







作者:汪彪,阿里iDST视觉计算组算法专家
人脸识别技术不但吸引了Google、Facebook、阿里、腾讯、百度等国内外互联网巨头的大量研发投入,也催生了Face++、商汤科技、Linkface、中科云从、依图等一大波明星创业公司,在视频监控、刑事侦破、互联网金融身份核验、自助通关系统等方向创造了诸多成功应用案例。本文试图梳理人脸识别技术发展,并根据作者在相关领域的实践给出一些实用方案设计,期待能对感兴趣的读者有所裨益。
概述
通俗地讲,任何一个的机器学习问题都可以等价于一个寻找合适变换函数的问题。例如语音识别,就是在求取合适的变换函数,将输入的一维时序语音信号变换到语义空间;而近来引发全民关注的围棋人工智能AlphaGo则是将输入的二维布局图像变换到决策空间以决定下一步的最优走法;相应的,人脸识别也是在求取合适的变换函数,将输入的二维人脸图像变换到特征空间,从而唯一确定对应人的身份。
一直以来,人们都认为围棋的难度要远大于人脸识别,因此,当AlphaGo以绝对优势轻易打败世界冠军李世乭九段和柯洁九段时,人们更惊叹于人工智能的强大。实际上,这一结论只是人们的基于“常识”的误解,因为从大多数人的切身体验来讲,即使经过严格训练,打败围棋世界冠军的几率也是微乎其微;相反,绝大多数普通人,即便未经过严格训练,也能轻松完成人脸识别的任务。然而,我们不妨仔细分析一下这两者之间的难易程度:在计算机的“眼里”,围棋的棋盘不过是个19x19的矩阵,矩阵的每一个元素可能的取值都来自于一个三元组{0,1,2},分别代表无子,白子及黑子,因此输入向量可能的取值数为3的361次方;而对于人脸识别来讲,以一幅512x512的输入图像为例,它在计算机的“眼中”是一个512x512x3维的矩阵,矩阵的每一个元素可能的取值范围为0~255,因此输入向量可能的取值数为256的786432次方。虽然,围棋AI和人脸识别都是寻求合适的变换函数f,但后者输入空间的复杂度显然远远大于前者。
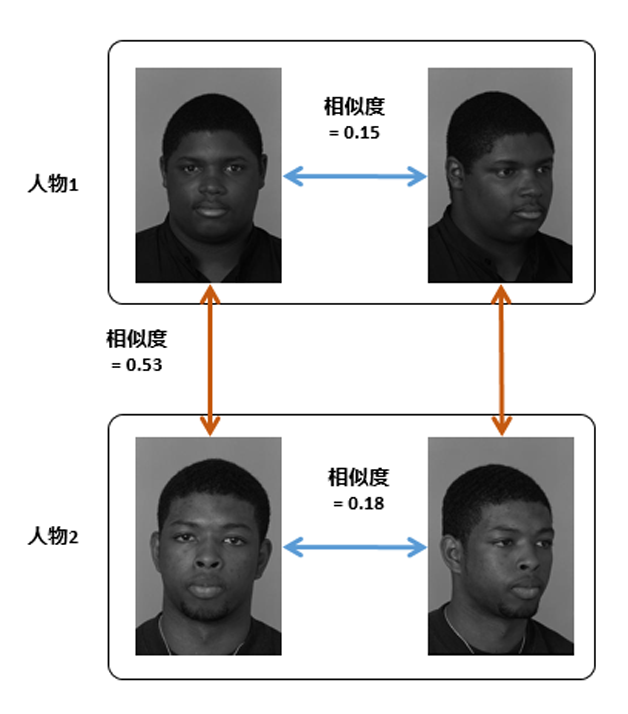
对于一个理想的变换函数f而言,为了达到最优的分类效果,在变换后的特征空间上,我们希望同类样本的类内差尽可能小,同时不同类样本的类间差尽可能大。但是,理想是丰满的,现实却是骨感的。由于光照、表情、遮挡、姿态等诸多因素(如图1)的影响,往往导致不同人之间的差距比相同人之间差距更小,如图2。人脸识别算法发展的历史就是与这些识别影响因子斗争的历史。

人脸识别技术发展
早在20世纪50年代,认知科学家就已着手对人脸识别展开研究。20世纪60年代,人脸识别工程化应用研究正式开启。当时的方法主要利用了人脸的几何结构,通过分析人脸
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









