







1. 功能需求
本文链接:http://blog.csdn.net/quzhongxin/article/details/46700787
在服务器实现过程中,服务端需要接受客户端的get和put两种操作,
put(key, value): 在接收一定数量的数据后需要将数据保存到磁盘上,并且需要检查是否存在相同的key;
get(key): 向服务端查询是否存在该key;
上述两种操作都涉及了磁盘文件的操作,由于磁盘 IO 访问速度慢,因此为了加速在磁盘文件中的查找,本文实现了一种Hash LRU Cache.
HashCache 实现了一种基于文件页的LRU Cache 功能,通过建立磁盘缓存的模式,实现了对磁盘文件的快速查找。
2. 实现思想
- 写回策略:读写缓存共用,将数据写入到缓存,当数据被置换出cache时,将dirty数据同步到磁盘。(多次修改一次写回)。更多缓存策略
- LRU 策略:由于cache的空间时一定的,且根据局部性原理,置换最久未被访问(get or put)的页面,将极大减少磁盘文件的访问,提高效率。了解更多
- 散列:为了在cache中快速检索,将cache中的数据按散列表的形式组织,实现O(1)访问
3. 缺点
存在一致性问题。
4. 实现过程
<注> LRU 中使操作的单位是page, hash_table 中存储的是每一个page中的所有数据节点的地址,即操作单位是node*,LRU和hash_table中的数据节点的value值会同步修改。LRU用以存储,HashTable用以查找,二者之间是映射关系,但不是在地址上顺序映射的。
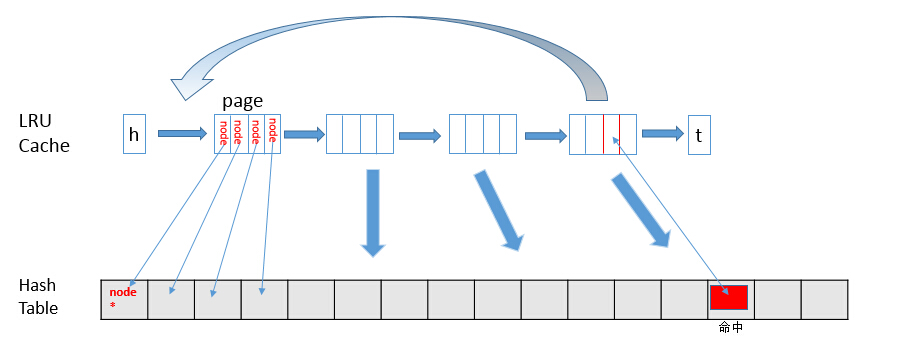
- 设定 Cache 包含 N 页,每页可以容纳 M 个数据节点,使每M个数据节点有对应的一页
- 设定 每个磁盘文件的大小为 M,即一页对应一个文件(因为实在不知,如何更简便的对一个文件实现部分修改)
- 对磁盘文件编号,使页和文件形成对应关系
- get(key) 操作,查找是否有关键字key对应的数据。
- 4.1 在 hash_table 中查找,成功则结束查找;
- 4.2 hash_table 查找失败后,需要查找磁盘文件;按文件的创建日期由新到旧依次加载到hash_table 和 LRU cache中的一个page中,每次加载后,都从hash_table 中查找key,成功则结束查找
- 如果在加载某个磁盘文件后查找失败,需要将该文件对应的page从LRU cache 和 hash_table 中删除;
- 如果在加载某个磁盘文件后查找成功,需要将该文件对应的page保留在hash_table中,并放到LRU Cache前列(标记为最近访问);
- 如果已加载完所有文件,仍然查找失败,结束查找,返回查找失败
- 4.3 在多次的get操作查找成功后,LRU cache中会保存很多page,直至LRU cache中没有空闲的page,此时应该按需删除最久未被访问过的page,如果该页是dirty的,需要将page写回到文件
- put(key, value) 操作,向 server 端添加该节点的信息,若已存在相同key则覆盖
- 5.1 在hash_table中查找,如果查找成功,则覆盖节点value,设置该节点对应的页是dirty的
- 5.2 hash_table中查找失败,如get操作中在磁盘文件中查找,查找成功则保留该页在LRU 和 hash_table 中,并覆盖修改key对应的value,同时标记该页为dirty
- 5.3 磁盘文件也查找失败,需要新建一页(put_page)存储新的节点,put_page 和 其他 page 同样在LRU链表中移动。
- 只是当 put_page 未写满M个数据,且没有因为存储其他数据而被弹出cache时,新的put(key, value)仍然写入到该put_page
- 当一个 put_page 已经写满M或被弹出时,向LRU cache重新申请一个put_page用于存储
2015/07/19更新
建立key和文件之间的映射表
为了快速的定位一个key对应的文件,而不是不断的逐个遍历文件来定位,提出以下改进:
- 对于上文步骤5.3中put操作,当put_page已经写满时,将该put_page中的所有key和put_page->file_num组成(key,filenum)映射对,存储在哈希表key-file-map中;例如put_page中有2个数据,put_page分配的文件标号为2,则压入(key1, 2) (key2, 2)进key-file-map
- 对于上文中put或者get操作涉及的查找key的操作,首先在hash-table中查找,失败后则在key-file-map中查找是否有存在该key的数据文件,如果查找到,则加载key对应的文件进新的一页,然后在hash-table中得到key的节点;如果没查找到,说明不存在含有key的数据文件,服务器不存在该key。
- 服务器在启动时,应该首先把存储在文件中的key-file映射表加载到内存(key-value-map)中。
以上改进,避免了原始方法中的不断遍历文件时大量的磁盘IO操作,这将极大地提高效率。但是缺点是,维持key-file-map需要占用内存。如果value的数据量 远远大于 文件标号(int 型数据) 的数据量时,此项改进是有意义的。
改进代码,请访问:key/value服务器项目: https://github.com/qzxin/key-value-server
5. C++实现源码
基于VS2015 调试开发,支持C++11的编译器均可,
MinGw编译器存在已知bug(由于std::to_string函数):查看bug
gcc 测试成功g++ -std=c++11 main.cpp hash_cache.cpp -o hash_cache
5.1 hash_cache.h
/*
* hash_cahce.h
*
* Author: quinn
* Date : 2015/06/30
*/
#ifndef HASH_CACHE_H
#define HASH_CACHE_H
#include <vector>
#include <unordered_map>
#include <fstream>
#include <string>
//#include "node.h"
#define PAGE_SIZE 2
#define CACHE_SIZE 2
#define DISK_SIZE 20
#define FAILED -1
using namespace std;
// 类 HashCache 实现了一种基于文件页的LRU Cache的功能,Cache 空间一定,当 Cache 已经被占满时,需要删除最久未被访问过的页。
// 如果该页被修改过,则需要重新写回到文件;
//包含 put 和 get 两种操作
// put 操作:向 缓存中添加该节点的信息,若已存在相同key,则覆盖。删除页时
// get 操作:搜索
class HashCache {
private:
class Page;
class Node;
Page* entries_;
vector<Page*> free_entries_; // 存储空闲page
unordered_map<string, Node* > hash_map; // 存储节点的散列表,以供快速查询
Page* get_new_page(); // 得到新的一页,可处理没有空页的情况
Page* put_page; // 用以标记写入的page
bool put_page_existed; // 用于put_page被顶出之后的判断
const char**file_list_; // 已弃用。文件列表,后来采用直接用文件序号直接构造文件名。
int new_file_index_; // 新建文件序号,初始为 -1
Page *head_, *tail_; // 双向列表的头尾,以实现LRU Cache
void detach(Page* page); // 卸载该页
void attach(Page* page); // 将该页链接到头部
Node* search(string key); // 搜索key,成功返回 key 代表的节点,失败返回NULL
int load_file_to_page(const int &file_num, Page* &page, unordered_map<string, Node* > &hash_map); // 将第file_num个文件加载到page中,并推入hash_map的表中
int save_page_to_file(Page* &page); // 将page保存到文件
void erase_page_of_cache(Page* &page, unordered_map<string, Node* > &hash_map); // 将该页的内容从hash_map中释放
int load_new_file_index(const char* save_file_index = "file_index.dat"); // 在该文件中存储着存储文件已经使用到第几个;加载失败返回-1
void save_new_file_index(const char* save_file_index = "file_index.dat"); // 程序结束时,保存现在的文件序号到文件
public:
HashCache(int capacity = CACHE_SIZE);
~HashCache();
void save_cache(); //将cache中所有dirty(已修改)内容保存到文件(可以定期调用或者最后结束程序时调用)
string get(string key);
void put(string key, string value);
};
#endif
5.2 hash_cache.cpp
/*
* hash_cahce.cpp
*
* Author: quinn
* Date : 2015/06/30
*/
#include "hash_cache.h"
#include <iostream>
#include <algorithm>
using namespace std;
bool file_accessed[DISK_SIZE] = { false };
// 单个数据节点
class HashCache::Node {
public:
std::string key_;
std::string value_;
class Page* page_; // 该数据节点所属页
};
// 一页
class HashCache::Page {
public:
int file_num_; // 页所对应的文件序号
bool lock_;
bool dirty_; // 标记page是否被修改
class Node data_[PAGE_SIZE]; // 页包含的节点数据
class Page* next;
class Page* prev;
Page() {
lock_ = false;
dirty_ = false;
}
};
HashCache::HashCache(int capacity) {
// file_list_ = file_list;
new_file_index_ = load_new_file_index();
put_page_existed = false;
// 为cache分配内存
entries_ = new Page[capacity];
for (int i = 0; i < capacity; i++) {
for (int j = 0; j < PAGE_SIZE; j++) // 将该页的地址标记到节点中
(entries_ + i)->data_[j].page_ = entries_ + i;
free_entries_.push_back(entries_ + i); // 页入队列
}
// 构建双向链表
head_ = new Page;
tail_ = new Page;
head_->prev = NULL;
head_->next = tail_;
tail_->prev = head_;
tail_->next = NULL;
}
HashCache::~HashCache() {
// 保存cache的数据
save_cache();
//delete entries_;
delete head_;
delete tail_;
}
// 查找 key : 先在当前 hash_map 中查找,不成功则依次查找现有文件中的数据;
// 查找文件过程中,如果查找成功,则该文件中的数据保留到hash_map中,所属页链接到LRU双向链表头部;失败,则删除其对应的所有信息,恢复之前的状态
// get 操作 和 put 操作 都要调用此函数
HashCache::Node* HashCache::search(string key) {
Node* node = hash_map[key];
Page* page = NULL;
if (node) {
// search success, 将节点所属页链到头部
page = node->page_;
detach(page);
attach(page);
}
else {
// 优先遍历最新的文件
for (int file_num = new_file_index_; file_num >= 0; file_num--) {
if (file_accessed[file_num] == true)
continue; // 该文件曾经存在或正存在于hash_map 中,跳过
page = get_new_page(); // 从空间中获取一个新page
// 将当前文件加载进page,并把数据插入到hash_map
if (load_file_to_page(file_num, page, hash_map) == FAILED) {
free_entries_.push_back(page); // 加载失败,重新将该page入栈
continue;
}
if (node = hash_map[key]) {
attach(page);
break; // 已找到该节点
}
else {
// 该文件不含查找节点,释放掉该文件对应页
erase_page_of_cache(page, hash_map);
free_entries_.push_back(page);
}
}
}
return node;
}
string HashCache::get(string key) {
Node* node = search(key);
if (node)
return node->value_;
return string(); // 查找失败返回默认值
}
// put 操作:将数据写入到server;当已经存在同样的key时,覆盖 ;
// 因此,首先先查找是否存在key,存在则覆盖值,并且将页标为dirty;不存在,将数据写入到 put_page 中。
// 最后都要将操作页链到头部.
// 注:此处的put_page一直接受put操作的值,直至满页后,put_page才指向新的一页,当被弹出时,写入到磁盘
void HashCache::put(string key, string value) {
Node* node = NULL;
node = search(key);
if (node) { // 存在当前key
if (value != node->value_) {
node->value_ = value;
node->page_->dirty_ = true;
}
return;
}
else {
// server 不存在当前节点,写入put_page
static int data_index = 0;
// 上一次的 put_page 没有写满,但是被弹出了,即 put_page 不存在,新的一页新的数据索引
if (data_index == PAGE_SIZE || put_page_existed == false) {
data_index = 0;
}
if (data_index == 0 || put_page_existed == false) { //和上一语句代码冗余, put_page_existed == false 可以不存在,仅便于理解
// put_page 初始化
put_page = get_new_page();
put_page_existed = true;
put_page->file_num_ = ++new_file_index_; // put_page 对应文件序号
put_page->dirty_ = true;
for (int i = 0; i < PAGE_SIZE; i++) {
put_page->data_[i].key_ = "";
put_page->data_[i].value_ = "";
}
attach(put_page);
}
put_page->data_[data_index].key_ = key;
put_page->data_[data_index].value_ = value;
hash_map[key] = put_page->data_ + data_index; // 加入到散列表
data_index++;
detach(put_page);
attach(put_page);
}
}
// 将第file_num个文件加载到page中,并推入hash_map的表中
int HashCache::load_file_to_page(const int &file_num, Page* &page, unordered_map<string, Node* > &hash_map) {
ifstream input;
string file_name = to_string(file_num) + ".dat"; // 用文件编号构造文件名
input.open(file_name, ios::in);
if (!input || page == NULL)
return FAILED; // 不存在文件
file_accessed[file_num] = true; // 表示该文件已经存在于hash_map
page->file_num_ = file_num;
Node* data = page->data_;
for (int i = 0; i < PAGE_SIZE; i++) {
if (!(input >> data[i].key_ >> data[i].value_))
data[i].key_ = "", data[i].value_ = ""; // 输入为空
hash_map[data[i].key_] = data + i;
}
input.close();
return 0;
}
int HashCache::save_page_to_file(Page* &page) {
page->dirty_ = false;
if (page == NULL)
return FAILED;
ofstream output;
string file_name = to_string(page->file_num_) + ".dat"; // 用文件编号构造文件名
output.open(file_name, ios::out);
Node* data = page->data_;
for (int i = 0; i < PAGE_SIZE; i++) {
output << data[i].key_ << " " << data[i].value_ << endl; // 将该页中的节点保存到文件中
}
output.close();
return 0;
}
//加载文件序号,以便server重启后的文件不会产生覆盖;
//加载失败返回-1 (使用前先自增操作,因此从 0 号文件开始)
int HashCache::load_new_file_index(const char* save_file_index) {
ifstream input;
input.open(save_file_index, ios::in);
if (!input) {
return -1; // 不存在该文件,返回初始序号 -1
}
int index;
input >> index;
input.close();
return index;
}
void HashCache::save_new_file_index(const char* save_file_index) {
ofstream output;
output.open(save_file_index, ios::out);
if (!(output << new_file_index_)) {
cout << "保存存储文件序号文件失败:write <" << save_file_index << "> failed." << endl;
exit(-1);
}
output.close();
}
void HashCache::erase_page_of_cache(Page* &page, unordered_map<string, Node* > &hash_map) {
file_accessed[page->file_num_] = false; // 表示该文件已经不再hash_map中
for (int i = 0; i < PAGE_SIZE; i++) {
hash_map.erase(page->data_[i].key_);
}
}
void HashCache::save_cache() {
// 保存搜索用hash_map
Page* page = head_->next;
while (page != tail_) {
if (page->dirty_ == true) {
save_page_to_file(page);
}
page = page->next;
}
save_new_file_index();
}
void HashCache::detach(Page* page) {
page->prev->next = page->next;
page->next->prev = page->prev;
}
void HashCache::attach(Page* page) {
page->prev = head_;
page->next = head_->next;
head_->next->prev = page;
head_->next = page;
}
// 从cache中分配新的一页:cache有空闲和cache已满
// cache有空闲:从空闲列表中取出一页,返回
// cache已满:需要释放一页才能给出一页空间;
// 选择释放最后的一页,并且当该页是dirty的,则写入page到文件;当该页是一个未满的put_page,标记为cache中已不存在put_page
// <注> 释放包括:从链表中取出 和 从 hash_map 表中删除该页包含的所有节点信息
HashCache::Page* HashCache::get_new_page() {
Page* page;
if (free_entries_.empty() == true) {
// cache 已满,从尾部取下一个page
page = tail_->prev;
if (page == put_page) // put_page 被顶出
put_page_existed = false;
if (page->dirty_ == true)
save_page_to_file(page); // 保存该页,并从hash_map中删除该页
erase_page_of_cache(page, hash_map);
detach(page);
free_entries_.push_back(page); //之所以入栈又出栈,是为了应对读取失败的情况
}
page = free_entries_.back();
free_entries_.pop_back();
return page;
}
6. 工程文件下载
LRU Cache & Disk Write-Back: http://download.csdn.net/detail/quzhongxin/8857439
key/value服务器项目: https://github.com/qzxin/key-value-server















 2951
2951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









