







 本文深入剖析WordCount的MapReduce实现,包括Map过程、Reduce过程、Input输入和Output输出,以及Mapper和Reducer抽象类的使用。Map任务并行读取文件,将单词转化为<key, value>对,Reduce则负责对Map结果进行排序和合并,得到最终词频。通过设置不同的输出数据类型,调整Job配置,完成词频统计作业。"
51010902,5097065,Ubuntu重置MySQL数据库密码,"['数据库管理', 'MySQL', 'Ubuntu系统']
本文深入剖析WordCount的MapReduce实现,包括Map过程、Reduce过程、Input输入和Output输出,以及Mapper和Reducer抽象类的使用。Map任务并行读取文件,将单词转化为<key, value>对,Reduce则负责对Map结果进行排序和合并,得到最终词频。通过设置不同的输出数据类型,调整Job配置,完成词频统计作业。"
51010902,5097065,Ubuntu重置MySQL数据库密码,"['数据库管理', 'MySQL', 'Ubuntu系统']
为了把抽象问题转化成为具体问题,深入理解MapReduce的工作原理,因此,以WordCount为例,详细分析MapReduce是怎么来执行的,中间的执行经过了哪些步骤,每个步骤产生的结果是什么。简单来说,大体上工作流程是Input从HDFS里面并行读取文本中的内容,经过MapReduce模型,最终把分析出来的结果用Output封装,持久化到HDFS中。
一、WordCount的Map过程
1、使用三个Map任务并行读取三行文件中的内容,对读取的单词进行map操作,每个单词都以<key, value>形式生成,如下所示:
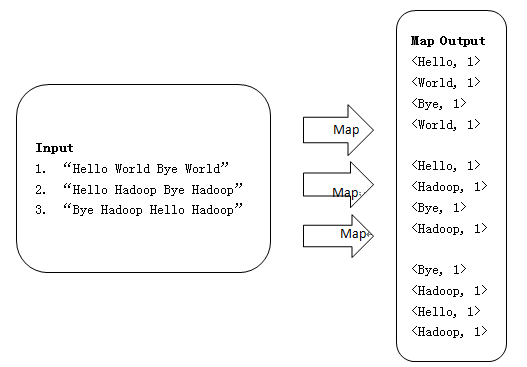
2、Map端源码,如下所示:
public class WordMapper extends
Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken().toLowerCase());
context.write(word, one);
}
}
}
二、WordCount的Reduce过程
1、Reduce操作是对Map的结果进行排序、合并等操作最后得出词频,如下所示:
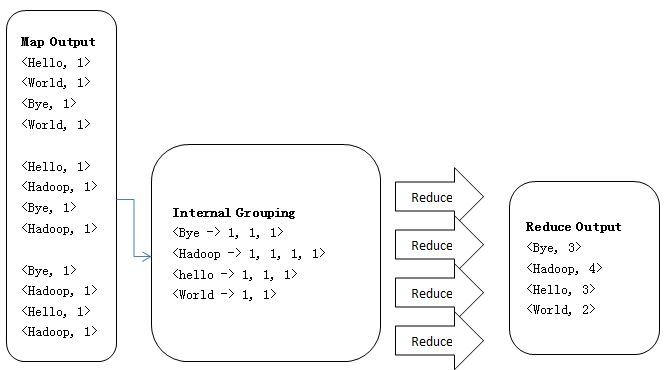
2、Reduce端源码,如下所示:
public class WordReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, new IntWritable(sum));
}
}
1、Input输入
Hello World Bye World
Hello Hadoop Bye Hadoop
Bye Hadoop Hello Hadoop2、Map结果
<Hello, 1>
<World, 1>
<Bye, 1>
<World, 1>
<Hello, 1>
<Hadoop, 1>
<Bye, 1>
<Hadoop, 1>
<Bye, 1>
<Hadoop, 1>
<Hello, 1>
<Hadoop, 1><Bye, 1>
<Bye, 1>
<Bye, 1>
<Hadoop, 1>
<Hadoop, 1>
<Hadoop, 1>
<Hadoop, 1>
<Hello, 1>
<Hello, 1>
<Hello, 1>
<World, 1>
<World, 1>4、Combine结果
<Bye, 1, 1, 1>
<Hadoop, 1, 1, 1, 1>
<Hello, 1, 1, 1>
<World, 1, 1><Bye, 3>
<Hadoop, 4>
<Hello, 3>
<World, 2>补充:MergeSort(归并排序)的过程,如下所示:
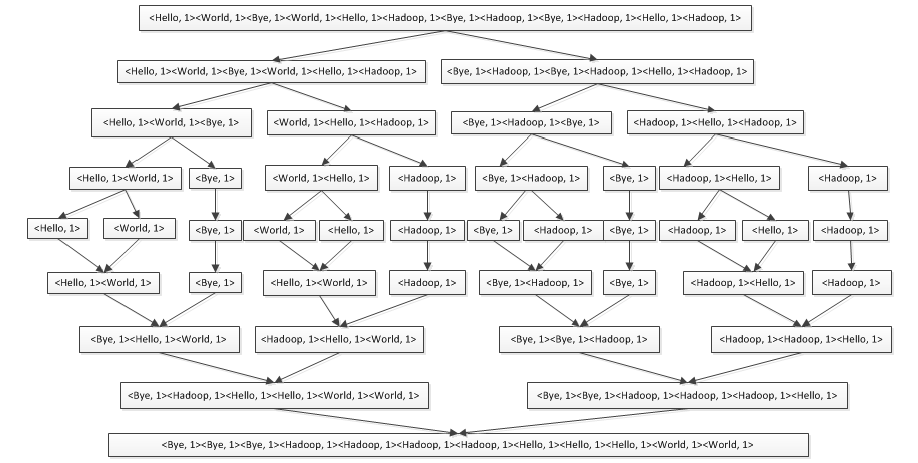
(1)用"|"分隔符对Map的结果进行第一次二分
<Hello, 1><World, 1><Bye, 1><World, 1><Hello, 1><Hadoop, 1> | <Bye, 1><Hadoop, 1><Bye, 1><Hadoop, 1><Hello, 1><Hadoop, 1>
<Hello, 1><World, 1><Bye, 1> || <World, 1><Hello, 1><Hadoop, 1> | <Bye, 1><Hadoop, 1><Bye, 1> || <Hadoop, 1><Hello, 1><Hadoop, 1><Hello, 1><World, 1> ||| <Bye, 1> || <World, 1><Hello, 1> ||| <Hadoop, 1> | <Bye, 1><Hadoop, 1> ||| <Bye, 1> || <Hadoop, 1><Hello, 1> ||| <Hadoop, 1><Hello, 1><World, 1> ||| <Bye, 1> || <World, 1><Hello, 1> ||| <Hadoop, 1> | <Bye, 1><Hadoop, 1> ||| <Bye, 1> || <Hadoop, 1><Hello, 1> ||| <Hadoop, 1><Bye, 1><Hello, 1><World, 1> ||<Hadoop, 1><Hello, 1><World, 1> | <Bye, 1><Bye, 1><Hadoop, 1> || <Hadoop, 1><Hadoop, 1><Hello, 1><Bye, 1><Hadoop, 1><Hello, 1><Hello, 1><World, 1><World, 1> | <Bye, 1><Bye, 1><Hadoop, 1><Hadoop, 1><Hadoop, 1><Hello, 1><Bye, 1><Bye, 1><Bye, 1><Hadoop, 1><Hadoop, 1><Hadoop, 1><Hadoop, 1><Hello, 1><Hello, 1><Hello, 1><World, 1><World, 1>说明:
以上归并排序个别步骤省略,并不是完整的,详见上图。
四、Mapper抽象类
我们写的Map类是继承Mapper<Object, Text, Text, IntWritable>抽象类,方法源码如下所示:
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
public class Context extends MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
public Context(Configuration conf, TaskAttemptID taskid,
RecordReader<KEYIN, VALUEID> reader,
RecordWriter<KEYOUT, VALUEOUT> writer,
OutputCommitter committer,
StatusReporter reporter,
InputSplit split) throws IOException, InterruptedException {
super(conf, taskid, reader, writer, committer, reporter, split);
}
}
/**
* Called once at the beginning of the task.
*/
protected void setup(Context context) throws IOException, InterruptedException {
// NOTHING
}
/**
* Called once for each key/value pair in the input split. Most applications should
* override this, but the default is the identity function.
*/
@SuppressWarning("unchecked")
protected void map(KEYIN key, VALUEIN value, Context context) throws IOException, InterruptedException {
context.write((KEYOUT)key, (VALUEOUT)value);
}
/**
* Called once at the end of the task.
*/
protected void cleanup(Context context) throws IOException, InterruptedException {
// NOTHING
}
/**
* Expert users can override this method for more complete control over the
* execution of the Mapper.
*
* @param context
* @throws IOException
*/
public void run(Context context) throws IOException, InterruptedException {
setup(context);
while(context.nextKeyValue()) {
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
cleanup(context);
}
}
- MapReduce编程的时候,都要继承Mapper这个抽象类,通常重写map()。map()每次接受一个Key-Value对,然后对这个Key-Value对进行处理,再分发出处理后的数据。
- 重写setup()主要对这个Map Task进行一些预处理。
- 重写cleanup()主要做一些处理后的工作。
- run()相当于Map Task的驱动,它提供了setup()—>map()—>cleanup()的执行模板。
- Mapper<Object, Text, Text, IntWritable>抽象类前两个参数为map()的输入,后两个参数为map()的输出。map()方法中,Object key参数表示偏移量,Value value表示一行文本的值,Context context参数为MapReduce模型Map端的上下文对象。
说明:
举个例子来说,如果输入文件test.txt的内容,如下所示:
hello world
easy hadoop
五、Reducer抽象类
我们写的Reducer类是继承Reducer<Text, IntWritable, Text, IntWritable>抽象类的,方法源码如下所示:
public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
public class Context extends ReduceContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {
public Context(Configuration conf, TaskAttemptID, taskid,
RawKeyValueInterator input,
Counter inputKeyConuter,
Counter inputValueCounter,
RecordWriter<KEYOUT, VALUEOUT> output,
OutputCommitter committer,
StatusReporter reported,
RawComparator<KEYIN> comparator,
Class<KEYIN> keyClass,
Class<VALUEIN> valueClass
) throws IOException, InterruptedException {
super(conf, taskid, input, inputKeyCounter, inputValueCounter,
output, committer, reporter, comparator, keyClass, valueClass);
}
}
/**
* Called once at the start of the task.
*/
protected void setup(Context context) throws IOException, InterruptedException {
// NOTHING
}
/**
* This method is called once for each key. Most application will define
* their reduce class by overriding this method. The default implementation
* is an indentity function.
*/
@SuppressWarning("unchecked")
protected void reduce(KEYIN key, Interable<VALUEIN> values, Context context)
throws IOException, InterruptedException {
for(VALUEIN value: values) {
context.write((KEYOUT)key, (VALUEOUT)value);
}
}
/**
* Called once at the end of the task.
*/
protected void cleanup(Context context) throws IOException, InterruptedException {
// NOTHING
}
public void run(Context context) throws IOException, InterruptedException {
setup(context);
while(context.nextkey()) {
reduce(context.getCurrentKey(), context.getValues(), context);
}
cleanup(context);
}
}
- Reducer<Text, IntWritable, Text, IntWritable>抽象类里面的方法和Mapper<Object, Text, Text, IntWritable>有点类似,除了reduce()不一样,其它的都一样,并且功能也一样。
- Reducer<Text, IntWritable, Text, IntWritable>抽象类前两个参数为Reduce的输入(即Map的输出),后两个参数为Reduce的输出。reduce()方法中,Text key参数表示Map端输出Key的值。Iterable<IntWritable> values参数表示Key相同的值,Value的集合。Context context参数表示MapReduce的Reduce端上下文。
- Reduce功能:获取map函数的中间结果;将中间结果中的Value按Key划分组,而组按照Key排序。形成了<key, (collection of values)>的结构,此时Key是唯一的;处理组中的所有Value,相同Key的Value相加,最终Key对应的Value唯一,<key, value>序对形成。
说明:
举个例子来说,如果Map端输出的结果,如下所示:
<hello, 1>
<hello, 1>
<hello, 1>
<hello, 1>
六、MapReduce驱动
现在有Mapper了,也有Reducer了,需要一个MapReduce驱动,即一个叫做Driver的组件,也就相当于Java中的main(),它会初始化Job和指示Hadoop平台在输入文件集合上执行你的代码,并且控制输出文件的存放地址,方法源码如下所示:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordMain {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordMain.class); // main class
job.setMapperClass(WordMapper.class); // mapper
job.setCombinerClass(WordReducer.class); // combiner
job.setReducerClass(WordReducer.class); // reducer
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); // file input
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));// file output
System.exit(job.waitForCompletion(true) ? 0 : 1); // wait for completion
}
}
- main()的作用是在给定输入文件夹(InputPath参数)里的文件上执行词频统计程序的作业(Job)。Reduce的输出被写到OutputPath指定的文件夹内,用于运行Job的配置信息保存在Job对象里。通过setMapperClass()和setReducerClass()方法可以设定map和reduce函数。
- Reduce生成的数据类型由setOutputKeyClass()和setOutputValueClass()方法设定。默认情况下,假定这些也是Map的输出数据类型。如果想要设定不同的数据格式的话,可以通过Job的setMapOutputKeyClass()和setMapOutputValueClass()方法设定。
- 通过调用Job.runJob(conf)即可向MapReduce提交Job,这个调用会阻塞直到Job完成。如果Job失败了,它会抛出一个IOException。
七、WordCount源码
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class WordMapper extends
Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken().toLowerCase());
context.write(word, one);
}
}
}
public static class WordReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args)
.getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordMapper.class);
job.setCombinerClass(WordReducer.class);
job.setReducerClass(WordReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
















 2141
2141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









