







一、MapReduce模型框架
MapReduce是一个用于大规模数据处理的分布式计算模型,最初由Google工程师设计并实现的,Google已经将完整的MapReduce论文公开发布了。其中的定义是,MapReduce是一个编程模型,是一个用于处理和生成大规模数据集的相关的实现。用户定义一个map函数来处理一个Key-Value对以生成一批中间的Key-Value对,再定义一个reduce函数将所有这些中间的有相同Key的Value合并起来。很多现实世界中的任务都可用这个模型来表达。
1、MapReduce模型
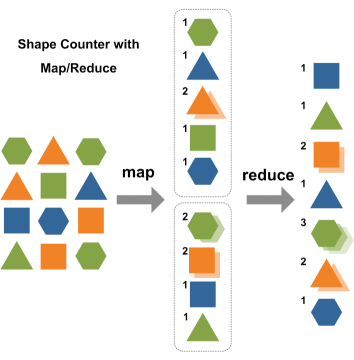
源数据 中间数据 结果数据
MapReduce模型如上图所示,Hadoop MapReduce模型主要有Mapper和Reducer两个抽象类。Mapper端主要负责对数据的分析处理,最终转化为Key-Value的数据结构;Reducer端主要是获取Mapper出来的结果,对结果进行统计。
2、MapReduce框架
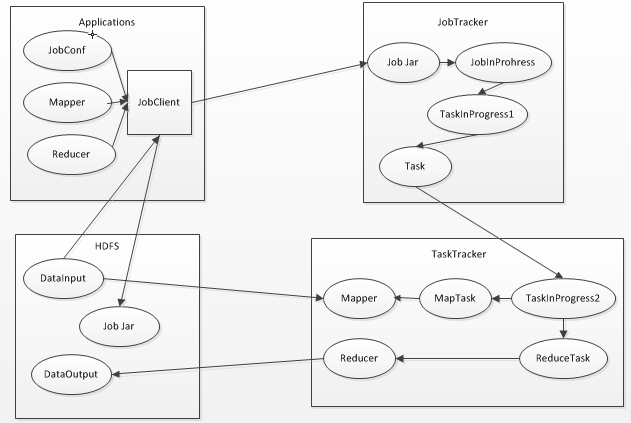
整个过程如上图所示,包含4个独立的实体,如下所示:
- client:提交MapReduce作业,比如,写的MR程序,还有CLI执行的命令等。
- jobtracker:协调作业的运行,就是一个管理者。
- tasktracker:运行作业划分后的任务,就是一个执行者。
- hdfs:用来在集群间共享存储的一种抽象的文件系统。
说明:
其实,还有namenode就是一个元数据仓库,就行windows中的注册表一样。secondarynamenode可以看成namenode的备份。datanode可以看成是用来存储作业划分后的任务。在DRCP中,master是namenode,secondarynamenode,jobtracker,其它的3台slaver都是tasktracker,datanode,且tasktracker都需要运行在HDFS的datanode上面。
MapReduce框架中组成部分及它们之间的关系,如下所示:
- Mapper和Reducer
运行在Hadoop上的MapReduce应用程序最基本的组成部分包括:一是Mapper抽象类,一是Reducer抽象类,一是创建JobConf的执行程序。
- JobTracker
JobTracker是一个master服务,软件启动之后JobTracker接收Job,负责调度Job的每一个子任务Task运行于TaskTracker上,并且监控它们的运行,如果发现有失败的Task就重新运行它,一般情况下应该把JobTracker部署在单独的机器上。
- TaskTracker
TaskTracker是运行在多个节点上的slaver服务。TaskTracker主动与JobTracker通信(与DataNode和NameNode相似,通过心跳来实现)接收作业,并负责直接执行每一个任务。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 757
757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









