






下载造数据的包
wget http://elasticmapreduce.s3.amazonaws.com/samples/impala/dbgen-1.0-jar-with-dependencies.jar
有过下载不了就直接去该连接去下载
生成数据
java -cp dbgen-1.0-jar-with-dependencies.jar DBGen -p ./data -b 4 -c 4 -t 4
b,c,t,代表的是三张表,4代表4G,每张表4G
在hbase中创建三张表
create ‘books’,{NAME=>’info’,COMPRESSION=>’snappy’}
create ‘customers’,{NAME=>’info’,COMPRESSION=>’snappy’}
create ‘transactions’,{NAME=>’info’,COMPRESSION=>’snappy’}
创建成功之后,要把文件从本地上传到hdfs中
导入数据到hbase目录下
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator=”|” -Dimporttsv.columns=HBASE_ROW_KEY,info:isbn,info:category, info:publish_date,info:publisher,info:price -Dimporttsv.bulk.output=/tmp/hbase/books books /data/books/books
此时数据已经在hbase目录下,加载数据到hbase表
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /tmp/hbase/books books
然后进入hbase shell
scan books一下,就可以看到数据。
这三张表都是这样,就不在这里一一演示。
下面是hbase pe测试
顺序写(百万)
hbase org.apache.Hadoop.hbase.PerformanceEvaluation sequentialWrite 1
顺序读(百万)
hbase org.apache.hadoop.hbase.PerformanceEvaluation sequentialRead 1
随机写(百万)
hbase org.apache.hadoop.hbase.PerformanceEvaluation randomWrite 1
随机读(百万)
hbase org.apache.hadoop.hbase.PerformanceEvaluation randomRead 1
下面是hbase预分区测试
创建预分区表
create ‘books’,{NAME=>’info’,COMPRESSION=>’snappy’},{SPLITS=>[‘3000000’,’6000000’,’9000000’,’12000000’,’15000000’]}
在hbaseUI看一下表的region的信息
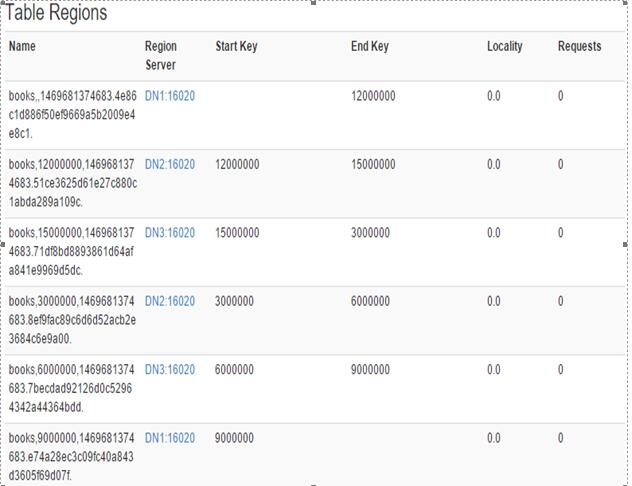
然后根据上边的插入数据的步骤插入数据,在查看一下
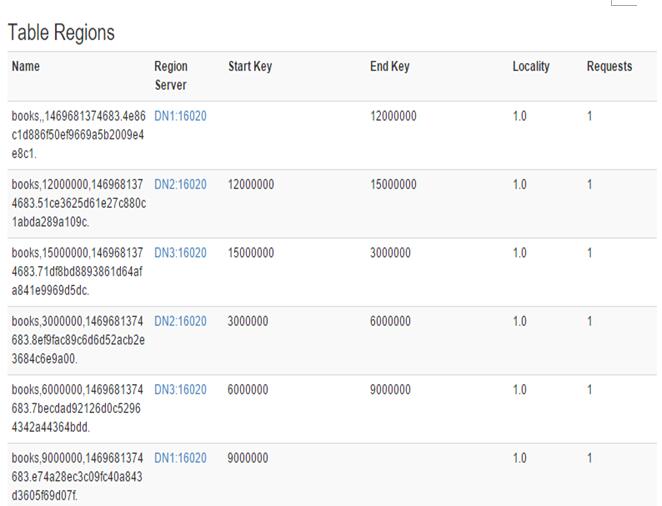
可以看到预分区成功了。
预分区表,就是在建表之前先建好分区,这样就不用,hbase自己去等到数据加载到一定程度之后自己去分割,不过,这并不能解决hot的问题,
想解决hot,预分区是前提,还有用到hash散列,将数据的rowkey打散,分配到不同的region里,这样就不用出现,一直向一个region不停的写不停地写的hot问题。真正的做到了雨露均沾。。。。















 2527
2527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









