些什么不同。
import matplotlib.pyplot as plt
from read_xlsx import read_excel
data = read_excel('./data.xlsx')
# 示例数据
x_values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
y_values = data[3]
y1_values = data[31]
y2_values = data[16]
# 绘制折线图
plt.plot(x_values, y_values, label='4', marker='o', linestyle='-', color='blue')
plt.plot(x_values, y1_values, label='32', marker='o', linestyle='-', color='red')
plt.plot(x_values, y2_values, label='17', marker='o', linestyle='-', color='green')
# 添加标题和标签
plt.title('Line Chart Example')
plt.xlabel('month')
plt.ylabel('soil water content')
# 添加图例
plt.legend()
# 显示图形
plt.show()
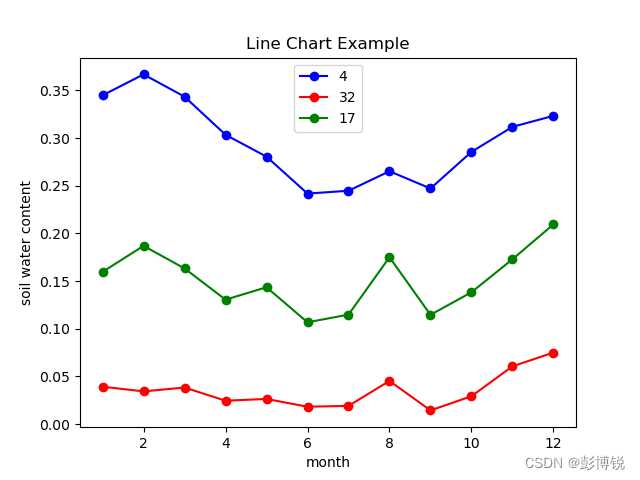
可见4号点整体含水量高,年际含水量变化大。32号点整体含水量低,年际变化量小。而17号点介于两者之间。符合之前pca降维后的情况。
















 2121
2121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











