







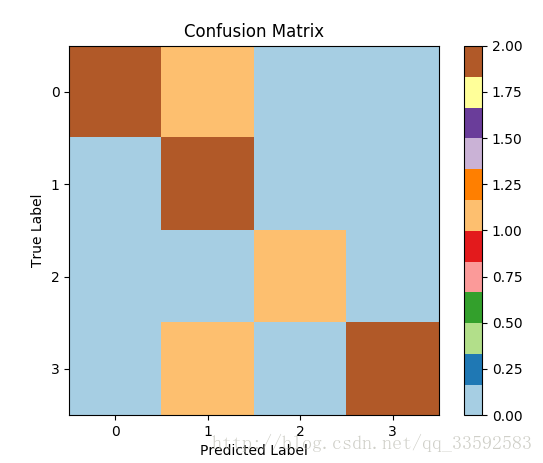
混淆矩阵可视化
代码如下:
#-*- coding:utf-8 -*-
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import confusion_matrix
y_true=[1,0,0,2,1,0,3,3,3]
y_pred=[1,1,0,2,1,0,1,3,3]
#混淆矩阵
confusion_mat=confusion_matrix(y_true,y_pred)
def plot_confusion_matrix(confusion_mat):
plt.imshow(confusion_mat,interpolation='nearest',cmap=plt.cm.Paired)
plt.title('Confusion Matrix')
plt.colorbar()
tick_marks=np.arange(4)
plt.xticks(tick_marks,tick_marks)
plt.yticks(tick_marks,tick_marks)
plt.ylabel('True Label')
plt.xlabel('Predicted Label')
plt.show()
plot_confusion_matrix(confusion_mat)
结论:对角线区域越亮越好
画图显示如下:














 530
530











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









