







 本文详细分析了VGG模型,重点探讨了其使用小卷积核(3x3)和小池化核(2x2)的原因。VGG网络通过多层小卷积核堆叠,有效控制计算量并增加模型容量,提高分类性能。此外,小池化核有助于捕捉更细腻信息,减小特征图尺寸。实验表明,深度增加和小卷积核策略显著提高了模型性能,特别是在ImageNet竞赛中取得了优异成绩。
本文详细分析了VGG模型,重点探讨了其使用小卷积核(3x3)和小池化核(2x2)的原因。VGG网络通过多层小卷积核堆叠,有效控制计算量并增加模型容量,提高分类性能。此外,小池化核有助于捕捉更细腻信息,减小特征图尺寸。实验表明,深度增加和小卷积核策略显著提高了模型性能,特别是在ImageNet竞赛中取得了优异成绩。
如今深度学习发展火热,但很多优秀的文章都是基于经典文章,经典文章中的一句一词都值得推敲和分析。此外,深度学习虽然一直被人诟病缺乏足够令人信服的理论,但不代表我们不能感性分析理解,下面我们将对2014年夺得ImageNet的定位第一和分类第二的VGG网络进行分析,在此过程中更多的是对这篇经典文章的感性分析,希望和大家共同交流产生共鸣,如果有理解不到位的也真诚期待指出错误。

Simonyan, Karen, and Andrew Zisserman. “Very deep convolutional networks for large-scale image recognition.” arXiv preprint arXiv:1409.1556 (2014).
论文下载地址:https://arxiv.org/pdf/1409.1556.pdf
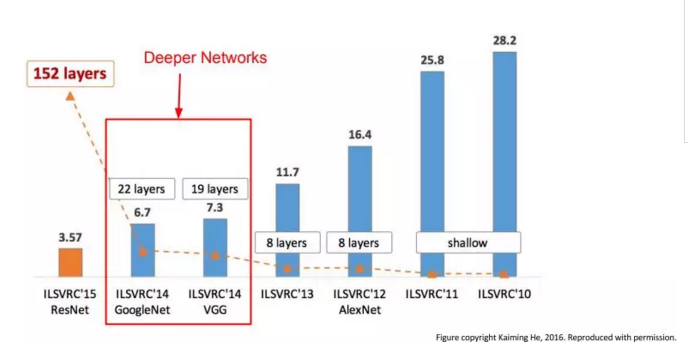
这篇文章是以比赛为目的——解决ImageNet中的1000类图像分类和定位问题。在此过程中,作者做了六组实验,对应6个不同的网络模型,这六个网络深度逐渐递增的同时,也有各自的特点。实验表明最后两组,即深度最深的两组16和19层的VGGNet网络模型在分类和定位任务上的效果最好。作者因此斩获2014年分类第二(第一是GoogLeNet),定位任务第一。
其中,模型的名称——“VGG”代表了牛津大学的Oxford Visual Geometry Group,该小组隶属于1985年成立的Robotics Research Group,该Group研究范围包括了机器学习到移动机器人。下面是一段来自知乎对同年GoogLeNet和VGG的描述:
GoogLeNet和VGG的Classification模型从原理上并没有与传统的CNN模型有太大不同。大家所用的Pipeline也都是:训练时候:各种数据Augmentation(剪裁,不同大小,调亮度,饱和度,对比度,偏色),剪裁送入CNN模型,Softmax,Backprop。测试时候:尽量把测试数据又各种Augmenting(剪裁,不同大小),把测试数据各种Augmenting后在训练的不同模型上的结果再继续Averaging出最后的结果。
需要注意的是,在VGGNet的6组实验中,后面的4个网络均使用了pre-trained model A的某些层来做参数初始化。虽然作者没有提该方法带来的性能增益,但我认为是很大的。不过既然是开篇,先来看看VGG的特点:
- 小卷积核。作者将卷积核全部替换为3x3(极少用了1x1);
- 小池化核。相比AlexNet的3x3的池化核,VGG全部为2x2的池化核;
- 层数更深特征图更宽。基于前两点外,由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,计算量的增加放缓;
- 全连接转卷积。网络测试阶段将训练阶段的三个全连接替换为三个卷积,测试重用训练时的参数,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入。
最后我会再次引用CS231n对于VGG的中肯评价进行总结,不过还是先从当时的任务和历史背景开始说明。
任务背景

自从2012年AlexNet将深度学习的方法应用到ImageNet的图像分类比赛中并取得state of the art的惊人结果后,大家都竞相效仿并在此基础上做了大量尝试和改进,先从两个性能提升的例子说起:
- 小卷积核。在第一个卷积层用了更小的卷积核和卷积stride(Zeiler & Fergus, 2013; Sermanet et al., 2014);
- 多尺度。训练和测试使用整张图的不同尺度(Sermanet et al., 2014; Howard, 2014)。
作者也是看到这两个没有谈到深度的工作,因而受到启发,不仅将上面的两种方法应用到自己的网络设计和训练测试阶段,同时想再试试深度对结果的影响。
小卷积核
说到网络深度,这里就不得不提到卷积,虽然AlexNet有使用了11x11和5x5的大卷积,但大多数还是3x3卷积,对于stride=4的11x11的大卷积核,我认为在于一开始原图的尺寸很大因而冗余,最为原始的纹理细节的特征变化用大卷积核尽早捕捉到,后面的更深的层数害怕会丢失掉较大局部范围内的特征相关性,后面转而使用更多3x3的小卷积核(和一个5x5卷积)去捕捉细节变化。
而VGGNet则清一色使用3x3卷积。因为卷积不仅涉及到计算量,还影响到感受野。前者关系到是否方便部署到移动端、是否能满足实时处理、是否易于训练等,后者关系到参数更新、特征图的大小、特征是否提取的足够多、模型的复杂度和参数量等等。
计算量
在计算量这里,为了突出小卷积核的优势,我拿同样conv3x3、conv5x5、conv7x7、conv9x9和conv11x11,在224x224x3的RGB图上(设置pad=1,stride=4,output_channel=96)做卷积,卷积层的参数规模和得到的feature map的大小如下:
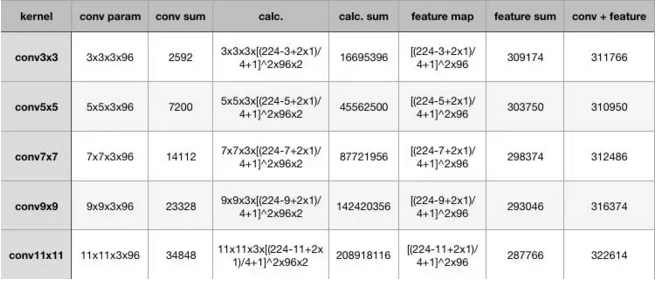
从上表可以看出,大卷积核带来的特征图和卷积核得参数量并不大,无论是单独去看卷积核参数或者特征图参数,不同kernel大小下这二者加和的结构都是30万的参数量,也就是说,无论大的卷积核还是小的,对参数量来说影响不大甚至持平。
增大的反而是卷积的计算量,在表格中列出了计算量的公式,最后要乘以2,代表乘加操作。为了尽可能证一致,这里所有卷积核使用的stride均为4,可以看到,conv3x3、conv5x5、conv7x7、conv9x9、conv11x11的计算规模依次为:1600万,4500万,1.4亿、2亿,这种规模下的卷积,虽然参数量增长不大,但是计算量是惊人的。
总结一下,我们可以得出两个结论:
- 同样stride下,不同卷积核大小的特征图和卷积参数差别不大;
- 越大的卷积核计算量越大。
其实对比参数量,卷积核参数的量级在十万,一般都不会超过百万。相比全连接的参数规模是上一层的feature map和全连接的神经元个数相乘,这个计算量也就更大了。其实一个关键的点——多个小卷积核的堆叠比单一大卷积核带来了精度提升,这也是最重要的一点。
感受野
说完了计算量我们再来说感受野。这里给出一张VGG作者的PPT,作者在VGGNet的实验中只用了两种卷积核大小:1x1和3x3。作者认为两个3x3的卷积堆叠获得的感受野大小,相当一个5x5的卷积;而3个3x3卷积的堆叠获取到的感受野相当于一个7x7的卷积。
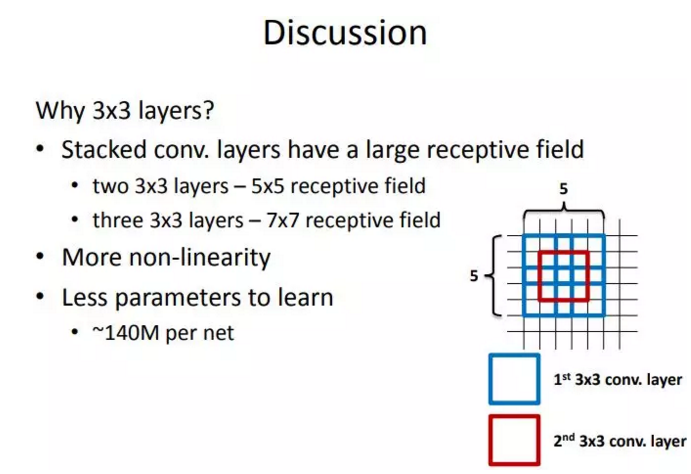
见下图,输入的8个元素可以视为feature map的宽或者高,当输入为8个神经元经过三层conv3x3的卷积得到2个神经元。三个网络分别对应stride=1,pad=0的conv3x3、conv5x5和conv7x7的卷积核在3层、1层、1层时的结果。因为这三个网络的输入都是8,也可看出2个3x3的卷积堆叠获得的感受野大小,相当1层5x5的卷积;而3层的3x3卷积堆叠获取到的感受野相当于一个7x7的卷积。
- input=8,3层conv3x3后,output=2,等同于1层conv7x7的结果;
- input=8,2层conv3x3后,output=2,等同于2层conv5x5的结果。
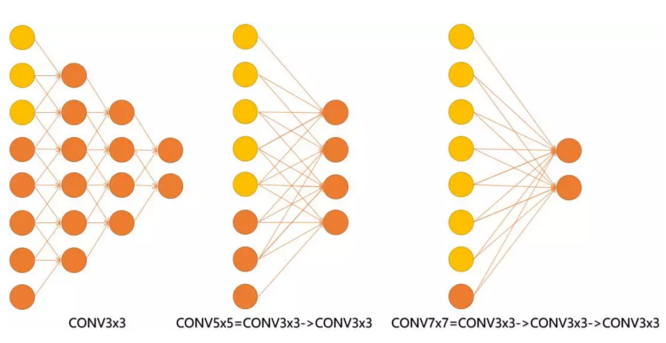
或者我们也可以说,三层的conv3x3的网络,最后两个输出中的一个神经元,可以看到的感受野相当于上一层是3,上上一层是5,上上上一层&#x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 858
858

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









