







在敲《Python机器学习及实践》上自然语言处理包(NLTK)上code的时候,导入nltk之后,运行出现LookupError: Recource 'tokenizers/punkt/english.pickle' not found的错误信息。(注:本错误基于Anaconda)
代码如下:
# 将上述两个句子以字符串的数据类型分别存储在变量sent1与sent2中
sent1 = 'The cat is walking in the bedroom.'
sent2 = 'A dog was running across the kitchen.'
# 从sklearn.feature_extraction.text中导入CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
count_vec = CountVectorizer()
sentences = [sent1, sent2]
# 输出特征向量化后的表示
print(count_vec.fit_transform(sentences).toarray())
# 输出向量各个维度的特征含义
print(count_vec.get_feature_names())
# 导入NLTK
import nltk
# 对句子进行词汇分割和正规化,有些情况如aren't需要分割为are和n't;或者I'm要分割为I和'm
tokens_1 = nltk.word_tokenize(sent1)
print(tokens_1)
tokens_2 = nltk.word_tokenize(sent2)
print(tokens_2)
错误提示信息:
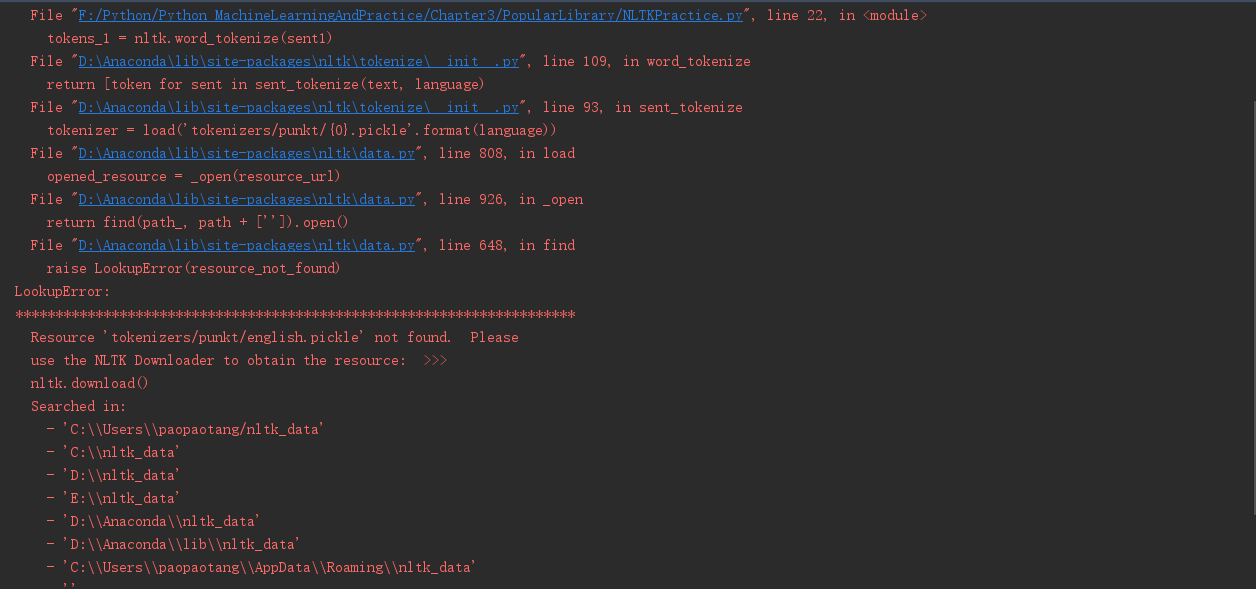
解决方案:
(1)在import nltk之后,调用之前,添加下面一句代码:
nltk.download()(2)然后在弹出的“NLTK Downloader”中设置路径,如下图:
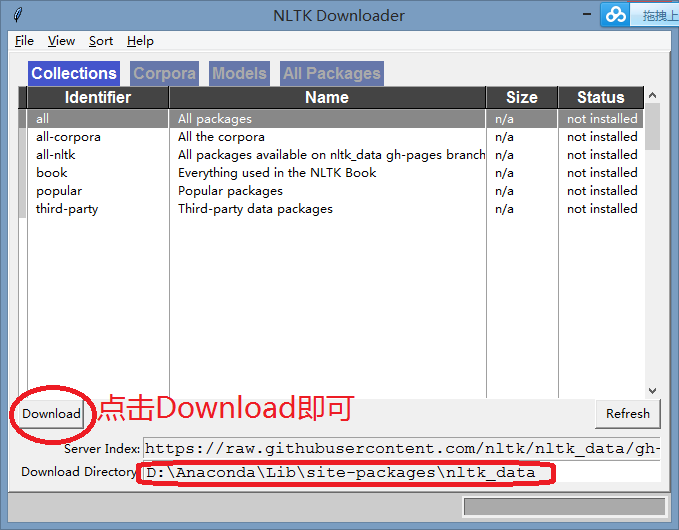
(3)配置环境变量(如果采用默认路径,不需要配置)
打开系统 --> 高级系统设置 --> 高级 --> 环境变量中,先新建一个用户变量,如下图:
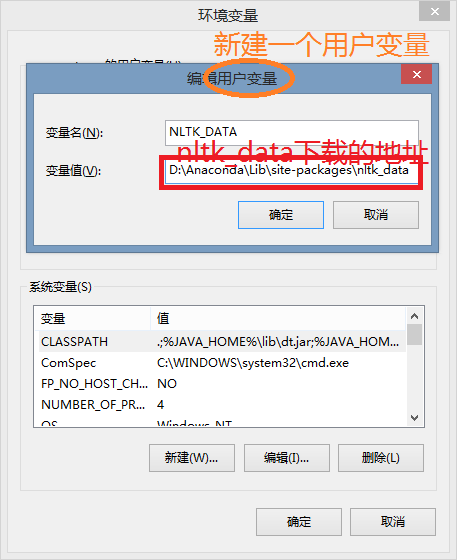
然后将此用户变量添加到系统变量CLASSPATH中:

# 将上述两个句子以字符串的数据类型分别存储在变量sent1与sent2中
sent1 = 'The cat is walking in the bedroom.'
sent2 = 'A dog was running across the kitchen.'
# 从sklearn.feature_extraction.text中导入CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
count_vec = CountVectorizer()
sentences = [sent1, sent2]
# 输出特征向量化后的表示
print(count_vec.fit_transform(sentences).toarray())
# 输出向量各个维度的特征含义
print(count_vec.get_feature_names())
# 导入NLTK
import nltk
nltk.download()
# 对句子进行词汇分割和正规化,有些情况如aren't需要分割为are和n't;或者I'm要分割为I和'm
tokens_1 = nltk.word_tokenize(sent1)
print(tokens_1)
tokens_2 = nltk.word_tokenize(sent2)
print(tokens_2)
注意:
1、可能要等一会,因为需要下载一些文件。
2、下载完成之后,可以把加入的那句代码删除,因为不需要再次下载,下次直接运行即可














 7476
7476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









