







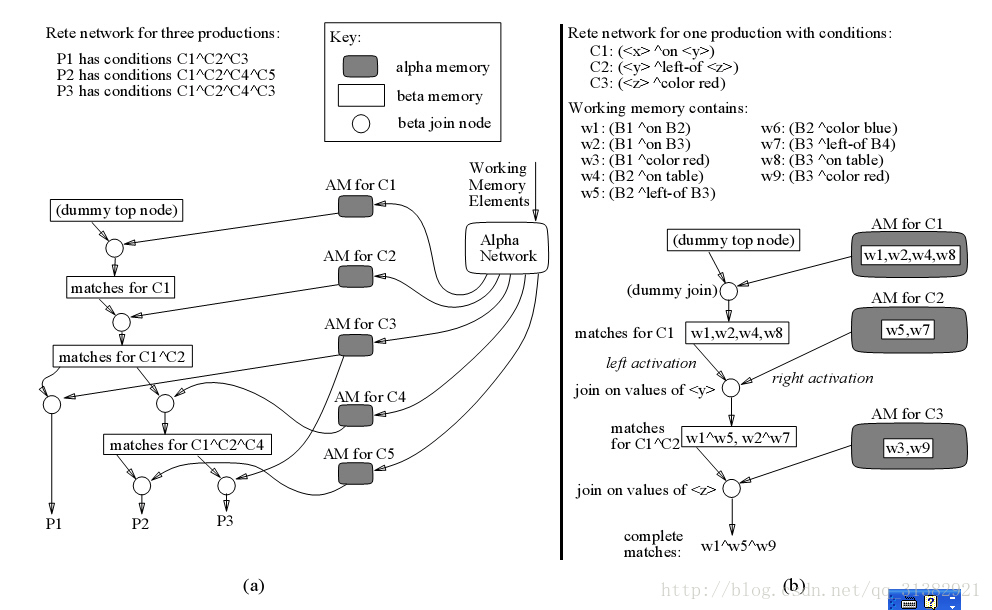
RETE算法介绍
一、 rete概述
Rete算法是一种前向规则快速匹配算法,其匹配速度与规则数目无关。Rete是拉丁文,对应英文是net,也就是网络。Rete算法通过形成一个rete网络进行模式匹配,利用基于规则的系统的两个特征,即时间冗余性(Temporal redundancy)和结构相似性(structural similarity),提高系统模式匹配效率。
二、 相关概念
2.1 事实(fact):
事实:对象之间及对象属性之间的多元关系。为简单起见,事实用一个三元组来表示:(identifier ^attribute value),例如如下事实:
w1:(B1 ^ on B2) w6:(B2 ^color blue)
w2:(B1 ^ on B3) w7:(B3 ^left-of B4)
w3:(B1 ^ color red) w8:(B3 ^on table)
w4:(B2 ^on table) w9:(B3 ^color red)
w5:(B2 ^left-of B3)
2.2 规则(rule):
由条件和结论构成的推理语句,当存在事实满足条件时,相应结论被激活。一条规则的一般形式如下:
(name-of-this-production
LHS /one or more conditions/
–>
RHS /one or more actions/
)
其中LHS为条件部分,RHS为结论部分。
下面为一条规则的例子:
(find-stack-of-two-blocks-to-the-left-of-a-red-block
(^on)
(^left-of)
(^color red)
–>
…RHS…
)
2.3 模式(patten):
模式:规则的IF部分,已知事实的泛化形式,未实例化的多元关系。
(^on)
(^left-of)
(^color red)
三、 模式匹配的一般算法
规则主要由两部分组成:条件和结论,条件部分也称为左端(记为LHS, left-hand side),结论部分也称为右端(记为RHS, right-hand side)。为分析方便,假设系统中有N条规则,每个规则的条件部分平均有P个模式,工作内存中有M个事实,事实可以理解为需要处理的数据对象。
规则匹配,就是对每一个规则r, 判断当前的事实o是否使LHS(r)=True,如果是,就把规则r的实例r(o)加到冲突集当中。所谓规则r的实例就是用数据对象o的值代替规则r的相应参数,即绑定了数据对象o的规则r。
规则匹配的一般算法:
1) 从N条规则中取出一条r;
2) 从M个事实中取出P个事实的一个组合c;
3) 用c测试LHS(r),如果LHS(r(c))=True,将RHS(r(c))加入冲突集中;
4) 取出下一个组合c,goto 3;
5) 取出下一条规则r,goto 2;
四、 RETE算法
Rete算法的编译结果是规则集对应的Rete网络,如下图。Rete网络是一个事实可以在其中流动的图。Rete网络的节点可以分为四类:根节点(root)、类型节点(typenode)、alpha节点、beta节点。其中,根结点是一个虚拟节点,是构建rete网络的入口。类型节点中存储事实的各种类型,各个事实从对应的类型节点进入rete网络。
4.1 建立rete网络
Rete网络的编译算法如下:
1) 创建根;
2) 加入规则1(Alpha节点从1开始,Beta节点从2开始);
a. 取出模式1,检查模式中的参数类型,如果是新类型,则加入一个类型节点;
b. 检查模式1对应的Alpha节点是否已存在,如果存在则记录下节点位置,如果没有则将模式1作为一个Alpha节点加入到网络中,同时根据Alpha节点的模式建立Alpha内存表;
c. 重复b直到所有的模式处理完毕;
d. 组合Beta节点,按照如下方式:
Beta(2)左输入节点为Alpha(1),右输入节点为Alpha(2)
Beta(i)左输入节点为Beta(i-1),右输入节点为Alpha(i) i>2
并将两个父节点的内存表内联成为自己的内存表;
e. 重复d直到所有的Beta节点处理完毕;
f. 将动作(Then部分)封装成叶节点(Action节点)作为Beta(n)的输出节点;
3) 重复2)直到所有规则处理完毕;
可以把rete算法类比到关系型数据库操作。
把事实集合看作一个关系,每条规则看作一个查询,将每个事实绑定到每个模式上的操作看作一个Select操作,记一条规则为P,规则中的模式为c1,c2,…,ci, Select操作的结果记为r(ci),则规则P的匹配即为r(c1)◇r(c2)◇…◇(rci)。其中◇表示关系的连接(Join)操作。
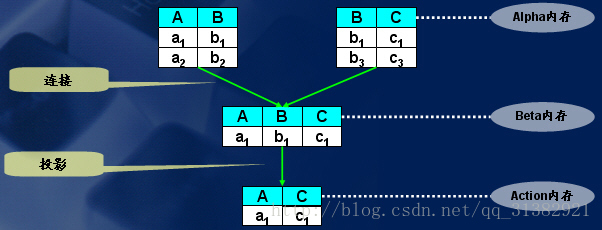
4.2 使用rete网络进行匹配
使用一个rete的过程:
1) 对于每个事实,通过select 操作进行过滤,使事实沿着rete网达到合适的alpha节点。
2) 对于收到的每一个事实的alpha节点,用Project(投影操作)将那些适当的变量绑定分离出来。使各个新的变量绑定集沿rete网到达适当的bete节点。
3) 对于收到新的变量绑定的beta节点,使用Project操作产生新的绑定集,使这些新的变量绑定沿rete网络至下一个beta节点以至最后的Project。
4) 对于每条规则,用project操作将结论实例化所需的绑定分离出来。
下面为的图示显示了连接(Join)操作和投影(Project)的执行过程。
4.3 Rete算法的特点
Rete算法有两个特点使其优于传统的模式匹配算法。
1、状态保存
事实集合中的每次变化,其匹配后的状态都被保存再alpha和beta节点中。在下一次事实集合发生变化时,绝大多数的结果都不需要变化,rete算法通过保存操作过程中的状态,避免了大量的重复计算。Rete算法主要是为那些事实集合变化不大的系统设计的,当每次事实集合的变化非常剧烈时,rete的状态保存算法效果并不理想。
2、节点共享
另一个特点就是不同规则之间含有相同的模式,从而可以共享同一个节点。Rete网络的各个部分包含各种不同的节点共享。
使用RETE算法的模块系统,有四个入口,分别是添加事实(add-wme)、去除事实(remove-wme)、添加规则(add-production)、去除规则(remove-production)。
上面的主要介绍了建立rete网络后添加事实的过程。下面先具体介绍alpha网络的建立和添加事实的过程,然后再介绍另外三个过程。
4.4 Alpha网络
当事实添加到工作内存后,alpha网络对事实进行必要的类型检测并把事实存放到相应的alpha内存里。有几种方法来寻找合适的alpha内存节点。
4.4.1 数据流网络
最直接的方式就是使用一个简单的数据流网络。
下图就是一个采用数据流网络建立的alpha网络。
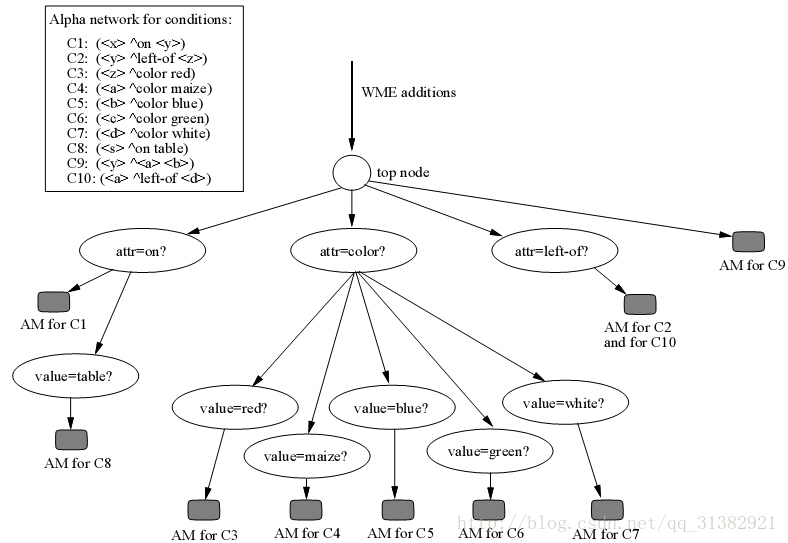
上面的alpha网络仅仅检测条件中的常量,如attribute项上的常量有on,color,left-of;value项上的常量red maize blue green white。
4.4.2 带Hashing的数据流网络
上面的数据流网络的一个最大的缺点就是,当某个节点的扇出(fan-out)很大时,将会做大量的无用功(wasted work)。比如上图中对颜色的测试,某些专家系统可能含有大量的颜色,那么将会有大量的比较操作,从而造成匹配操作变慢。
一个解决这个问题的方法就是对于那些带有很大扇出的节点,采用hash表(或者平衡二叉树)来判断。
从上面的讨论可知,alpha网络非常有效,随着事实集合的变化,alpha网络可以几乎可以马上作出相应处理。Beta节点的处理占到了整个系统匹配的绝大部分时间。所以一般研究的都针对网络中的beta节点进行。
4.5 内存节点
Alpha内存存储事实集合,beta内存存储tokens(tokens指规则中已经匹配好的事实绑定)。
4.5.1 事实集合的结构
事实集合最简单的结构是采用链表结构。但是为了获得更高的效率,一般也给每个事实内存加上索引(indexing)。最常用的索引方法是采用Hash表。也可以采用树,但在多数rete算法实现上并不常用,(Barachini,1991)发现Hash表一般比非平衡二叉树的性能好。索引方法的缺点有两个:添加删除元素费时,降低了节点的复用度。所以索引方法在那些节点内存中并不包含很多元素的系统中不适用。
4.5.2 Token的结构
可以使用数组或链表来存储token。使用数组需要更多的空间,同时需要更多的时间来创建token。但是,拥有更快的访问速度。通常,选择的标准在于使用链表时访问某个元素的用的时间是否可以承受。
4.6 连接节点(Join node)
当一个连接节点的alpha内存中加入一个事实时,将引发此连接节点的right activation,当一个连接结点的beta内存中加入一个token时,将引发此连接节点的left activation。
连接节点的数据结构包括:指向其alpha内存和beta内存的指针,变量连接检测的说明,指向子节点的指针。
当一个连接节点的alpha内存中加入某个事实时,引发right activation。此处,因为right activation 的顺序不同,有可能产生冗余tokens(即在同一个beta内存里存储有两个或以上的相同的token)。结果这个问题的方法有:每次在beta内存中加入一个新的token时,都检测是否已存在相同的token。这个方法的缺点就是使系统的处理速度变慢。另外一个较好的方法是把right activation的顺序确定下来。
4.7 去除事实(Removals of facts)
当某个事实从工作内存总删除时,需要更新含有此事实的alpha内存和beta内存,有以下几种方法。
在原始的rete算法中,删除操作和添加操作采用同一种方式。称此方式为rematch-based removal。主要思想是给每个添加或删除操作一个tag,用来表明此操作是添加事实或删除事实。删除操作的具体执行过程同上面讨论的添加一个事实的过程类似。此方法与其他方法相比,速度较慢。因为删除操作与添加操作的工作量几乎相同。在添加事实过程中所获得的信息并没有在执行删除操作时加以利用。下面有三种改进的算法。
在scan-based removal中,当一个连接节点的alpha内存中的某个事实w被去除时,把w传给此连接节点的输出内存,在此内存中寻找最后一个元素为w的tokens,将这些tokens删除,并且把这些tokens传给此连接节点的子节点。在在子节点中做类似删除操作。(Scales,1986)通过使用此方法代替原有方法,获得28%的加速。(Barachini,1991)获得了10%的加速。
在list-base removal和tree-based removal中使用了这样一个原理,即给事实集合以及tokens的数据结构上增添额外的指针,当某个事实被删除时,可以沿着这些指针删除需要删除的元素。
在list-based removal(Scales ,1986)中,把每个事实w上添加一个包含此事实的tokens的链表。当w被删除时,只要沿着此链表删除这些tokens。缺点就是需要大量的空间来存储链表,同时在创建一个新token时也可能花费大量的额外时间。
在tree-base removal中,在每个事实w上添加一个链表,这些链表指向把w作为最后一个元素的tokens。同时,在每个tokens上,添加一个指向此tokens的子节点的链表。当w被删除时,遍历以tokens为根的子树,删除子树上的所有元素。当然,这些额外指针将占用更多内存,同时,建立这些指针也耗费时间。经验表明,采用此方法比原始方法要节省时间。
(注:本文参考自
Tambe, M., Kalp, D., and Rosenbloom,P. (1991). Uni-Rete: Specializing the Rete match algorithm for the unique-attribute representation. Technical Report CMU-CS-91-180,School of Computer Science, Carnegie Mellon University.
Tambe, M., Kalp, D., and Rosenbloom,P. S. (1992). An effcient algorithm for production systems with linear-time match. In Proceedings of the Fourth IEEE International Conference on Tools with Artiial Intelligence, pages 36-43.)
Uni-Rete:一种特有属性表示法(unique-value)的特殊Rete匹配算法
一、 Uni-Rete简介
产生式系统(基于规则的系统)中的组合匹配(the combinatorial match)在许多应用领域中带来了问题:如在实时系统中,人类认知建模,并行系统等。特有属性表示法(unique-attribute representation)可以有效的解决组合匹配问题。Uni-Rete是对Rete匹配算法进行约束,使用了特有属性表示法,实验结果显示其匹配过程的速度比Rete算法快10倍。
[Tambe and Rosenbloom 1989]通过引入特有属性表示法(unique-attribute representation)消除了产生式匹配中的组合问题。使用特有属性,匹配的时间与规则数目成线性关系。Uni-Rete是Rete算法的特例化,在Soar系统中,Uni-Rete比Rete快10倍。
二、 Rete算法
上图是一个通过使用Rete算法进行匹配的例子。
但是,在一个实际的产生式系统中,规则的数目非常多,从而整Rete网络很复杂,如下图所示。从图中可见,网络中的beta内存中可能存在大量的tokens。产生式匹配中的组合问题指beta内存中tokens的组合个数。在最糟糕的情况下,一条产生式可能产生O(WC)个tokens,其中W是事实个数,C是条件个数。Beta内存中有可能存放如此多的tokens,而tokens的数目在编译时无法确定,Rete使用如链表这样的动态结构来存储tokens。通过使用hash表可以对Rete算法进行优化。尽管如此,匹配过程中的主要花费的时间集中在对beta内存的处理中。
三、 特有属性表示法(The Unique-attribute Representation)
产生式匹配过程中的组合问题的是因为不知道到底哪一个事实最终可以匹配某个条件。在一个有很多条件的产生式中,这样的不确定性带来的级联效应(cascading effect)有可能带来与条件个数成指数关系的匹配时间。这种不确定性表现在当对某个条件进行匹配时有可能出现很多对此条件的部分匹配,每个部分匹配都是一个token。采用特有属性表示法可以消除在匹配过程中的不确定性。使用特有属性表示法,每个条件最多只对应着一个token,从而可以消除产生式匹配过程中的组合匹配问题。
这里我们采用(class object attribute value)这样的四元组来表示一个条件,下图所示即为这样的一个产生式。
所谓的特有属性表示法指:给定某个class, object和atrribute,只允许对应某个特定的value。下面a图所示的三个事实不是特有属性表示法,因为三个条件的class,object,attribute均相同,而B1, B2, B3却是三个不同的value。正是因为给定前三个部分相同的字段(field),而却有不同value导致了匹配过程中的不确定性。b图中显示的是特有属性表示法。
另外,特有属性表示法,对产生式中的条件也有约束,即,在object出现的变量必须预先绑定(pre-bound),即,必须在此更前面的条件中出现。
特有属性表示法通过对事实和条件的约束,保证了匹配代价与条件个数成线性关系。即beta内存中最多含有一个token。
特有属性表示法已经成功地运用到Soar中的各种任务中,包括了一些含有500或更多产生式的任务。在这些任务中,特有属性表示法改善了问题解决的性能,去除了代价很高的学习型规则,因此,使研究人员摆脱了产生式系统的效率问题。当然,对Uni-Rete的进一步加速仍然是必要的。
一般来说,特有属性表示法通过牺牲一些表达能力来获得匹配中的效率。这主要表现在两方面,一方面,使用特有属性表示法很难对工作内存中的非结构化数据进行编码,另一方面,特有属性表示法可能削弱学习型产生式(learned production)的归纳能力。
四、 Uni-Rete算法
下面的左图示意了使用Rete算法对使用的特有属性表示法的规则系统处理的过程。图中,每一个beta内存仅包括一个token。尽管如此,Rete算法仍然像以前一样的创建存储tokens,并且同样进行了大量的内存管理。
Uni-Rete充分利用了每一个bete内存中最多有一个token的性质,减少了对token的内存管理。仅有小部分的token存储在给定内存中,大部分的都存储在其前面的beta内存中。如下面的右图所示。左图中存储(w1, w4)的beta内存,在右图中仅仅存储了(w4),因为此beta内存的前面的alpha仅仅包括单独一个事实(w1)。相似的,在左图中存储(w1, w4, w6)的token,在右图中,仅需要存储(w6),剩下的部分隐含在其前面的beta内存之中。因此,通过仅仅存储一个单独的事实,来存储整个token。另外,存储所需的空间可以事先分配好,因为仅含有一个事实,从而可以避免rete算法中的动态内存管理。
Uni-Rete算法仅仅适用于使用特有属性表示法的系统中,因为,如果beta内存中有多个tokens,那么就无法确定哪些事实构成某个token。因此,Uni-Rete的这种隐含存储(implicit storage)不能用在非限制的产生式系统中。
使用上面的右图来说明Uni-Rete的添加和删除某个事实的操作。假设图中的事实w6和w8尚未添加,下面加入事实w6:
第一步,对w6进行常量测试(constant tests),把w6存入右图所示的alpha内存中。
第二步,检查前一个条件的事实指针是否为空。如果是空则添加事实操作结束,不空则进入第三步,如检查w6对应条件的前一个条件的事实指针,此处指向w4,非空,进入第三步。
第三步,与前面的条件对应的事实进行一致性测试。如,检查w4和w6是否含有一致绑定。
第四步,存储指向新事实的指针。如果第三步检测成功,在相应位置存储指向新事实的指针。如,w4, w6是一致绑定,则存储指向w6的指针。如果测试失败,不进行任何下一步操作。
第五步,匹配下一个条件。检查下一个条件对应的alpha内存,是否匹配。若成功,则存储指向那个事实的指针。如,例子中,检查w6和条件4对应的事实是否一致绑定。如果成功,则存储指向条件4对应的那个事实的指针。重复第五步直道下一个条件不匹配。
如果出现指向最后一个条件的指针,则匹配成功。
当删除某个事实时:
第一步,从alpha内存中删除此事实。例如,删除w6时,通过常量检测发现w6,并从alpha内存中删除。
第二步,检测时候有指针指向被删除的事实。如,检测是否有指针指向w6,如果有,进入下一步,没有,则删除操作结束。
第三步,置被删除事实的对应的指针为空。如,置指w6的指针为空指针。
第四步,置所有后继的指针为空。
对token内存的优化,是Uni-Rete算法对Rete算法对主要的优化。通过此优化,有三方面优点,第一,beta内存节点的空间可以事先分配,避免了Rete算法中的内存分配回收操作。第二,beta内存节点仅仅存储指向事实的指针,从而避免了复制大量事实到当前beta内存中。第三,避免了对tokens的hashing操作。
五、 Uni-Rete网络的双线性(bilinear)组织
以上所讨论的Uni-Rete算法都是基于线性的网络。即,每一个条件加入网络时都是加入到一条产生式的所有前面的条件之后。但是,可以把这个网络组织成双线性(bilinear)的形式。即可以把某个条件加入到其部分前驱条件之前,而不必是所有的前驱条件前。下图说示即为线性Uni-Rete与双线性Uni-Rete的对比图。双线性Uni-Rete中,包括两部分条件链,(CE1,CE2,CE3,CE4)和(CE1,CE2,CE3,CE4)。这两部分被一个super-p-node连接起来。Super-p-node进行在biliner中未能进行的一致性检查。
使用biliner结构的好处实现是更大程度的共享。缺点是增加了在super-p-node 中的一致性检测的操作。
在一般情况下,采用biliner一般会降低Rete算法的性能,这是因为,1、增加了匹配活动;2、实现复杂;3、共用程度可能没有在使用特有属性表示法的系统高。
六、 评论
Uni-Rete是Rete的一个特殊情况,可以很容易的与Rete结合使用。Uni-Rete可以用在部分含有特有属性表示法的系统中。可以有两种方法把Uni-Rete和Rete结合起来使用,一种是把Uni-Rete用于特有属性的产生式,把Rete用于其它产生式;另一种是在一条产生式中,把Uni-Rete用于特有属性表示的条件中,而把Rete用于其它条件中。
Uni-Rete的一个贡献是通过减少对tokens的动态内存管理而提高性能。像Rete这样的匹配算法都假定tokens的数目在匹配时无法确定,因此需要动态分配内存。而在很多情况下,token内存的大小可以预测,Uni-Rete便利用这一特点使用静态数据结构来提高性能。
注:本文参考自
Toru Ishida. An Optimization Algorithm for Production Systems. IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, VOL. 6, NO. 4. AUGUST 1994.)
产生式系统的优化算法
一、 简介
产生式系统的系统随着事实数目的增多,性能也跟着下降。因为在大多数的系统中,匹配过程中的连接(join)操作花费的时间与事实数目的平方成正比。另外,不当的条件排列顺序可以产生大量的中间数据,从而导致大量的join操作。
为了解决这个问题,ART、YES/OPS以及其他的一些系统允许用户自己设定join结构。在没有一个专门的优化器来确定join的最佳机构时,专家系统的设计者一般都是采用手动的方式来设定join结构。本文提出了一种优化算法可以减小产生式系统中的join操作的开销。此算法并不是直接将启发式算法用在规则上,而是列举可能的join结构,从而选出最佳结构。主要的思想是采用一些有效约束条件来减少可能结构数目。引入一个代价模型(cost model)来估计在不同join结构中的进行join操作的代价。测试结果显示,采用本算法,可以产生和手动设置一样有效的程序。
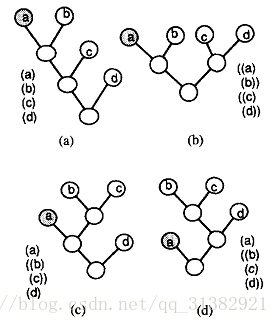
二、 Join拓扑结构(topological transformation)
规则的条件可以有多种拓扑结构,如下图所示,条件(a, b, c, d)可以有以下四种结构,如果条件的顺序可变,则join的结构可以达到4*4!=96种。因此,可能的join结构的数目与条件的个数的指数在一个数量级上。
三、 Rete算法特点
Rete算法中的启发式(heuristic)特点有:
3.1 约束性条件优先(place restrictive conditions first)
中间数据(即tokens)所进行的操作占据了总的join操作的绝大部分。减少中间数据的方法之一就是把约束性条件先进行join操作。如下图所示,含有事实越少的alpha内存越优先。
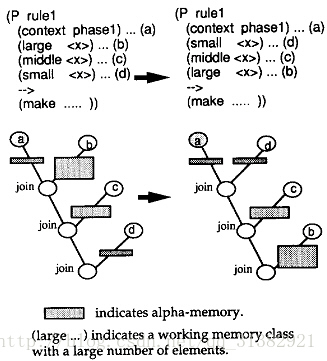
3.2 将易变的规则置后(place volatile conditions last)
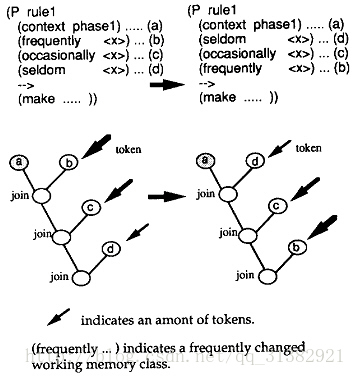
假设有N条规则,如果添加(或删除)第一条规则对应的事实,则其余N-1个规则的节点的Join操作到要重复进行。但是,如果此事实对应的规则是第N条,那么只要进行一次join操作。为了减少join操作的次数,把易变的事实对应的规则放在放在后面。如下图所示。
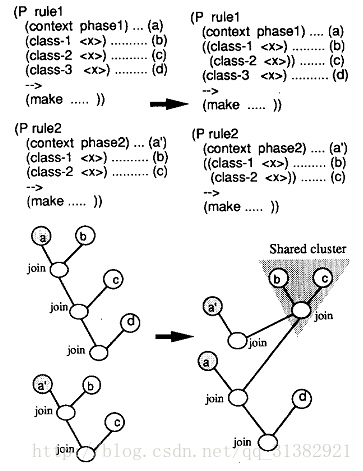
3.3 在规则间共享Join块(share join clusters among rules)
如果某个Join块(join cluser)被N条规则共享,则相当于此join操作的代价降低到原来的1/n。为了获得更大的共享块,一般改变规则的Join结构。如下图所示。
以上启发式算法是rete算法的重要特点。但是,因为不同的启发式算法之间存在冲突,因此专家系统设计者在如何设计一个更好的Join结构时往往要走很多弯路。本文提出的优化算法可以实现join结构的各种拓扑转换,同时自动估计各种结构的性能。
四、 代价模型(cost model)
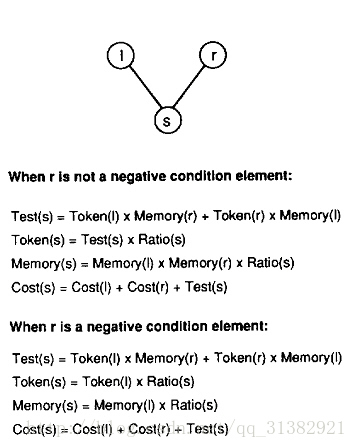
本文引入的代价模型如下图所示:
在代价模型中,每个节点n都有五个参数:Token(n), Memory(n), Test(n), Cost(n)和Ratio(n)。Token(n)指从节点n传递到其后继节点的所有tokens的数目。Memory(n)指n节点内存中平均存储的tokens数目。Test(n)指n节点总共进行的join测试数目。Cost(n)指在n节点进行的join操作所花费的代价,用一个代价函数来确定。Ration(n)是n节点上join测试成功的比例。
在系统优化时,创建不同的Join结构并且评价其性能。
在开始优化前,产生式系统先运行一边,记录下每个节点的Test(n), Token(n), Memory(n)。
五、 优化算法
正如第三部分所述,启发式算法不能单独应用,因为它们之间可能会有冲突。同时,join结构的可能数目与节点数的指数级是一个数量级的,
因此,产生——测试(generate-and-test)的方法不能解决这个问题。本文中采用不同的约束限制条件来产生可能的Join结构,极大减少了需
要检测的join结构的数目。
5.1 具体算法步骤是:
1、 根据程序的运行确定各个规则的代价大小,按降序排列。从代价最高的规则开始优化。这样保证代价较高的规则有较大的自由度来选
择Join结构。
2、 在优化各个规则前,先把每个alpha节点和beta节点加入到join-list中去。
3、 在优化每个节点时,从Join-list上选择两个节点,创建它们的join节点。如果在join-list没有与新创建的Join结构相同的节点,则
把此节点加入到Join-list中去。
4、 创建每个可能的Join结构后,从中选出最低代价的结构。
5.2 约束条件
上面的算法用到了下面的约束条件来减少可能的join结构数目。
最少代价约束(minimal-cost constraint)
最少代价约束是指,如果某个将要创建的节点比目前Join-list中已存在的节点的代价高,则不创建此节点。形式化定义为,如果满足下面条件
,则不创建s节点:
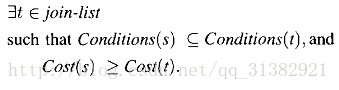
其中,conditions(s)指s节点的Join结构中的条件集合。
连接约束(connectivity constraint)
连接约束是指,当两个节点之间没有共同变量时,不创建这两个节点的join节点。例如,p, q是规则中的alpha节点。如果满足如下条件,则不
创建l, r的连接节点s:
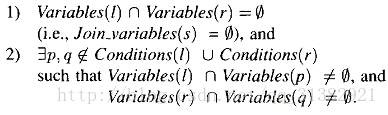
其中,variables(l)指l的join结构中的变量结合。
在下图所示的例子中,节点b和d不能执行join操作,因为它们之间没有共享变量(满足条件1),同时存在一个c节点,使它们满足条件2。但a,
b可以执行join操作,因为,虽然满足条件1但不满足条件2。
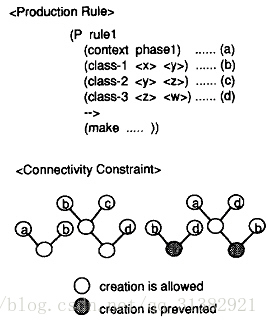
优先级约束
根据统计数据可以确定各个alpha的节点的优先级。优先级约束是指,当进行join操作时,先把优先级高的节点进行Join。更为形式化的定义
:p, q都是alpha节点,且p>q(即p的优先级高于q)。那么不创建l, r的join节点,如果满足如下条件:

面p>q的定义是当且仅当token(p)>token(q)且memory(p)>memory(q)。引入条件二是为了防止这样一种情况,即,当l和r因为优先级约束不能
Join时,l和p因为连接约束也不能进行join。连接约束和优先级约束可以显著的减少搜索可能范围,但是有可能漏掉在最优结构。
六、 试验结果
把本文所述的优化器用于类似与ops5的系统中。系统配置如下图所示:
实验结果显示,采用优化后,join节点减少到原来的1/3,CPU运行时间减少到原来的1/2,比采用手动优化的效率还高。
不采用优先级约束得到的join结构数目是原来的3.7倍,而同时不使用优先级和连接约束,得到的是原来的6.3倍。根据优化时间与Join结构数
目的平方成正比的规律,优化时间相应的是原来的14到40倍。
本文引入的算法在一个专家系统上测试表明,使用此优化算法同手动优化一样有效。文中提出的代价模型在优化算法中非常重要,但一个完全
精确的模型很难达到。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









