







机器学习的基本概念
1、什么是人工智能?
- 人工智能,artificial intelligence,简称 AI。
出发点(目标)是希望打造出一种方法让计算机(或机器)像人类一样可以思考,推理等行为;让计算机能够做出像人类一样智能化的行为。
- 人工智能常用的领域:(核心是机器学习)
推理(reasoning);
机器人(robotics);
学习(learning);
知识(knowledge);
数据挖掘(DM);
自然语言处理(NLP);
视觉(vision)。
2、什么是机器学习?
- 机器学习,machine learning,简称 ML。
定义:使用经验(experience)去改进性能(performance)的一种计算方法。
经验(experience):数据驱动(data-driven task)的经验,即从数据中得到的规律。一般结合统计、概率论、优化理论来让计算机学习数据中的经验。与之相关的计算机科学(computer science,CS)领域:学习算法(learning algorithm);复杂度分析(analysis of complexity);收敛理论保证(theoretical guarantees)。
- 机器学习的例子:
task:让计算机去认识什么是三角形。
data:提供大量的三角形实例。
feature:三角形的边,角等数据。
特征工程(feature engineering and selection,FE):从数据的一系列属性中进行,特征提取(feature extraction);选取与目标相关的特征进行一系列处理。
- 机器学习常用的领域:
分类(classification):给定一个事物判定分到某个目录类别,结果必定是离散的。(比如是狗还是猫的分类任务、推送的内容是属于娱乐还是科技还是体育的分类任务);
回归(regression):输入一个数据,预测事情的变化结果。结果是连续的,往往得到一条回归曲线。(如预测一天的气温、股价、经济增长);
排序(ranking):根据某种标准将给定的条目集合排序。(如搜索引擎百度,输入关键词,得到排好序的网页结果);
聚类(clustering):物以类聚。对一堆数据进行分析,按照相似类别分成几个组区域(如图像分割就是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术和过程;Google新闻按照内容结构的不同分成财经,娱乐,体育等不同的标签,这就是一种聚类。);
降维(dimensionality reduction):采用某种映射方法,寻找低维的数据去代表高维,保留最主要的有用信息。(如图像的像素点怎么让学习器利用);
…
参考网址:http://www.cnblogs.com/cs-lcy/p/6900918.html
3、机器学习的定义术语
- 参考网址:https://zhuanlan.zhihu.com/p/27078055?refer=dreawer
- 参考网址:http://blog.csdn.net/bahuia/article/details/68926915
- 术语:
example:样本,例子。
features:特征,关联属性,常表示为向量 vector。
label:标签,分类中标签为离散值;回归中标签的取值连续。
data:数据;划分为训练数据、测试数据等。
- 机器学习的数据种类:
有监督学习:计算机在有标签的数据学习后,能预测数据结果的学习过程。
无监督学习:计算机在没有标签的数据学习后,能获取有用数据的学习过程。
半监督学习:有两个样本集,一个有标签,一个没有标签。综合利用有类标的样本和没有类标的样本来生成合适的分类函数。
强化学习:数据没有标签,但可以通过某种方法知道是离正确答案越近还是越远(即奖惩函数)。
4、什么是学习问题?
- formalize the learning problems:

- 最终学到: g ≈ f g≈f g≈f:

- 在这篇博客之前我写过一篇关于 NLP 的博客笔记,很形象的说明了机器学习的套路,博客地址点 这里。
5、为什么机器可以学习?
- ML的可行性:霍夫丁不等式
- 机器学习最基本的理论保障,相当重要的不等式!
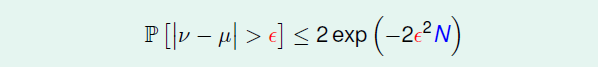
- 机器学习的算法:
经验风险最小化:(empirical risk minimization,ERM);样本上求解。
结构风险最小化:(structural risk minimization,SRM);加正则项防止过拟合。
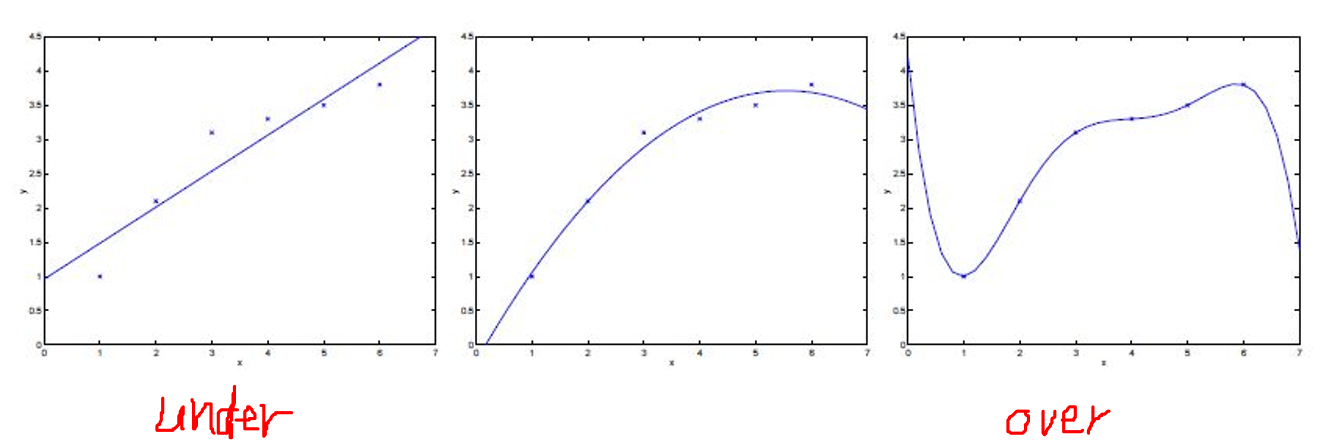
欠拟合:(under-fitting);模型不能拟合样本。
过拟合:(over-fitting);模型拟合样本很好,但是推广能力差。
- 机器学习 vs 数据挖掘:
ML:从经验数据中找一个函数。
DM:从大数据中找到有用的数据属性。















 9540
9540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









