










noise的产生
在机器学习中我们在独立随机抽样的时候会出现一些搞错的信息,这些错误的数据我们称之为杂讯(或者噪音 noise),一般可以归结为一下两种(以二分为例):
输出错误:1.同样的一笔数据会出现两种不同的评判 2.在同样的评判下会有不同的后续处理。
输入错误:1.在收集数据的时由于数据源的随机性会出现错误(比如说,客户在填信息的时候出现的误填)
noise的情况下VC维度的可用性
在有noise的情况下我们的资料不会都来自于我们所求的目标函数而是来自于一个带有noise的分布,因此我们的f(x)会在产生资料的时候加上一个波动值后变成了f(x)+noise它具有一定的随机性。
在这里需要注意的是我们的资料产生于一个带有noise的分布,而我们预测的资料也是产生于一个同样的分布。直观的来看只是一个换了分布的机器学习过程。所以VC维度能够在有杂讯的情况下学习,所有的论述过程同这篇文章机器学习与VC维度。
noise的代价
我们能够在有杂讯的资料上学习,通过一个带有杂讯的分布,当然我们会犯错。在遇到一个具体的点的时候,我们会查找这个点在我们的标签分布上的概率p(y | x),比如说这个分布会告诉我们x的概率为0.7,o的概率是0.3那么我们就会选择概率较大的那个选项,但是我们有0.3的几率会犯错,这就是我们的代价。
修正后的机器学习模型图如下:
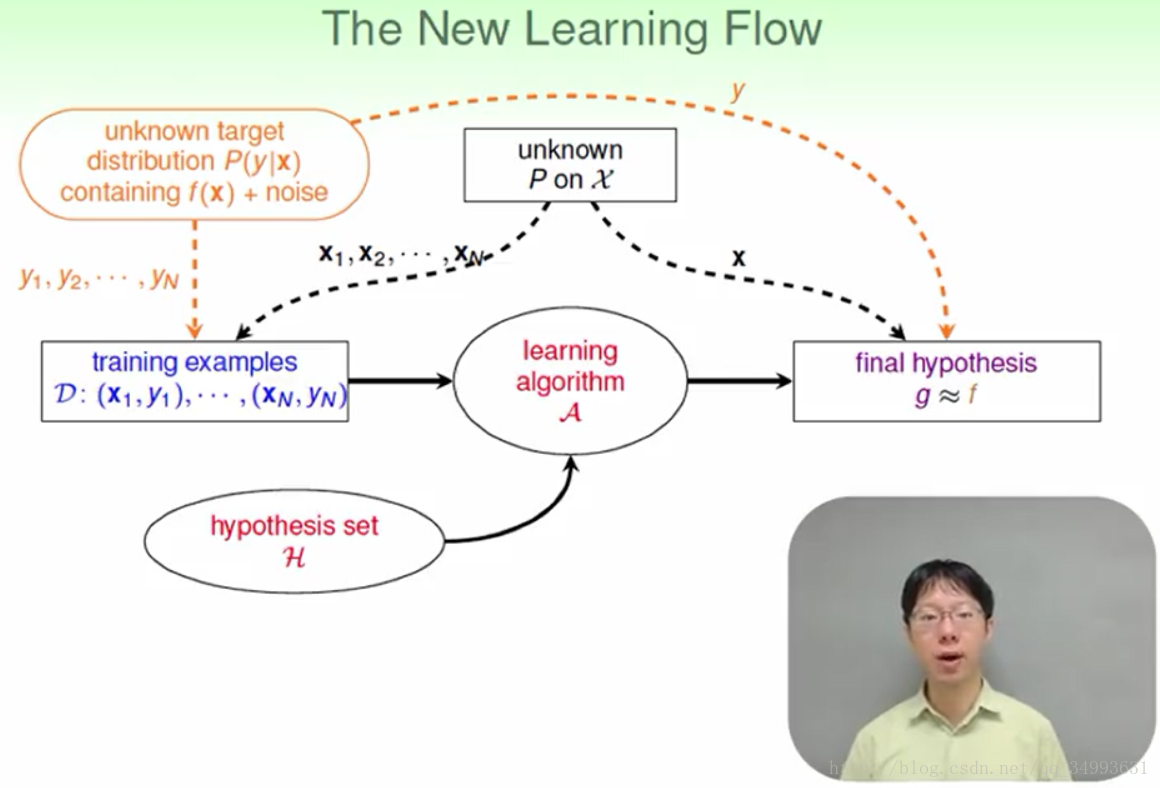
最后感谢台湾大学林轩田老师。
















 220
220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











