







spark由于其良好的生态,比hadoop快地速度,批处理,流式处理等多操作的支持,现在在大数据圈已经非常热门。
spark初了解
spark经常拿来和hadoop作比较,hadoop的MapReduce,是一个简单的Mapper和Reducer的抽象提供一个编程模型,可以在hadoop集群上并发地,分布式地处理大量的数据集,而把并发、分布式(如机器间通信)和故障恢复等计算细节隐藏起来。
但技术总是在进步,MapRecue存在的一些局限,使用起来比较困难。比如只提供两个操作,Map和Reduce,表达力欠缺;一个Job只有Map和Reduce两个阶段(Phase),复杂的计算需要大量的Job完成,Job之间的依赖关系是由开发者自己管理的。中间结果也放在HDFS文件系统中,导致延时很大;只适用Batch数据处理,对于交互式数据处理,实时数据处理的支持不够;对于迭代式数据处理性能比较差等。
而spark呢,Spark是一个新兴的大数据处理的引擎。你可以理解为spark解决了hadoop的MR任务的很多痛点。
spark提出的是“One Stack To Rule Them All”,想让spark囊括一切,可见spark的野心不小呀。看看spark支持的技术栈:
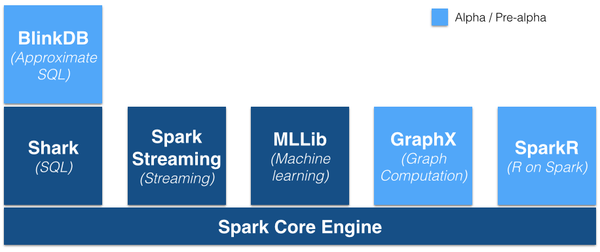
要了解spark,得先说说spark的RDD,这是理解spark的一个核心概念,也是spark对集群中分布式内存的一个抽象,RDD全称是Resilient Distributed Dataset,中文即“弹性分布式数据集”,RDD就是一个不可变的带分区的记录集合,RDD也是Spark中的编程模型,spark一切的操作都是在RDD数据集合上的操作。
spark初体验
要了解一门技术,不去动手体验是学不好的,庆幸的是,spark提供了一个spark-shell,让我们不必一开始就必须学习api才能跑一个spark任务,而是可以从spark-shell交互式的去体验一个spark任务。
如何使用spark-shell,当然,首先你需要安装spark集群,此处就不再多说,我是通过cloudera manager来安装spark的。
下面开启我们的spark体验之旅:
在spark集群机器上输入spark-shell
启动会打印相关日志,也可以看到下面一个图片:
启动完成可以看到输入提示:
scala>
至此,spark启动完成,下面以一个word count来开始体验一下吧。
首先创建一个text.txt文件,上传到hdfs上(hadoop fs -put test.txt /tmp),内容:
I love spark very very very much!scala> val textFile = sc.textFile(“hdfs://hostname:8020/tmp/test.txt”)
显示以下内容:
16/09/08 14:45:54 INFO MemoryStore: ensureFreeSpace(276138) called with curMem=297273, maxMem=278302556
16/09/08 14:45:54 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 269.7 KB, free 264.9 MB)
16/09/08 14:45:54 INFO MemoryStore: ensureFreeSpace(21207) called with curMem=573411, maxMem=278302556
16/09/08 14:45:54 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 20.7 KB, free 264.8 MB)
16/09/08 14:45:54 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on xxxxx:18142 (size: 20.7 KB, free: 265.4 MB)
16/09/08 14:45:54 INFO BlockManagerMaster: Updated info of block broadcast_1_piece0
16/09/08 14:45:54 INFO SparkContext: Created broadcast 1 from textFile at <console>:21
textFile: org.apache.spark.rdd.RDD[String] = hdfs://hostnamexxxx:8020/tmp/test.txt MapPartitionsRDD[3] at textFile at <console>:21执行:
scala> val wordCounts = textFile.flatMap(line => line.split(” “)).map(word => (word, 1)).reduceByKey((a,b) => a + b)
显示以下内容:
16/09/08 16:27:19 INFO FileInputFormat: Total input paths to process : 1
wordCounts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[4] at reduceByKey at <console>:23执行
scala> wordCounts.collect()
可以在最后看到:
16/09/08 16:28:41 INFO DAGScheduler: Job 0 finished: collect at <console>:26, took 3.240093 s
res0: Array[(String, Int)] = Array((love,1), (very,3), (much!,1), (spark,1), (I,1))以上,我们可以在不写代码的情况下来跑spark任务了!
spark初编程
下面演示一下如何通过spark api来写一个任务提交。照样,使用word count示例。
首先需要确定依赖的spark版本,我用的cm安装的spark 1.3.0,因此,我的pom文件是:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.3.0-cdh5.4.0</version>
</dependency>spark的wordCount代码如下
package spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
public class SparkWordCount {
public static void main(String[] args) {
// 指定hdfs文件路径,注意:hostname替换为你的hdfs路径
String filePath = "hdfs://hostname:8020/tmp/test.txt";
// master可以在这里设置,也可以提交任务时候指定,在这里,我们简单的在程序里设置
// 并且,没有指定master的路径,用的是local模式,表示本地内容,2个线程执行
SparkConf sparkConf = new SparkConf().setMaster("local[2]").setAppName("wordCount");
// sc
JavaSparkContext sc = new JavaSparkContext(sparkConf);
// 读文件进来
JavaRDD<String> lines = sc.textFile(filePath);
// flatMap操作,不清楚可以查一下,将字符串映射为序列
JavaRDD<String> words = lines.flatMap(
new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String s) throws Exception {
return Arrays.asList(s.split(" "));
}
}
);
// mapToPair操作,将单词映射为统计值
JavaPairRDD<String, Integer> pairs = words.mapToPair(
new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<String, Integer>(s, 1);
}
}
);
// reduceByKey操作,归并
JavaPairRDD<String, Integer> wordCounts = pairs.reduceByKey(
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer + integer2;
}
}
);
// 查看集合
wordCounts.collect();
}
}mvn package生成jar包为spark-test.jar
在spark上提交任务
spark-submit –class spark.SparkWordCount ./spark-test.jar
其中,–class指定的是main入口类,spark-test.jar为刚刚编译的jar包
提交执行后,即可看到和spark-shell一样的效果。
结语
至此,我们简单了解了spark,使用spark-shell体验了spark的功能,使用spark java api编写了一段小程序。开启spark之路吧!















 1255
1255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









