







 本文探讨了数据预处理的重要性,重点关注数据清理,包括缺失值处理、噪声数据的平滑以及数据清理的过程。介绍了填充缺失值的各种策略,如忽略、人工填写、全局填充、使用统计指标填充等。对于噪声数据,提到了分箱、回归和离群点分析等方法。数据清理是一个迭代过程,涉及偏差检测和数据变换,常用工具有数据清洗、审计、迁移和ETL工具。
本文探讨了数据预处理的重要性,重点关注数据清理,包括缺失值处理、噪声数据的平滑以及数据清理的过程。介绍了填充缺失值的各种策略,如忽略、人工填写、全局填充、使用统计指标填充等。对于噪声数据,提到了分箱、回归和离群点分析等方法。数据清理是一个迭代过程,涉及偏差检测和数据变换,常用工具有数据清洗、审计、迁移和ETL工具。
1、概述
实际的数据库极易受噪声、缺失值和不一致数据的侵扰,因为数据库太大,并且多半来自多个异种数据源。低质量的数据将会导致低质量的挖掘结果。有大量的数据预处理技术:
- - 数据清理:可以用来清楚数据中的噪声,纠正不一致。
- - 数据集成:将数据由多个数据源合并成一个一致的数据存储,如数据仓库。
- - 数据归约:可以通过如聚集、删除冗余特征或聚类来降低数据的规模。
- - 数据变换:(例如,规范化)可以用来把数据压缩到较小的区间,如0.0到1.0。这可以提高设计距离度量的挖掘算法的准确率和效率。这些技术不是排斥的,可以一起使用。
1.1、数据质量 数据如果能满足其应用的要求,那么它是高质量的。数据质量涉及许多因素,包括:准确率、完整性、一致性、时效性、可信性和可解释性。
2、数据清理
现实世界的数据一般是不完整的、有噪声的和不一致的。数据清理例程试图填充缺失的值、光滑噪声并识别离群点、纠正数据中的不一致。
2.1、缺失值
如何处理缺失的属性?我们来看看下面的方法:
1- - - 忽略元组:当缺少类标号时通常这样做(假设挖掘任务设计分类)。除非元组有多个属性缺少值,否则更改方法不是很有效。当每个属性缺失值的百分比变化很大时,他的性能特别差。采用忽略元组,你不能使用该元组的剩余属性值。这些数据可能对手头的任务是有用的。
2- - - 人工填写缺失值:一般来说,该方法很费事,并且当数据集很大、缺失很多值时该方法可能行不通。
3- - - 使用一个全局填充缺失值:将缺失的属性值用同一个常量(如:“Unknow”或-∞)替换。如果确实的值都如“Unknow”替换,则挖掘程序可能误认为他们形成了一个有趣的概念,因为他们都具有相同的值 – “Unknow”。因此,尽管该方法简单,但是并不十分可靠。
4- - - 使用属性的中心度量(如均值或中位数)填充缺失值:对于正常的(对称的)数据分布而言,可以使用均值,而倾斜数据分布应该使用中位数。
5- - - 使用与给定元组属同一类的所有样本的属性均值或中位数:
6- - - 使用最可靠的值填充缺失值:可以用回归、贝叶斯形式化方法的基于推理的工具或决策树归纳确定。
方法3~方法6使数据有偏,可能填入的数据不准确。然而,方法6是最流行的策略。与其他方法(可能方法2除外)相比,它使用已有数据的大部分信息来预测缺失值。
需要注意的是,在某些情况下,缺失值并不意味着数据有错误。理想情况下,每个属性都应当有一个或多个空值条件的规则。这些规则可以说明是否允许空值,并且/或者说明这样的空值应该如何处理或转换。如果在业务处理的稍后步骤提供值,字段也可能故意留下空白。因此,尽管在得到数据后,我们可以尽我们所能来清理数据,但好的数据库和数据输入设计将有助于在第一现场把缺失值或者错误的数量降至最低。
2.2、噪声数据
噪声(noise)是被测量的变量的随机误差或方差。我们可以使用基本的数据统计描述技术(例如,盒图或者散点图)和数据可视化方法来识别可能代表噪声的离群点。
1- - - 分箱(bining):分箱方法通过考察数据的“近邻”(即周围的值)来光滑有序的数据值。这些有序的值被分布到一些“捅”或箱中。由于分箱方法考察近邻的值,因此它进行局部的光滑。

如上图所示,数据首先排序并被划分到大小为3的等频的箱中。对于用箱均值光滑,箱中每一个值都被替换为箱中的均值。类似的,可以使用用箱中位数光滑或者用箱边界光滑等等。
2- - - 回归(regression):可以用一个函数拟合数据来光滑数据。这种技术称之为回归。线性回归涉及找出拟合两个属性(或变量)的“最佳”直线,使得一个属性可以用来预测另一个。多元线性回归是线性回归的扩充,其中涉及的属性多余两个,并且数据拟合到一个多维曲面。
3- - - 离群点分析(outlier analysis):可以通过如聚类来检测离群点。聚类将类似的值组织成群或“簇”。直观地,落在簇集合之外的值被视为离群点。
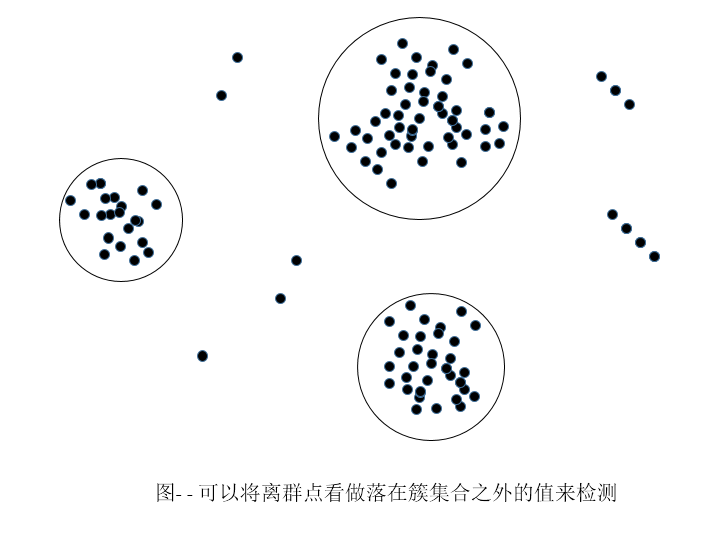
2.3、数据清理作为一个过程
数据清理过程第一步是偏差检测(discrepancy detection)。导致偏差的因素可能有多种,包括具有很多可选字段的设计糟糕的输入表单、人为的输入错误、有意的错误(例如,不愿意泄露个人隐私),以及数据退化(例如,过时的地址)。偏差也可能源于不一致的数据表示和编码的不一致使用。记录数据的设备的错误和系统错误是另一种偏差源。当数据(不适当地)用于不同于当初的目的时,也可能出现错误。数据集成也可能导致不一致(例如,当给定的属性在不同的数据库中具有不同的名称时)。
那么,如何进行偏差检测呢?首先,我们明确一个概念,”关于数据的数据“称作元数据。例如,每个属性的数据类型是定义域是什么?每个属性可接受的值是什么?对于把握数据趋势和识别异常,数据的基本统计描述是有用的。例如,找出均值、中位数和众数。数据是对称的还是倾斜的?值域是什么?所有的值都在期望的区间内吗?每个属性的标准差是多少?远离给定属性均值超过两个标准差的值可能标记为可能的离群点。属性之间存在已知的依赖吗?在这一步,可以编写程序或使用稍后我们讨论到的工具。由此,你可能发现噪声、离群点和需要考察的不寻常的值。
1- - - 编码格式:警惕编码使用的不一致和数据表示的不一致问题(例如,日期“2015/12/08”和”08/12/2015”);
2- - - 字段过载:开发者将新属性的定义挤进已经定义的属性的未使用(位)部分(例如,使用一个属性未使用的位,该属性取值已经使用了32位中的31位)。
1- - - :唯一性规则:给定属性的每个值都必须不同于该属性的其他值。
2- - - :连续性规则:属性的最低值和最高值之间没有缺失的值,并且所有的值还必须是唯一的(例如,检验数).
3- - - :空值规则:说明空白、问号、特殊符号或指示空值条件的其他串的使用(例如,一个给定属性的值何处不能用),以及如何处理这样的值。
1- - - 数据清洗工具(data scrubbing tools):使用简单的领域知识(邮政地址知识和拼写检查),检查并纠正数据中的错误。在清理多个数据源的数据时,这些工具依赖分析和模糊匹配技术。
2- - - 数据审计工具(data auditing tools):通过分析数据发现规则和联系,并检测违反这些条件的数据来发现偏差。
3- - - 数据迁移工具(data migration tools):允许说明简单的变换,如将串”gender”用“sex”替换。
4- - -ETL(extraction/transformation/loading,提取/变换/装入)工具:允许用户通过图形用户界面说明变换。
通常,这些工具只支持有限的变换,因此我们可能需要为数据清理过程的这一步编写定制的程序。
偏差检测和数据变换(纠正偏差) 迭代执行这两步过程。通常,需要多次迭代才能使用户满意。
新的数据清理方法强调加强交互性。例如,Potter’s Wheel是一种公开的数据清理工具,它集成了偏差检测和数据变换。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









