







一、概述
贝叶斯网络是用来表示变量间连接概率的图形模式,它提供了一种自然的表示因果信息的方法,用来发现数据间的潜在关系。在这个网络中,用节点表示变量,有向边表示变量的依赖关系。
贝叶斯方法以其独特的不确定性知识表达形式、丰富的概率表达能力、综合先验知识的增量学习特性等成为当前数据挖掘众多方法中最为引人注目的焦点之一。
1.1贝叶斯网络的发展历史
1.2贝叶斯方法的基本观点
贝叶斯方法的特点是用概率去表示所有形式的不确定性,学习或其它形式的推理都用概率规则来实现。
贝叶斯学习的结果表示为随机变量的概率分布,它可以解释为我们对不同可能性的信任程度。
贝叶斯学派的起点是贝叶斯的两项工作:贝叶斯定理和贝叶斯假设。
贝叶斯定理将事件的先验概率与后验概率联系起来。
补充知识:
(1)先验概率:先验概率是指根据历史的资料或主观判断所确定的各事件发生的概率。该类概率没能经过试验证实,属于检验前的概率,所以称之为先验概率。先验概率一般分为两类,一是客观先验概率,是指利用过去的历史资料计算得到的概率;二是主观先验概率,是指在无历史资料或历史资料不全的时候,只能凭借人们的主观经验来判断取得的概率。
(2)后验概率:后验概率一般是指利用贝叶斯公式,结合调查等方式获取了新的附加信息,对先验概率进行修正得到的更符合实际的概率。
(3)联合概率:联合概率也叫乘法公式,是指两个任意事件的乘积的概率,或称之为交事件的概率。
假定随机向量
x,θ
的联合分布密度是
p(x,θ)
,他们的边际密度分别是
p(x)
、
P(θ)
。一般情况下设
x
是观测向量,
,其中 π(θ) 是 θ 的先验分布。
贝叶斯方法对未知参数向量估计的一般方法为:
(1)将未知参数看成随机向量,这是贝叶斯方法与传统的参数估计方法的最大区别。
(2)根据以往对参数
θ
的知识,确定先验分布
π(θ)
,它是贝叶斯方法容易引起争议的一步,因此而受到经典统计界的攻击。
(3)计算后验分布密度,做出对未知参数的推断。
在第(2)步,如果没有任何以往的知识来帮助确定
π(θ)
,贝叶斯提出可以采用均匀分布作为其分布,即参数在它的变化范围内,取到各个值得机会是相同的,称这个假定为贝叶斯假设。
1.3贝叶斯网络的应用领域
辅助智能决策:
数据融合:
模式识别:
医疗诊断:
文本理解:
数据挖掘:1、贝叶斯方法用于分类及回归分析;2、用于因果推理和不确定知识表达;3、用于聚类模式发现。
二、贝叶斯概率论基础
2.1、概率论基础
2.2、贝叶斯概率
(1)先验概率:
(2)后验概率:
(3)联合概率:
(4)全概率公式:设
B1,B2,⋅⋅⋅,Bn
是两两互斥的事件,且
P(Bi)>0,i=1,2,⋅⋅⋅,n,B1+B2+⋅⋅⋅+Bn=Ω
则
A=AB1+AB2+⋅⋅⋅+ABn
, 即
P(A)=∑ni=1P(Bi)P(A|Bi)
。由此可以将全概率公司看成为“由原因推导结果”,每个原因对结果的发生有一定的“作用”,即结果发生的可能性与各种原因的“作用”大小有关。全概率公式表达了它们之间的关系。
(5)贝叶斯公式:贝叶斯公式也叫后验概率公式,亦称逆概率公式,其用途很广。设先验概率为
P(Bi)
,调查所获的新附加信息为
P(Aj|Bi),(i=1,2,⋅⋅⋅,n;j=1,2,⋅⋅⋅,m)
, 则贝叶斯公式计算的后验概率为(公式貌似不是这样,待考证,请知道的告诉我为什么):
- 任何完整的概率模型必须具有表示(直接或间接)该领域变量联合分布的能力。完全的枚举需要指数级的规模(相对于领域变量个数)。
- 贝叶斯网络提供了这种联合概率分布的紧凑表示:分解联合分布为几个局部分布的乘积:
P(x1,x2,⋅⋅⋅,xn)=∏iP(xi|π)
- 从公式可以看出,需要的参数个数随网络中节点个数呈线性增长,而联合分布的计算呈指数增长
- 网络中变量间独立性的指定是实现紧凑表示的关键。这种独立性关系在通过人类专家构造贝叶斯网络中特别有效。
三、简单贝叶斯学习模型
简单贝叶斯学习模型将训练实例
I
分解成特征向量
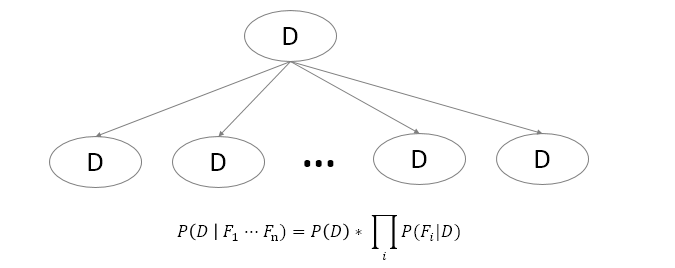
- 结构简单–只有两层结构
- 推理复杂性与网络节点个数呈线性关系
设样本A表示成属性向量,如果属性对于给定的类别独立,那么














 132
132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









