







决策树最最最基础的三个算法:
对于什么是决策树,决策树的基本概念网上已经多的不能再多了这里不再赘述,直接切入正题,决策树的算法以及实现。
至于遇到的必须要掌握的信息论相关知识,我会在这篇文章里根据自己遇到的知识来持续更新:
-------------------------------------------------------------------------------------------------------------------------
一.ID3
· ID3算法是由Quinlan首先提出的,该算法以信息论为基础,以信息熵和信息增益为衡量标准,从而实现对数据的归纳分类。首先,ID3算法需要解决的问题是如何选择特征作为划分数据集的标准。在ID3算法中,选择信息增益最大的属性作为当前的特征对数据集分类。就是对各个feature信息计算信息增益,然后选择信息增益最大的feature作为决策点将数据分成两部分然后再对这两部分分别生成决策树。
·通过迭代的方式,我们可以得到决策树模型。
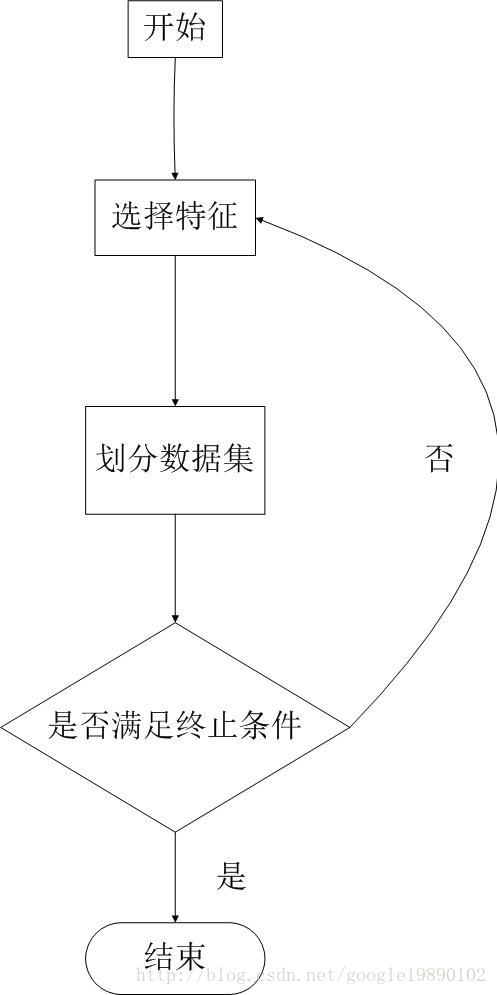

----------------------------------------------------------------------------------------------------------------------------
·实例:
实例:通过这几个指标(age,income,等等)来判断是否买电脑。
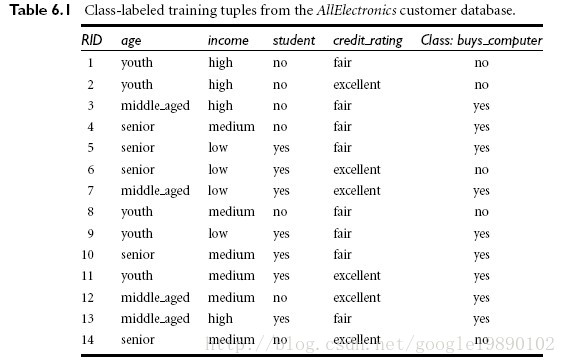
共14条记录,目标属性是,是否买电脑,共有两个情况,yes或者no。
首先需要对数据处理,例如age属性,我们用0表示youth,1表示middle_aged,2表示senior等。
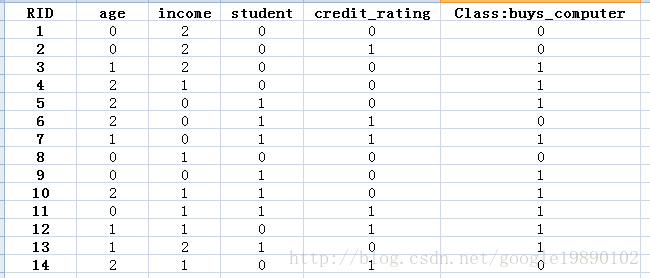
·实例的MATLAB代码:
%% Decision Tree
% ID3
·1、导入数据
%data = [1,1,1;1,1,1;1,0,0;0,1,0;0,1,0];
data = [0,2,0,0,0;
0,2,0,1,0;
1,2,0,0,1;
2,1,0,0,1;
2,0,1,0,1;
2,0,1,1,0;
1,0,1,1,1;
0,1,0,0,0;
0,0,1,0,1;
2,1,1,0,1;
0,1,1,1,1;
1,1,0,1,1;
1,2,1,0,1;
2,1,0,1,0];
% 生成决策树createTree(data);·2、开始创建决策树
%CREATTREE 此处显示有关此函数的摘要
% 此处显示详细说明
function [ output_args ] = createTree( data )
[m,n] = size(data);%m行n列
disp('original data:');
disp(data);%显示导入的数据
classList = data(:,n);
%记录第一个类的个数:
classOne = 1;
for i = 2:m
if classList(i,:) == classList(1,:)
classOne = classOne+1;
end
end
% 类别全相同
if classOne == m
disp('final data: ');
disp(data);
return;
end
% 特征全部用完
if n == 1
disp('final data: ');
disp(data);
return;
end
bestFeat = chooseBestFeature(data);%% 选择信息增益最大的特征
disp(['bestFeat: ', num2str(bestFeat)]);
featValues = unique(data(:,bestFeat));
numOfFeatValue = length(featValues);
for i = 1:numOfFeatValue
createTree(splitData(data, bestFeat, featValues(i,:)));
disp('-------------------------');
end
end·3、选择信息增益最大的特征
%% 选择信息增益最大的特征
function [ bestFeature ] = chooseBestFeature( data )
[m,n] = size(data);% 得到数据集的大小
% 统计特征的个数
numOfFeatures = n-1;%最后一列是类别
% 得到原始的熵
baseEntropy = calEntropy(data);
bestInfoGain = 0;%初始化信息增益
bestFeature = 0;% 初始化最佳的特征位
% 挑选最佳的特征位
for j = 1:numOfFeatures
featureTemp = unique(data(:,j));%得到每个feature的属性
numF = length(featureTemp);%属性的个数
newEntropy = 0;%划分之后的熵
for i = 1:numF
subSet = splitData(data, j, featureTemp(i,:));
[m_1, n_1] = size(subSet);
prob = m_1./m;
newEntropy = newEntropy + prob * calEntropy(subSet);%计算划分之后的熵,此时的subSet里的变量只有一个值(这样复用函数对计算的效率会有点影响)
end
%计算信息增益(熵 - 条件熵)
infoGain = baseEntropy - newEntropy;
if infoGain > bestInfoGain
bestInfoGain = infoGain;
bestFeature = j;
end
end
end
4、一些基础的计算函数
function [ entropy ] = calEntropy( data )
[m,n] = size(data);
% 得到类别的项
label = data(:,n);
% 处理label
label_deal = unique(label);%得到所有的类别
numLabel = length(label_deal);
prob = zeros(numLabel,2);%存储每个标签的个数
% 统计每个标签的个数
for i = 1:numLabel
prob(i,1) = label_deal(i,:);
for j = 1:m
if label(j,:) == label_deal(i,:)
prob(i,2) = prob(i,2)+1;
end
end
end
% 计算熵
prob(:,2) = prob(:,2)./m;%存储每个标签的概率
entropy = 0;
for i = 1:numLabel
entropy = entropy - prob(i,2) * log2(prob(i,2));
end
end
function [ subSet ] = splitData( data, axis, value )
[m,n] = size(data);%得到待划分数据的大小
subSet = data;
%除去第axis个feature,得到剩下的满足第axis列值为value的data
subSet(:,axis) = [];
k = 0;
for i = 1:m
if data(i,axis) ~= value
subSet(i-k,:) = [];
k = k+1;
end
end
从这个例子来看,ID3决策树还是很简单的,就是通过计算信息增益来得到最有价值的那个feature,这样不断迭代,直到遍历完所有的features,从而得到决策树。
决策树ID3算法的不足:
ID3算法虽然提出了新思路,但是还是有很多值得改进的地方。a)ID3没有考虑连续特征,比如长度,密度都是连续值,无法在ID3运用。这大大限制了ID3的用途。
b)ID3采用信息增益大的特征优先建立决策树的节点。很快就被人发现,在相同条件下,取值比较多的特征比取值少的特征信息增益大。比如一个变量有2个值,各为1/2,另一个变量为3个值,各为1/3,其实他们都是完全不确定的变量,但是取3个值的比取2个值的信息增益大。如果校正这个问题呢?
c) ID3算法对于缺失值的情况没有做考虑
d) 没有考虑过拟合的问题
end
-------------------------------------------------------------------------------------------------------------------------
ID3 算法的作者昆兰基于上述不足,对ID3算法做了改进,这就是C4.5算法:
















 4636
4636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











