










呐,今天我们来开发一款SublimeText的插件 主要用来平时用来代码规范的
1.先分析一下需求
如果要做代码规范 那么肯定要一行行检查过去啦
对于那些指望用正则表达式检查内容是否按照正确格式找到的基本可以毙掉了
我举个简单的例子 比如lua的
--[[
]]
]]如果你用正则表达式认为第一个--[[遇到]]就会任务这中间部分的内容就是一段长注释 殊不知因为代码的不规范导致你用正则往往没有办法发现问题 匹配出来的结果也往往有较大的问题
列出规范
既然要做代码规范检查,那我们先列出一些规范然后再分析一下怎么解决这些需求
2017/6/5 changwei
lua代码规范规则:
1.单行长度不得超过150个字符 选择换行或者修改写法
2.长注释--[[应该顶格处理
3.单行注释请避开长注释 --[[]]
4.逗号, 只要不是在行末尾后面就应该要加空格
5.左括号"(" 右边不要加空格 右括号左边不要加空格
6.函数名要及时分词
7.函数名不为空的,在前五行内要及时注释
8.头文件声明检查是否有 Permission is hereby granted
9.bool变量名赋值过程名称应该出现 is has can
10.单个函数不得超过25行 统计不包括注释和空格
11.同一行变量赋值不能超过5个
### 考虑加入或单还未处理部分
12.代码对齐 tab算四个,计算每行前面是否为倍数
变量声明避免用”_”或”__”开头,因为以它们开头的变量是被系统保留的
若变量的赋值来自于函数的返回值,则同一行不允许有除了函数返回值的其它变量赋值
使用二目运算符时,运算符左右两边要有一个空格。
建议不用分号(;) 要么就每行都用分号
for循环内的字符拼接推荐使用 .. string.format 不要用.. 占内存
出现多个elif 提示用表寻找写法 这样更快速 用多个elif让费不必要的计算和循环1.单行长度不得超过150个字符 选择换行或者修改写法
解决方案:那我们就检查单行的内容,超过150字符的就提示
2.长注释--[[应该顶格处理
解决方案:如果出现--[[那就检查这个是不是在该行前四个字符
3.单行注释请避开长注释 --[[]]
解决方案:这里我还是推荐大家单行注释使用--
4.逗号, 只要不是在行末尾后面就应该要加空格
解决方案:统一检查如果逗号不是在末尾的 后面都应该跟一个空格
5.左括号”(” 右边不要加空格 右括号左边不要加空格
解决方案:有人喜欢写个函数,比如function( param ) 参数两边带个空格,觉得这样好看,但是这样写比较麻烦 不利于大众跟随 所以我们统一一下两边就是不要带空格
6.函数名要及时分词
解决方案:分词嘛 意思就是要么用下划线_ 要么不同单词首字母大写的方式,总之不能一连串的小写字母写了一大坨
7.函数名不为空的,在前五行内要及时注释
解决方案:我们做代码规范检查的,有的人一下子代码就是几万行,十几万行,所以检查代码要迅速,时间复杂度要为n。那么怎么做到检查别人写的代码有没有写注释呢?那就是遇到函数,拆开函数名不为空的时候倒推之前记录的五行的状态,看看有没有注释
8.头文件声明检查是否有指定声明
解决方案:如果是公司开发的文件一般头文件还会声明一些东西 那就是检查第一个长注释有没有遇到指定的头文件声明词嘛 比如 Permission is hereby granted
9.bool变量名赋值过程名称应该出现 is has can
解决方案:如果出现赋值的情况,也就是有xxx=true或false的,检查这个变量名称有没有指定出现指定词汇中至少其中一个
10.单个函数不得超过25行 统计不包括注释和空格
解决方案:遇到函数结尾的时候统计一下 上个函数开头到这里 内容行的标记有多少
11.同一行变量赋值不能超过5个
解决方案:这里的意思就是说,虽然lua可以在一行内给多个字段赋值,但是还是不要超过五个的好
12…..做到这里后觉得对于大部分人的规范基础就这么定了 如果要更多的读者可以自己定自己加
那么我们开始写代码吧
代码的解决方案
1.代码的每一行 要么是大型注释 要么是普通注释 要么是空行 要么是内容行,所以我们给每一行标记一个状态,用一个字典记录下来。
接下来ShowCode时间 CodeStand.py
# -*- coding:utf-8 -*-
import re
import os
import traceback
"""
2017/6/5 changwei
lua代码规范规则:
1.单行长度不得超过150个字符 选择换行或者修改写法
2.长注释--[[应该顶格处理
3.单行注释请避开长注释 --[[]]
4.逗号, 只要不是在行末尾后面就应该要加空格
5.左括号"(" 右边不要加空格 右括号左边不要加空格
6.函数名要及时分词
7.函数名不为空的,在前五行内要及时注释
8.头文件声明检查是否有 Permission is hereby granted
9.bool变量名赋值过程名称应该出现 is has can
10.单个函数不得超过25行 统计不包括注释和空格
11.同一行变量赋值不能超过5个
### 考虑加入或单还未处理部分
12.代码对齐 tab算四个,计算每行前面是否为倍数
变量声明避免用”_”或”__”开头,因为以它们开头的变量是被系统保留的
若变量的赋值来自于函数的返回值,则同一行不允许有除了函数返回值的其它变量赋值
使用二目运算符时,运算符左右两边要有一个空格。
建议不用分号(;) 要么就每行都用分号
for循环内的字符拼接推荐使用 .. string.format 不要用.. 占内存
出现多个elif 提示用表寻找写法 这样更快速 用多个elif让费不必要的计算和循环
"""
# 寻找出内容行
def Find_Content(mdic):
length = 0
for x in mdic:
if x['state'] == 4:
length += 1
return length
class myCodeStand(object):
def __init__(self, code_content, cur_path, Sublime_Version):
# 传入代码
self.code_content = code_content
# 每一行的不规范点存入结果
self.Results = []
# 这个脚本所在文件夹
self.cur_path = cur_path
# 2用的2.6 3用的3.3 python 版本
self.Sublime_Version = Sublime_Version
# 执行代码规范检查
def DoJudge(self):
try:
self.Specification()
except Exception as e:
self.Results.append(u'评分代码出现错误,请联系代码开发者:429304451 '+str(e))
where = os.path.join(self.cur_path,'codeerr.txt')
traceback.print_exc(file=open(where,'w'))
finally:
return self.Results
def Show_Warn(self,i,err,warn,line):
if err != '' or warn != '':
self.Results.append(str(i)+'------------------')
self.Results.append(line)
if err != '':
self.Results.append(err)
if warn != '':
self.Results.append(warn)
# 代码规范标准
def Specification(self):
line_tab = self.code_content.split('\n')
# 是否处在长注释之中
Annotation_Big = False
if 'Permission is hereby granted' not in self.code_content:
self.Results.append(u'err:头文件未找到声明:Permission is hereby granted 请检查全部声明是否完整')
# 这个代码规范的算法复杂度 n 就是靠这个表的查询 用内存换时间
Line_State_Tab = []
# 没有给函数注释出现的次数 超过一次就在尾行提示推荐注释法
Do_Not_Annotate = 0
# 最近一次函数出现在什么地方
Function_Last = {'name':'', 'where':0}
# bool变量名应该使用 is can has
boolHeader = ['is', 'can', 'has', 'enable']
### 开始代码规范判断
for i,line in enumerate(line_tab):
# i 哪一行 state 状态 1.大型注释 2.普通注释 3.空行 4.内容
Line_Dic = {'i':i,'state':0,'err':'','warn':''}
Strip_Line = line.strip()
err = ''
warn = ''
# 空行 不管
if Strip_Line == '':
Line_Dic['state'] = 3
Line_State_Tab.append(Line_Dic)
self.Show_Warn(i, err, warn, line)
continue
if len(line) > 150:
warn += u'warn:单行长度超过150,请修改一下写法或换行\n'
# 身处长注释之中 不管你写什么都没用了 我也不去管你的长注释内容
if Annotation_Big == True:
Line_Dic['state'] = 1
if '--[[' in line:
err += u'err:身处长注释之中还重复出现长注释头--[[\n'
if ']]' in line:
# 遇到这个,长注释结束的意思
Annotation_Big = False
Line_Dic['err'] = err
Line_Dic['warn'] = warn
Line_State_Tab.append(Line_Dic)
self.Show_Warn(i, err, warn,line)
continue
else:
if '--[[' in line:
Line_Dic['state'] = 1
if Strip_Line[0:4] != '--[[':
err += u'err:长注释的--[[应该置于顶格\n'
if ']]' in line:
warn += u'warn:单行注释请避开长注释使用法--[[]]\n'
else:
Annotation_Big = True
Line_Dic['warn'] = warn
Line_Dic['err'] = err
Line_State_Tab.append(Line_Dic)
self.Show_Warn(i, err, warn,line)
continue
if ']]' in line:
err += u'err:未处于大型注释之中请勿随意使用 ]]\n'
if '--' in line:
# 说明至少包含有短注释 是不是整行全是有待考证
if '--' == Strip_Line[0:2]:
# 说明这一整行都是短注释 那么后面什么都不用管了
Line_Dic['state'] = 2
Line_Dic['warn'] = warn
Line_Dic['err'] = err
Line_State_Tab.append(Line_Dic)
self.Show_Warn(i,err,warn,line)
continue
else:
# 说明是前面写一部分逻辑 后面带短注释的,认定是内容行
line = line.split('--')[0]
### 以下就是内容行的处理了
Line_Dic['state'] = 4
# 逗号只要不是在末尾 就应该跟空格
if ',' in line:
Comma_Error = False
tmp_tab = line.split(',')
for c, x in enumerate(tmp_tab):
if c > 1 and len(x) != 0:
if x[0] != ' ':
Comma_Error = True
if Comma_Error == True:
warn += u'warn:逗号, 只要不是在行末尾后面就应该要加空格\n'
# 判断是否是函数 前面是否有注释 倒推五行看是否有注释长短注释状态
if 'function' in line:
if '(' in line:
function_line = line[line.index('function')+8:line.index('(')].strip()
if ':' in function_line:
function_line = function_line.split(':')[-1]
elif '.' in function_line:
function_line = function_line.split('.')[-1]
if len(function_line) > 10 and ('_' not in function_line) and (re.match('^[a-z]+$',function_line) or re.match('^[A-Z]+$',function_line)):
err += u'err:%s函数名长度超过10个字母未分词,可能存在错误\n'%function_line
if len(line) > line.index('(') + 1:
if line[line.index('(') + 1] == ' ':
err += u'左括号"(" 右边不要加空格\n'
# 函数名不为空 就近前五行内就应该有注释
if function_line != '':
if line[line.index(function_line)+len(function_line)] != '(':
err += u'err:函数名之后不要留空格,紧跟左括号"(" \n'
# 说明是这个函数的起始位置 倒推5位数如果还没找到注释却找到内容就提示这个函数需要注释了
back_num = 5
if i < 5:
back_num = i
# 判断是否有注释
has_annotation = False
# 如果遇到内容还没有注释 那就是这个函数没有注释了
meet_content = False
for x in range(0,back_num):
if meet_content == False:
Find_State = Line_State_Tab[i-x-1]['state']
if Find_State < 3:
has_annotation = True
elif Find_State == 4:
# 没有遇到注释就遇到内容了 接下来不用倒推了 这个函数就是没注释
meet_content = True
if has_annotation == False:
warn += u'warn:请给函数%s添加下注释吧!\n'%function_line
Do_Not_Annotate += 1
if 'function' == line[0:8]:
Function_Last = {'where':i,'name':function_line}
else:
err += u'err:function行未找到('
if ')' in line:
if line[line.index(')') - 1] == ' ':
err += u'右括号")" 左边不要加空格\n'
if ('true' in line or 'false' in line) and '=' in line:
tmptab = line.split('=')
name = tmptab[0].lower()
name_suit = False
for x in boolHeader:
if x in name:
name_suit = True
if name_suit == False:
err += u'warn:bool变量名赋值名称应该出现 is can has enable'
# 前三个是end的 那基本就是函数结束没得跑了 也有更复杂的判断 统计if for的 先用这简单的
if 'end' == line[0:3]:
# 那就当一个函数结束了 计算一下content 也就是函数起始到这里的有多少行
if Function_Last['name'] != '':
# function_length = len( filter(Find_Content, Line_State_Tab[Function_Last['where']:i]) ) - 1
function_length = Find_Content(Line_State_Tab[Function_Last['where']:i])
if function_length > 25:
warn += u'warn:函数%s超过25行,达到%d'%(Function_Last['name'],function_length)
Function_Last = {'where':0,'name':''}
if 'local' in line:
if ('=' not in line) and ('function' not in line):
err += u'err:变量在赋值的时候应该给予值,没有的话也应该写 = nil'
else:
tmpline = line.split('=')[0]
if tmpline.count(',') >= 4:
err += u'err:同一行变量赋值过多'
Line_Dic['err'] = err
Line_Dic['warn'] = warn
Line_State_Tab.append(Line_Dic)
self.Show_Warn(i, err, warn,line)
# if err != '' or warn != '':
# self.Results.append(str(i)+'------------------')
# self.Results.append(line)
# # print i,'-------------'
# # print line
# if err != '':
# self.Results.append(err)
# if warn != '':
# self.Results.append(warn)
# if __name__ == '__main__':
# import codecs
# mPath = r'E:\django\quick\mysublime\coderating-master\4.lua'
# f = codecs.open(mPath,"r","utf-8")
# code_content = f.read()
# f.close()
# cur_dir = os.getcwd()
# Results = myCodeStand(code_content,cur_dir).DoJudge()
# for x in Results:
# print x
# self.Results = myCodeStand(code,cur_dir).DoJudge()
# main()
这里我把单个文件调用的也有所保留,有用过python的恢复这部分注释就能直接用来给自己代码检查规范了
不过我说了 我们是要给sublimeText当插件用的
我要做到的是一个快捷键 使用快捷键后直接告诉我 代码哪里不规范 或者给我个宝宝的代码就是一百分的心情
继续ShowCode defineReplace.py
# -*- coding:utf-8 -*-
import sublime_plugin
import sublime
import traceback
import os
# 引入代码评分规则 myCodeStand
try:
import CodeStand
except ImportError:
from . import CodeStand
__file__ = os.path.normpath(os.path.abspath(__file__))
__path__ = os.path.dirname(__file__)
# 获取Sublime Text 版本 2用的py2.6版本 3基本用的py3.3 写法有所不同
Sublime_Version = sublime.version()[0]
"""
1.获取sublime 版本 毕竟2和3有所区别 而我要做的是两个都能跑的
2.获取当前打开文件是否后缀为.lua 获取面板内容
3.评估lua的代码规范 有错误则指出 8888
"""
class definereplaceCommand(sublime_plugin.TextCommand):
def run(self, edit):
# self.Is_Update = False
# 调试模式 代码输出就靠这个文本了
f = open(os.path.join(__path__,'out.txt'),'w')
try:
# 获取当前面板打开文件的全路径
file_name = self.view.file_name()
# 获取后缀名
suffix = ''
if file_name:
if '.' in file_name:
suffix = file_name.split('.')[-1]
# 正式环境才开启来 后缀不是lua的不管
if suffix != 'lua':
return
# 获取当前面板的全部内容
region = sublime.Region(0,self.view.size())
code = self.view.substr(region)
# f.write(code)
# f.write(file_name)
# 代码规范检查
self.Results = CodeStand.myCodeStand(code, __path__, Sublime_Version).DoJudge()
if len(self.Results) == 0:
self.Results.append(u'100分 恭喜您的代码完全符合宝宝目前的lua代码规范')
# self.update()
# # 调试输出
# f.write(str(len(self.Results)))
# f.write('\n')
# f.write(str(self.Results))
# f.write('\n')
f.write(Sublime_Version)
f.write('\n')
if Sublime_Version == '2':
self.show_tests_panel2()
elif Sublime_Version == '3':
self.show_tests_panel3()
except Exception as e:
# 调试模式 如果脚本出现错误 则在这里输出
where = os.path.join(__path__,'err.txt')
traceback.print_exc(file=open(where,'w'))
finally:
f.close()
# sublime text3 面板显示的写法
def show_tests_panel3(self):
self.output_view = self.view.window().get_output_panel('tests')
self.output_view.set_read_only(False)
for x in self.Results:
self.output_view.run_command('append',{'characters':x})
self.output_view.run_command('append',{'characters':'\n'})
self.output_view.set_read_only(True)
self.view.window().run_command("show_panel", {"panel": "output.tests"})
# sublime text2 面板显示的写法
def show_tests_panel2(self):
if not hasattr(self, 'output_view'):
self.output_view = self.view.window().get_output_panel("tests")
self.output_view.set_read_only(False)
edit = self.output_view.begin_edit()
self.output_view.erase(edit, sublime.Region(0, self.output_view.size()))
for x in self.Results:
self.output_view.insert(edit, self.output_view.size(), x)
self.output_view.insert(edit, self.output_view.size(), '\n')
self.output_view.end_edit(edit)
self.output_view.set_read_only(True)
self.view.window().run_command("show_panel", {"panel": "output.tests"})
# 代码评分规则 动态更新
def update(self):
# 当前版本
Cur_Version = '2'
# 去请求我的网站 比对版本 如果有高版本就说明我最近有新的规则更新了 下载下来替换己身
if Sublime_Version == '2':
import urllib2
try:
response = urllib2.urlopen('http://audio.babybus.co/sub_version', timeout = 1)
inter_version = int(response.read().strip())
if inter_version > int(Cur_Version):
self.Results.append(u'2网络版本比对有差异 开始更新\n')
# pass
response = urllib2.urlopen('http://audio.babybus.co/sub_content', timeout = 1)
content = response.read()
f = open(os.path.join(__path__,'CodeStand.py'),'wb')
f.write(content)
f.close()
response = urllib2.urlopen('http://audio.babybus.co/sub_content?which=1', timeout = 1)
content = response.read()
f = open(os.path.join(__path__,'defineReplace.py'),'wb')
f.write(content)
f.close()
else:
# self.Results.append(u'2网络版本比对一致\n')
pass
except Exception as e:
# self.Results.append(u'2版本更新出错了'+str(e))
pass
else:
from urllib import request
try:
response = request.urlopen('http://audio.babybus.co/sub_version', timeout = 1)
inter_version = int(response.read().strip())
if inter_version > int(Cur_Version):
# 如果对比不一致就从网上下载新的代码来替换 CodeStand 1 defineReplace
self.Results.append(u'3网络版本比对有差异 开始更新\n')
# pass
response = request.urlopen('http://audio.babybus.co/sub_content', timeout = 1)
content = response.read()
f = open(os.path.join(__path__,'CodeStand.py'),'wb')
f.write(content)
f.close()
response = request.urlopen('http://audio.babybus.co/sub_content?which=1', timeout = 1)
content = response.read()
f = open(os.path.join(__path__,'defineReplace.py'),'wb')
f.write(content)
f.close()
else:
# self.Results.append(u'3网络版本比对一致\n')
pass
except Exception as e:
pass
这里有一个update函数 是我构建第一版,也就是现在展示的这个版本
觉得后面如果有人用起来提更多的规范需求的话,我改一个要发给使用者一次插件 然后替换到指定位置
所以干脆用网络请求版本比对的方式 如果本地版本比网络上的版本低的话就会去下载新的代码替换己身
SublimeText2是用python2.6写的 SublimeText3插件是用Python3.3写的,语法和调用Sublime的命令毕竟有所不同 所以我这里做了版本判断和特殊处理,所以以上的代码是同时兼容2和3的
最后我们定义一下快捷键
Default (Windows).sublime-keymap
[
{ "keys": ["ctrl+alt+q"], "command": "definereplace" }
]
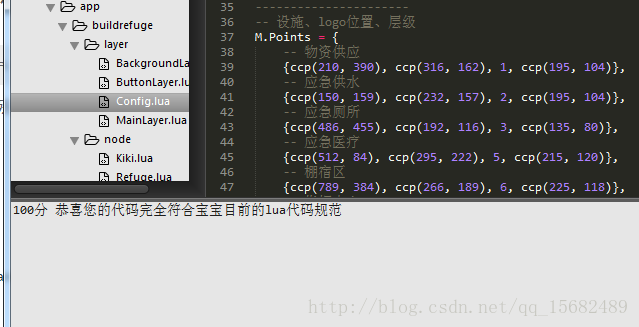
这样我们打开一个lua文件 然后用快捷键ctrl+alt+q就可以看到评判规范如何了
举个栗子
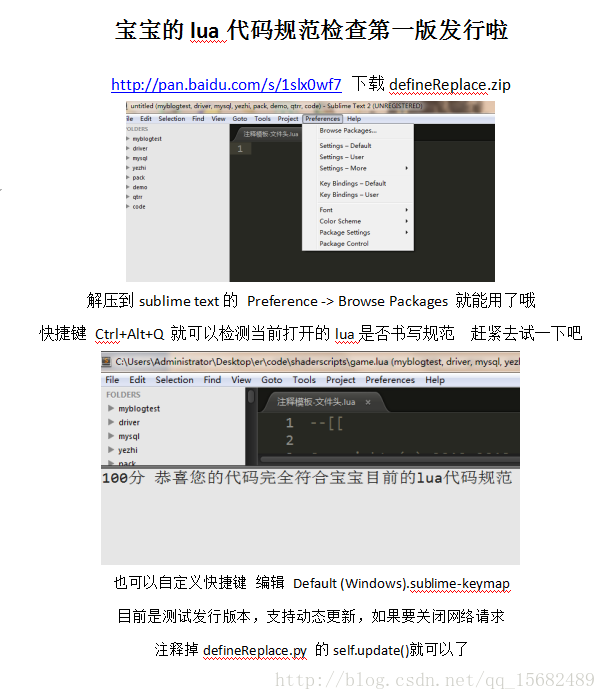
最后呢我们给读者一个快速教使用者安装插件的方法
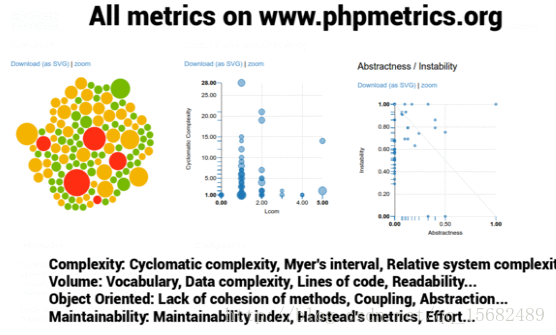
不久前我看到一款软件叫做 PhpMetrics 主要就是用来统计函数之间的关联性和出现的频次
这里我们也可以把字典里面的函数名调用互相关联起来 有兴趣的人可以顺着这个基础模板继续改造下去
这里借花献佛展示几张代码规范或者说函数相关性评定的图,有兴趣看更具体的可以去看看PhpMetrics
















 3737
3737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









