










作为一个正常人 总会有日常需要访问的网站 可是每次有需求的时候再打开网站浏览图片总会觉得打开速度跟不上自己想要浏览的速度
特别是有些时候有的图片前面刷出来了 后面也刷出来了 但是中间就卡住不动了,那么我这时候如果想要浏览全文就需要整个网页刷新一遍 费时,费精力 也浪费大把美好时光、
所以今天我们要做的就是爬虫爬取一个日常需要网站的指定模块的图片 这个网站就是 http://64je.com/
首先我们进入到网站,比如我打算爬取卡通动漫为例
通过分析呢 我发现动漫卡通这一块有好几百页 但是每一页有个规律就是
比如第一页是 http://64je.com/17/ 第二页是 http://64je.com/pic/17/p_2.html
也就是我们往后打算爬第几页的 url就是加上p_第几页
通过这个规律我们进入网站 然后选取模块,进入模块得到每张图片的准确链接这里我们为了方便选择了python的Scrapy 01_64je_spider.py
# -*- coding:utf-8 -*-
import scrapy
"""
1.打开 http://64je.com/pic/17/ 这里的17是卡通动漫模块,如果你要其他的相应的换掉就是
2.每一个下一页对应的 http://64je.com/pic/17/p_2.html 也就是p_几 获取这个准确的url并进去
3.spider 抓到的每个图片都是单独的 所以我希望你直接存为字典或者表
"""
# 这里的17对应的网站的动漫卡通模块
model = '17'
class MySpider(scrapy.Spider):
name = "MySpider"
# 初始化url 第一层爬虫要打开那些页面
start_urls=["http://64je.com/pic/"+model+"/"]
# 我要爬取多少层页面 start_urls添加2-x页
for x in xrange(2,10):
# 加入要爬取的页面
tmpurl = "http://64je.com/pic/"+model+"/p_%d.html"%x
start_urls.append(tmpurl)
def parse(self, response):
# 这里的每个 li 都是一个模块链接
mtab = response.xpath('/html/body/div[6]/div/ul/li')
for href in mtab:
# 找到模块的具体链接
full_url = 'http://64je.com'+href.css('li a::attr(href)').extract()[0]
yield scrapy.Request(full_url,callback=self.parse_question)
def parse_question(self, response):
# 找到模块进去每一页的具体图片地址
All_Page = []
mtab = response.css('.post img')
for href in mtab:
# 每一张图片的准确链接
full_url = href.css('::attr(src)').extract()[0]
All_Page.append(full_url)
# 爬虫记录数据
yield {
'title':response.xpath('/html/body/div[6]/div/h1/text()').extract()[0],
'data':response.url.split('/')[-1].split('.')[0],
'All_Page':str(All_Page),
}执行 scrapy runspider 01_64je_spider.py -o 64je.json
然后我们就得到64je.json 里面包含了我们要的网站 用csv的形式我显示一部分爬取到的数据
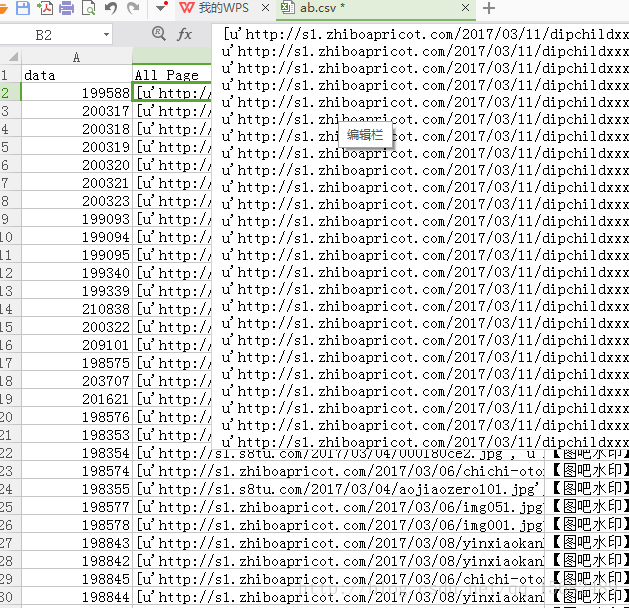
现在模块有了,下载连击,标题有了 接下来我们要做的就是去重和图片下载
去重用的 02_json_deal.py
# -*- coding:utf-8 -*-
import os
import json
"""
这个模块主要是用来去重的 为什么要去重呢
比如http://64je.com的亚洲模块很多因为标题太劲爆 其实网站由于种种原因换成了广告
也许这是他的盈利模式之一吧 所以我们要把重复的图片去掉
不一定全是广告 但是我们也不要那些重复的图片不是么 我选择去重 出现第二次的链接全部过滤
"""
# Scrapy取到给我的数据
all_tab = json.load(open('64je.json'))
# 重复出现的图片链接列表
Repeat_Tab = []
# 存放所有图片链接
All_Page_Tab = []
# 去重后存进这个表里面
New_Tab = []
for i in all_tab:
tmpdic = {'data':i['data'],'All_Page':[],'title':i['title']}
for j in eval(i['All_Page']):
# 如果已经出现过这个链接就说明出现重复
if j in All_Page_Tab:
if j not in Repeat_Tab:
Repeat_Tab.append(j)
else:
All_Page_Tab.append(j)
tmpdic['All_Page'].append(j)
# 如果每张图和以前的图都有重复 我想你这个模块是应该丢弃的
if len(tmpdic['All_Page']) != 0:
New_Tab.append(tmpdic)
json.dump(New_Tab,open('New_Tab.json','w'))经过一层过滤 现在我们得到了我们要下载的图片链接名单
不过经研究发现去这个网站去请求图片需要带上请求头,这个请求头呢 浏览器每次去访问的时候他都会给你一个cookie,如果网站发现同时两个一样的cookie在请求图片 那么就会返回给你404错误
所以我们要开启多线程下载,那么每个线程也要去获取自己独有的cookie和Host然后用这个请求头进行下载才是
这里我们用最直接简洁的方法,Selenium打开这个日常需求网站,就可以获得cookie啦,把cookie取下来然后就可以用urllib2.urlopen带上请求头的方式下载图片了
03_download.py 需要用到python的Selenium 我这里用的ChromeDriver 不知道什么是浏览器驱动器的自行百度
# -*- coding:utf-8 -*-
from selenium import webdriver
import threading
import urllib2
import json
import time
import os
# 用来保存图片的文件夹路径
# Save_Path = r'/Applications/XAMPP/xamppfiles/htdocs/media/qt5/seb55/dongman'
Save_Path = 'dongman'
if not os.path.exists(Save_Path):
os.makedirs(Save_Path)
# 下载图片 link-图片链接 folder-下载到的文件夹 savename-保存名字 send_headers-带上请求头 which_json-这个便于下载过程中围观是哪个线程下载的
def downPic(link,folder,savename,send_headers,which_json):
# 要下载到的地方文件夹不存在则建立
if not os.path.exists(folder):
os.makedirs(folder)
picture = os.path.join(folder,savename)
if not os.path.exists(picture):
# 开始请求
print 'Start req %s %s'%(link,savename)
req = urllib2.Request(link,headers=send_headers)
content = urllib2.urlopen(req,timeout=5).read()
# 为什么还要过一层 有些人运行这个只开一个线程 重复开多次
if not os.path.exists(picture):
with open(picture,'wb') as f:
f.write(content)
print '[+] Download %s Success %s'%(link,which_json)
# 开启线程去下载图片
def ThreadDown(which,Down_Tab):
# 如果之前的请求头可以用没有失误过,直接读取来用
which_json = str(which)+'_json.json'
send_headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Connection':'keep-alive',
'Cookie':'', # __cfduid=d59c72fbda5d57ee71a16780fc49928af1490423884
'Host':'s1', #.zhiboapricot.com
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
}
if os.path.exists(which_json):
send_headers = json.load(open(which_json))
else:
# 通过Selenium打开一张图片 来该着send_headers 这条线程就用这个请求头
driver = webdriver.Chrome()
# 放置图片刷出来太慢 获取不到cookie
def UntilFind():
cookies = []
try:
driver.get('http://s1.1280inke.com/2017/04/11/Fly08617.jpg')
time.sleep(2)
driver.refresh()
time.sleep(3)
cookies = driver.get_cookies()
if len(cookies) != 0:
return cookies
except:
return UntilFind()
driver_cookies = UntilFind()
send_headers['Cookie'] = driver_cookies[0]['name']+'='+driver_cookies[0]['value']
send_headers['Host'] = send_headers['Host']+driver_cookies[0]['domain']
# 获取了可以用的请求头后 浏览器就可以退出了
driver.quit()
json.dump(send_headers,open(which_json,'w'))
for i in Down_Tab:
for count,link in enumerate(i['All_Page']):
# 传参 图片链接 保存的文件夹名
savename = str(count)+'.'+link.split('.')[-1]
try:
downPic(link,os.path.join(Save_Path,i['data']),savename,send_headers,which_json)
except Exception as e:
print 'Download '+link+' Error '+str(e)+which_json
if os.path.exists(which_json):
os.remove(which_json)
# 把json中还没有下载的图片分成指定几个线程分配
# 要考虑到线程可能下载一半 我觉得四个线程不爽想开六个 那么分配肯定是要按
def Split_Thread():
New_Tab = json.load(open('New_Tab.json'))
# 打算开启的线程数量
Thread_Time = 3
# 切割基准
My_Split = int(len(New_Tab)/Thread_Time)
# 启动多线程
for x in range(Thread_Time):
if x != (Thread_Time-1):
i = My_Split*x
j = My_Split*(x+1)-1
# 最后一个线程嘛 承担着下载剩余的所有任务
else:
i = My_Split*x
j = int(len(New_Tab)-1)
# 开启多线程去下载
which = x+1
t1 = threading.Thread(target=ThreadDown,args=(which,New_Tab[i:j],))
t1.start()
Split_Thread()这里我简单的开了三个线程去下载,并且简单做了5秒超时和异常跳过,终端开启
pyhton 03_download.py
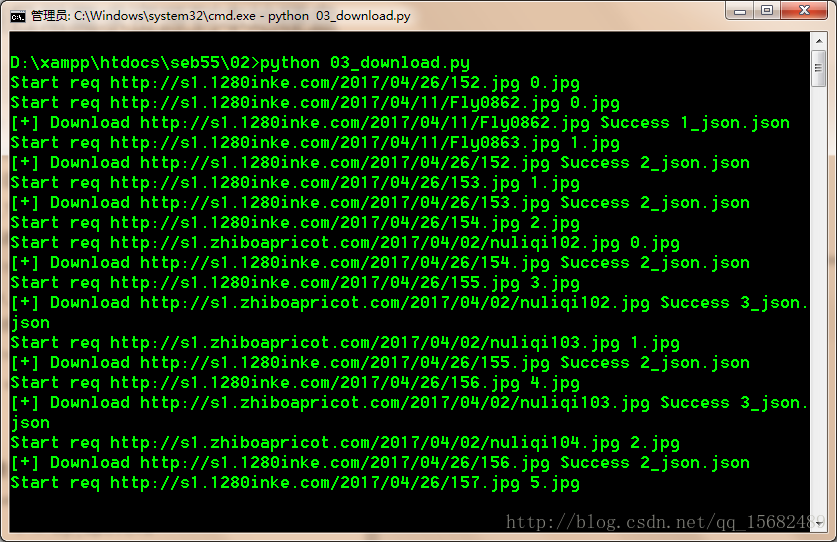
然来后简单的等待下载完成就可以了
直接看文件夹的图片呢 肯定是没有网页可以下拉看,还能集体放大缩小体验好的,所以我们还要做个简单的html遍历本地的这些文件,每个文件夹id对应他的标题,点击进去显示图片,这里呢我就不写了,有兴趣的朋友可以自己试试
最后呢提醒各位绅士们 抓图有风险 身体要谨慎
健康生活,从我做起














 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









