







 Facebook在机器学习的各个层面应用广泛,包括新闻推送、广告、搜索、图像处理等多个服务。Facebook使用多种机器学习算法,如SVM、GBDT、DNN,以及PyTorch和Caffe2等框架。为了满足大规模运算需求,Facebook采用FBLearner平台,支持GPU和CPU的训练,使用分布式训练策略,并通过内部工具如FBLearner Feature Store和FBLearner Flow管理模型训练和推理。此外,Facebook正积极探索硬件解决方案,如Big Basin GPU服务器,以优化训练性能和资源利用,同时通过ONNX实现框架间模型转换。
Facebook在机器学习的各个层面应用广泛,包括新闻推送、广告、搜索、图像处理等多个服务。Facebook使用多种机器学习算法,如SVM、GBDT、DNN,以及PyTorch和Caffe2等框架。为了满足大规模运算需求,Facebook采用FBLearner平台,支持GPU和CPU的训练,使用分布式训练策略,并通过内部工具如FBLearner Feature Store和FBLearner Flow管理模型训练和推理。此外,Facebook正积极探索硬件解决方案,如Big Basin GPU服务器,以优化训练性能和资源利用,同时通过ONNX实现框架间模型转换。
编译 | 刘畅、尚岩奇、林椿眄
审校 | reason_W
2017年末,Facebook应用机器学习组发布最新论文,对整个Facebook的机器学习软硬件架构进行了介绍。纵览全文,我们也可以从中对Facebook各产品的机器学习策略一窥究竟。论文中涉及到机器学习在全球规模(上亿级数据处理)上的全新挑战,并给出了Facebook的应对策略和解决思路,对相关行业和研究极其有意义。
摘要
机器学习在Facebook的众多产品和服务中都有着举足轻重的地位。 本文将详细介绍Facebook在机器学习方面的软硬件基础架构,如何来满足其全球规模的运算需求。
Facebook的机器学习需求极其繁杂:需要运行大量不同的机器学习模型。这种复杂性已经深深刻在Facebook系统堆栈的所有层面上。此外,Facebook存储的所有数据,有相当大一部分会流经机器学习管道,这样的数据载荷为Facebook的分布式高性能训练流带来巨大的压力。
计算需求也非常紧张,在保持用于训练的GPU/CPU平台的同时平衡出大量CPU容量用于实时推理,也带来了异常紧张的。这些问题及其他难题的解决,仍有待我们在跨越机器学习算法、软件和硬件设计上持久而不懈的努力。
引言
Facebook的使命是“为人类构建社交关系赋能,让世界联系更加紧密”。截至2017年12月,Facebook已经连接了全球超过20亿的人口。同时,过去几年来,机器学习同样在这样一种全球尺度的实际问题上进行着一场革命,包括在机器学习算法创新方面的良性循环,用于模型训练的海量数据以及高性能计算机体系结构的进步。
在Facebook上,机器学习几乎在提升用户体验的所有层面都发挥着关键作用,包括诸如新闻推送语音和文本翻译以及照片和实时视频分类的排名等服务。
Facebook在这些服务中用到了各种各样的机器学习算法,包括支持向量机,梯度boosted决策树和许多类型的神经网络。本文将介绍Facebook的数据中心架构支持机器学习需求的几个重要层面。其架构包括了内部的“ML-as-a-Service”流,开源机器学习框架,和分布式训练算法。
从硬件角度来看,Facebook利用了大量的CPU和GPU平台来训练模型,以便在所需的服务延迟时间内支持模型的训练频率。对于机器学习推理过程,Facebook主要依靠CPU来处理所有主要的服务,而其中神经网络排名服务(比如新闻推送)占据着所有计算负载的大头。
Facebook所存储的海量数据中,有一大部分要流经机器学习管道,并且为了提高模型质量,这一部分的数据量还在随着时间推移不断增加。提供机器学习服务所需的大量数据成为了Facebook的数据中心将要在全球规模上面临的挑战。
目前已有的可被用来向模型高效地提供数据的技术有,数据反馈和训练的解耦操作,数据/计算协同定位和网络优化。与此同时,Facebook公司这样大的计算和数据规模自身还带来了一个独特的机会。在每天的负载周期内,非高峰期都会空闲出大量可以用来进行分布式训练算法的CPU。
Facebook的计算集群(fleet)涉及到数十个数据中心,这样大的规模还提供了一种容灾能力。及时交付新的机器学习模型对于Facebook业务的运营是非常重要的,为了保证这一点,容灾规划也至关重要。
展望未来,Facebook希望看到其现有的和新的服务中的机器学习使用频率快速增长。当然,这种增长也将为负责这些服务架构的团队在全球规模的拓展性上带来更加严峻的挑战。尽管在现有平台上优化基础架构对公司是一个重大的机遇,但我们仍然在积极评估和摸索新的硬件解决方案,同时保持对于算法创新的关注。
本文(Facebook对机器学习的看法)的主要内容包括:
- 机器学习正在被广泛应用在Facebook几乎所有的服务,而计算机视觉只占资源需求的一小部分。
- Facebook所需的大量机器学习算法极其繁杂,包括但不限于神经网络
- 我们的机器学习管道正在处理海量的数据,而这会带来计算节点之外的工程和效率方面的挑战。
- Facebook目前的推理过程主要依靠CPU,训练过程则是同时依靠CPU和GPU。但是从性能功耗比的角度来看,应当不断对新的硬件解决方案进行摸索和评估。
- 全球用户用来使用Facebook的设备每天都可达数亿台,而这会就会提供大量可以用于机器学习任务的机器,例如用来进行大规模的分布式训练。
Facebook的机器学习
机器学习(ML)是指利用一系列输入来建立一个可调模型,并利用该模型创建一种表示,预测或其他形式的有用信号的应用实例。
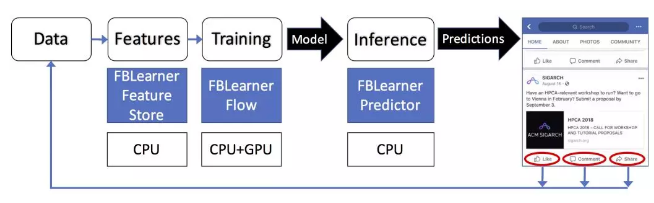
图1所示的流程由以下步骤组成,交替执行:
- 建立模型的训练阶段。这个阶段通常离线运行。
- 在应用中运行训练模型的推理阶段,并进行(一组)实时预测。这个阶段是在线执行的。
模型进行训练的频率要比推理少得多——推理的时间规模虽然在不断变化,但一般在几天左右。训练也需要相当长的时间来完成,通常是几个小时或几天。同时,根据产品实际需求不同,在线推理阶段每天可能运行达数十万次,而且一般需要实时进行。在某些情况下,特别是对于推荐系统,还需要以这样连续的方式在线进行额外的训练。
在Facebook,机器学习的一个显著特征就是有可用于模型训练的海量数据。这个数据的规模会带来很多涉及到整个机器学习架构的影响。
使用机器学习的主要服务
消息推送
消息推送排名算法能够使用户在每次访问Facebook时,最先看到对他们来讲最重要的事情。一般模型会通过训练来确定影响内容排序的各种用户和环境因素。之后,当用户访问Facebook时,该模型会从数千个候选中生成一个最佳推送,它是一个图像和其他内容的个性化集合,以及所选内容的最佳排序。
广告
广告系统利用机器学习来确定向特定用户显示什么样的广告。通过对广告模型进行训练,我们可以了解用户特征,用户上下文,以前的互动和广告属性,进而学习预测用户在网站上最可能点击的广告。之后,当用户访问Facebook时,我们将输入传递进训练好的模型运行,就能立马确定要显示哪些广告。
搜索
搜索会针对各种垂直类型(例如,视频,照片,人物,活动等)启动一系列特定的子搜索进程。分类器层在各类垂直类型的搜索之前运行,以预测要搜索的是垂直类型中的哪一个,否则这样的垂直类型搜索将是无效的。分类器本身和各种垂直搜索都包含一个训练的离线阶段,和一个运行模型并执行分类和搜索功能的在线阶段。
Sigma
Sigma是一个分类和异常检测通用框架,用于监测各种内部应用,包括站点的完整性,垃圾邮件检测,支付,注册,未经授权的员工访问以及事件推荐。Sigma包含了在生产中每天都要运行的数百个不同的模型,并且每个模型都会被训练来检测异常或更一般地分类内容。
Lumos
Lumos能够从图像及其内容中提取出高级属性和映射关系,使算法能够自动理解它们。这些数据可以用作其他产品和服务的输入,比如通过文本的形式。
Facer
Facer是Facebook的人脸检测和识别框架。给定一张图像,它首先会寻找该图像中所有的人脸。然后通过运行针对特定用户的人脸识别算法,来确定图中的人脸是否是该用户的好友。Facebook通过该服务为用户推荐想要在照片中标记的好友。
语言翻译
语言翻译是涉及Facebook内容的国际化交流的服务。Facebook支持超过45种语言之间的源语言或目标语言翻译,这意味着Facebook支持2000多个翻译方向,比如英语到西班牙语,阿拉伯语到英语。通过这2000多个翻译通道,Facebook每天提供4.5B字的翻译服务,通过翻译用户的消息推送,Facebook每天可为全球6亿人减轻语言障碍。目前,每种语言对方向都有其自己的模型,但是我们也正在考虑多语言模型[6]。
语音识别
语音识别是将音频流转换成文本的服务。它可以为视频自动填补字幕。目前,大部分流媒体都是英文的,但在未来其他语言的识别也将得到支持。另外,非语言的音频文件也可以用类似的系统(更简单的模型)来检测。
除了上面提到的主
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1245
1245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









