









文章目录
一、概述:
Rete 算法是卡内基梅隆大学的 Charles L.Forgy 博士在 1974 年发表的论文中所阐述的算法。 该算法提供了专家系统的一个高效实现。
Rete 在拉丁语中译为”net”(即网络)。Rete 是一种进行大量模式集合和大量对象集合间比较的高效方法,通过网络筛选的方法找出所有匹配各个模式的对象和规则。其核心思想是用分离的匹配项构造匹配网络,同时缓存中间结果,以空间换时间。步骤大致分为规则编译(rule compilation)和运行时执行(runtime execution)。
二、算法详解:
术语解释:
①facts:事实,指对象之间及对象属性之间的关系。
②patterns:模板,指事实的一个模型,所有事实库中的事实都必须至少匹配模板中的一个。
③conditions:条件,规则的组成部分,也必须至少匹配模板中的一个。
(对于上面三者的关系,可以简单理解为:patterns是一个接口,conditions则是实现这个接口的类,而facts是这个类的实例。)
④rules:规则,由一到多个条件构成。一般用and或or连接conditions。
(如果将一条rule看做if-then语句,if部分称为LHS(left-hand-side),then部分称为RHS(right hand side)。)
⑤module:模式,指上述if语句的条件。这里的条件可能是有几个更小的条件组成的大条件。模式就是指的不能在继续分割下去的最小的原子条件。
⑥actions:动作,激活一条rule所需执行的动作。
进一步了解Rete算法:
Rete算法是一个用于产生式系统的高效模式匹配算法。
在一个产生式系统中,被处理的数据叫做working memory,用于判定的规则分为两个部分LHS(left-hand-side)和RHS(right hand side),分别表示前提和结论。主要流程可以分为以下步骤:
①Match:找出符合LHS部分的working memory集合。
②Conflict Resolution:选出一个条件被满足的规则。
③Act:执行RHS的内容。
④返回①。
Rete算法主要改进Match的处理过程,通过构建一个网络进行匹配。
算法详细描述:
Rete网络主要分为两个部分,alpha网络和beta网络。如下图所示:
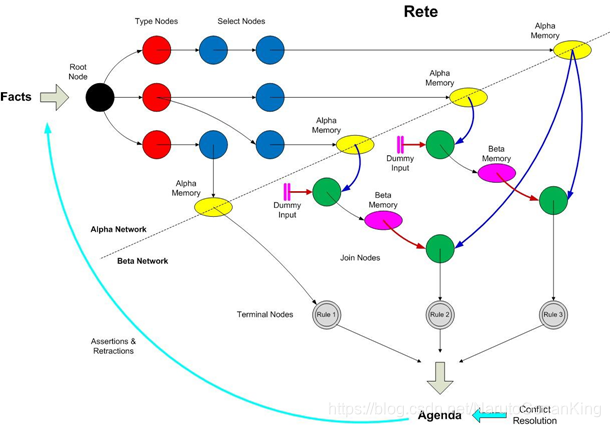
Rete网络内容解析:
①alpha网络:过滤working memory,找出符合规则中每一个模式的集合,生成alpha memory(满足该模式的集合)。有两种类型的节点,过滤type的节点和其他条件过滤的节点。
②beta网络:有两种类型的节点beta memory和join node。前者主要存储join完成后的集合;后者包含两个输入口,分别输入需要匹配的两个集合,由join节点做合并工作传输给下一个节点。
③Root Node:根节点,所有对象进入网络的入口。(在一个网络中只有一个根节点)
④1-input node:单输入节点,可分为ObjectTypeNode、AlphaNode、LeftInputAdapterNode等。
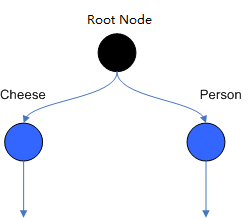
•Object Type Node:facts从Root Node进入Rete网络后,会立即进入Object Type Node节点。Object Type Node提供了按对象类型过滤对象的能力,通过此类节点可使规则引擎不做额外的工作。Cheese类型的facts进入网络后,只需经过类型为Cheese的Object Type Node之后的节点。如下图:
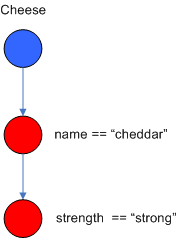
•AlphaNode:Alpha 节点是规则的条件部分的一个模式。通常用于评估字面的条件。如下图,两个Alpha Node 分别评估了Cheese事实的name和strength属性。
•LeftInputAdapterNode:作用是输入一个对象,传播为一个单对象列表(元组)。
⑤2-input node:双输入节点,包含JoinNode和NotNode。JoinNode和NotNode也属于用于比较两个对象和其域的BetaNodes。2-input node有left存储区和right存储区和左右两个输入口,其中left存储区是beta存储区,right存储区是alpha存储区。存储区储存的最小单位是工作存储区元素(Working Memory Element,简称WME),WME是为fact建立的元素,是用于和非根结点代表的module进行匹配的元素。
•Join Node:用作连接(join)操作的节点,相当于数据库的表连接操作。
•NotNode:根据右边输入对左边输入的对象数组进行过滤,两个 NotNode 可以完成 ‘exists’ 检查。
⑥Terminal Node:终端节点,到达一个终端节点,表示单条rule匹配了所有的条件。(网络中有多个终端节点;当单条规则中有or时,也会产生多个终端节点)
Rete网络创建流程分析:
①创建Root Node,推理网络的入口。
②拿到rule1,从rule1中取出module1(模式就是最小的原子条件)。
⑴检查module1中的参数类型,如果是新类型,添加一个Object Type Node。
⑵检查module1对应的AlphaNode是否存在,如果存在记录下节点的位置;如果不存在,将module1作为一个AlphaNode加入到网络中。同时根据AlphaNode建立Alpah内存表。
⑶重复⑵,直到处理完所有模式。
⑷组合Beta节点:Beta2左输入节点为Beta1,右输入节点为Alpha2;Beta(i)左输入节点是Beta(i-1),右输入节点为Alpha(i),并将两个父节点的内存表内联成为自己的内存表。
⑸重复⑷,直到所有Beta节点处理完毕。
⑹将动作then部分封装成最后节点做为Beta(n)。
③重复②,直到所有规则处理完毕。
运行时执行流程分析:
推理引擎在进行模式匹配时,先对facts进行断言,为每一个fact建立WME(Working Memory Element),然后将WME从Rete鉴别网络的Root Node开始匹配,因为WME传递到的结点类型不同采取的算法也不同,所以需要对alpha结点和beta结点处理WME的不同情况而分开讨论。
①如果WME的类型和Root Node的后继结点TypeNode(alpha结点的一种)所指定的类型相同,则会将该fact保存在该TypeNode对应的alpha存储区中,该WME被传到后继结点继续匹配,否则会放弃该WME的后续匹配。
②如果WME被传递到alpha结点,则会检测WME是否和该结点对应的module相匹配。若匹配成功,则会将该fact保存在该alpha结点对应的存储区中,该WME被传递到后继结点继续匹配,否则会放弃该WME的后续匹配。
③如果WME被传递到beta结点的右端,则会加入到该beta结点的right存储区,并和left存储区中的Token进行匹配(匹配动作根据beta结点的类型进行,例如:join,projection,selection)。若匹配成功,则会将该WME加入到Token中,然后将Token传递到下一个结点,否则会放弃该WME的后续匹配。
④如果Token被传递到beta结点的左端,则会加入到该beta结点的left存储区,并和right存储区中的WME进行匹配(匹配动作根据beta结点的类型进行,例如:join,projection,selection)。若匹配成功,则该Token会封装匹配到的WME形成新的Token,传递到下一个结点,否则会放弃该Token的后续匹配。
⑤如果WME被传递到beta结点的左端,将WME封装成仅有一个WME元素的WME列表做为Token,然后按照④所示的方法进行匹配。
⑥如果Token传递到Terminal Node,则和该Root Node对应的规则被激活,建立相应的Activation,并存储到Agenda当中,等待激发。
⑦如果WME被传递到Terminal Node,将WME封装成仅有一个WME元素的WME列表做为Token,然后按照⑥所示的方法进行匹配。
Rete算法的特点:
Rete算法优于传统的模式匹配算法,原因有以下三点:
①Rete 算法是一种启发式算法,不同规则之间往往含有相同的模式,因此在 beta-network 中可以共享 BetaMemory 和 betanode。如果某个 betanode 被 N 条规则共享,则算法在此节点上效率会提高 N 倍。
②Rete 算法由于采用 AlphaMemory 和 BetaMemory 来存储事实,当事实集合变化不大时,保存在 alpha 和 beta 节点中的状态不需要太多变化,避免了大量的重复计算,提高了匹配效率。
③从 Rete 网络可以看出,Rete 匹配速度与规则数目无直接关系,这是因为fact只有满足本节点才会继续向下沿网络传递。
Rete算法的缺点:
①facts的删除与facts的添加顺序相同,除了要执行与facts添加相同的计算外,还需要执行查找,开销很高。
②Rete算法使用了BetaMemory存储已计算的中间结果,以空间换取时间,从而加快系统的速度。然而BetaMemory根据规则的条件与facts的数目而成指数级增长,极端情况下会耗尽系统资源。
针对 Rete 算法的特点和不足,在应用或者开发基于 Rete 算法的规则引擎时,提出如下建议:
①容易变化的规则尽量置后匹配,可以减少规则的变化带来规则库的变化。
②约束性较为通用或较强的模式尽量置前匹配,可以避免不必要的匹配。
③针对 Rete 算法内存开销大和facts增加删除影响效率的问题,技术上应该在 AlphaMemory 和 BetaMemory 中,只存储指向内存的指针,并对指针建里索引(可用 hash 表或者非平衡二叉树)。
④Rete 算法 JoinNode 可以扩展为 AndJoinNode 和 OrJoinNode,两种节点可以再进行组合。














 434
434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









