








1.概述
1。先看一下从源码层面梳理Spark在任务调度与资源分配上的做法。
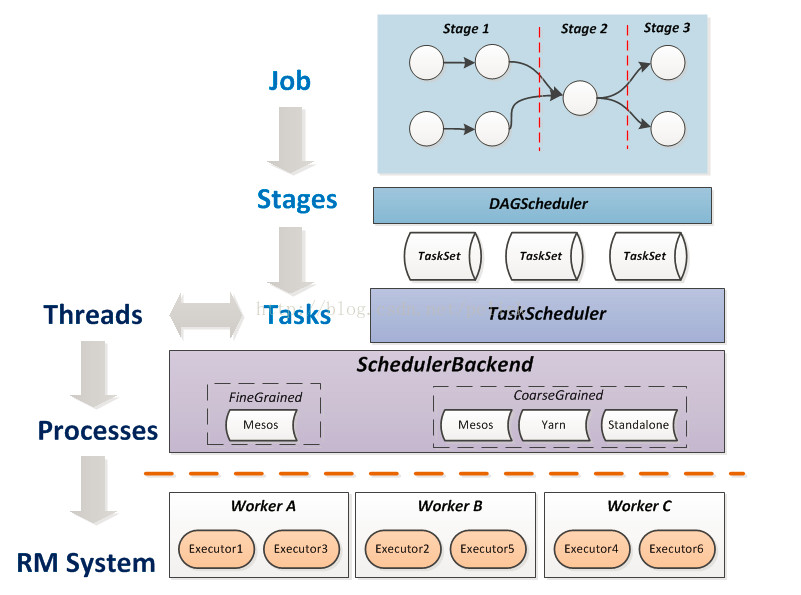
这里涉及几个小知识点:
1.1。最上面的7个圆圈是如何划分stage的?
原则:凡是RDD之间是窄依赖的,都归到一个stage里,这里面的每个操作都对应成MapTask,并行度就是各自RDD的partition数目。凡是遇到宽依赖的操作,那么就把这一次操作切为一个stage,这里面的操作对应成ResultTask。
Spark的stage的划分:http://blog.csdn.net/qq_21383435/article/details/78700524
1.2。为什么会有3个TaskSet?
一个stage内的task集合成一个TaskSet类。 上面一共有3个stage.
1.3 在TaskScheduler和SchedulerBackend之间还有相应的实现类TaskSchedulerImpl以及TaskSetManager
1.4 Executor是真正执行任务的进程,本身拥有若干cpu和内存,可以执行以线程为单位的计算任务

 订阅专栏 解锁全文
订阅专栏 解锁全文















 577
577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











