







本文来自: http://blog.csdn.net/justdb/article/details/23033291
问题描述
生产库中一张表的数据10亿级别,另一张表数据100亿级别,还有其他表的数据也是相当地庞大。入职之前不知道这些表有那么大的数据量,于是习惯了使用count(*)来统计表的记录数。但这一执行就不得了,跑了30多分钟都没出结果,最后只有取消查询。后来采取了另一种办法查询记录数。首先说明下解决的办法,使用如下SQL:
[sql] view plain copy
- SELECT object_name(id) as TableName,indid,rows,rowcnt
- FROM sys.sysindexes WHERE id = object_id('TableName')
- and indid in (0,1);
问题模拟
接着我做了一个模拟,并且试着从原理的角度分析下使用count(*)和查询sysindexes视图为什么会出现那么大的差距。
我们做模拟之前首先要得测试数据。所以我创建一个了测试表,并且插入测试数据。这里插入1亿条数据。
创建测试表的语句如下:
[sql] view plain copy
- DROP TABLE count_Test;
- CREATE TABLE count_Test
- (
- id bigint,
- name VARCHAR(20),
- phoneNo VARCHAR(11)
- );
由于插入大量数据,我们肯定不能手动来。于是我写了一个存储过程,插入1亿条数据。为了模拟出数据的复杂性,数据我采用随机字符串的形式。插入测试数据的存储过程如下:
[sql] view plain copy
- CREATE PROCEDURE pro_Count_Test
- AS
- BEGIN
- SET STATISTICS IO ON;
- SET STATISTICS TIME ON;
- SET NOCOUNT ON;
- WITH Seq(id,name,phoneNo) AS
- (
- SELECT 1,cast('13'+right('000000000' +cast(cast(rand(checksum(newid()))*100000000 AS int)
- AS varchar),9) AS VARCHAR(20)),
- cast('name_'+right('000000000' +cast(cast(rand(checksum(newid()))*100000000 AS int)
- AS varchar),9) AS VARCHAR(40))
- UNION ALL
- SELECT id+1,cast('13'+right('000000000'+ cast(cast(rand(checksum(newid()))*100000000 AS int)
- AS varchar),9) AS VARCHAR(20)),
- cast('name_'+right('000000000' +cast(cast(rand(checksum(newid()))*100000000 AS int)
- AS varchar),9) AS VARCHAR(40))
- FROM Seq
- WHERE id <= 100000000
- )
- INSERT INTO count_Test(id,name,phoneNo)
- SELECT id,name,phoneNo
- FROM Seq
- OPTION (MAXRECURSION 0)
- SET STATISTICS IO OFF ;
- SET STATISTICS TIME OFF;
- END
接着我们执行此存储过程,插入测试数据。SQL Server Management Studio在输出窗口的右下角记录了操作的时间。为了更直观,我们手动写了个记录时间的语句,如下:
[sql] view plain copy
- DECLARE @d datetime
- SET @d=getdate()
- print '开始执行存储过程...'
- EXEC pro_Count_Test;
- SELECT [存储过程执行花费时间(毫秒)]=datediff(ms,@d,getdate())
好了,等待47分29秒,数据插入完毕,插入数据的统计信息如图一,占用数据空间如图二,我们开始测试count(*)和sysindexes在效率上的差别。
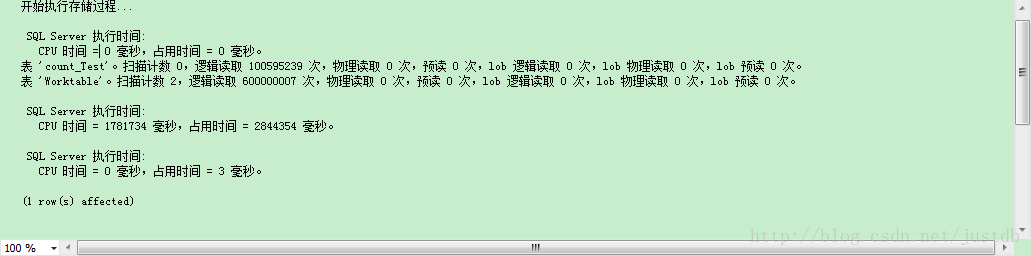
图一 插入1亿行数据统计信息

图二 插入1亿行数据占用空间
在没有任何索引的情况下使用count(*)测试,语句如下:
[sql] view plain copy
- DECLARE @d datetime
- SET @d=getdate()
- SELECT COUNT(*) FROM count_Test;
- SELECT [语句执行花费时间(毫秒)]=datediff(ms,@d,getdate())
测试时内存使用率一度飙到96%,可见效率是极低的。测试结果用时1分42秒,如图三,我们查看此时的执行计划,如图四。可以清晰地看到此时走的是全表扫描,并且绝大多数的开销都花销在这上面。

图三 无索引使用count(*)执行时间
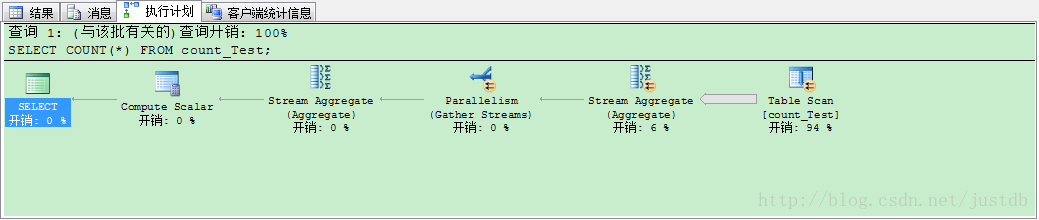
图四 无索引使用count(*)执行计划
在没有任何索引的情况下使用sysindexes测试,语句如下:
[sql] view plain copy
- DECLARE @d datetime
- SET @d=getdate()
- SELECT object_name(id) as TableName,indid,rows,rowcnt
- FROM sys.sysindexes WHERE id = object_id('count_Test')
- and indid in(0,1);
- SELECT [语句执行花费时间(毫秒)]=datediff(ms,@d,getdate())
测试结果用时450毫秒,如图五。我们查看此时的执行计划,如图六。可以看到此时走的是聚集索引扫描,并且全部的开销都在此。

图五 无索引使用使用sysindexes执行时间
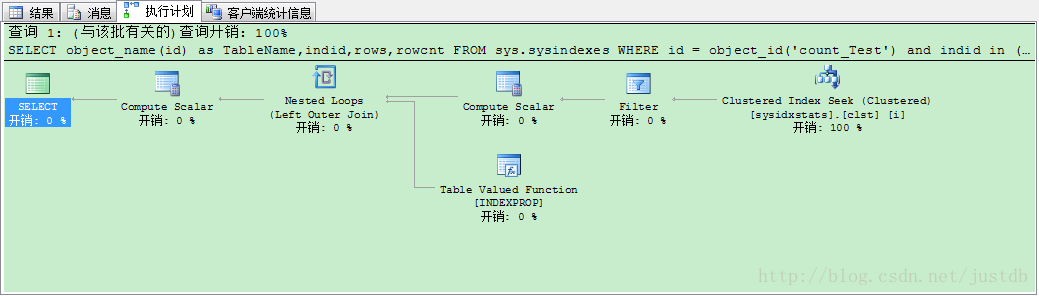
图六 无索引使用使用sysindexes执行计划
在没有索引的情况下测试完毕,我们开始测试有索引的情况。首先,我们在ID列上建立普通索引。语句如下:
[sql] view plain copy
- CREATE INDEX idx_nor_count_test_id ON count_Test(id);
建立普通索引时内存使用率、CPU利用率都相当地高,一读达到97%。创建普通索引用时34分58秒,数据文件磁盘占用空间为6.71G (7046208K),日志文件无变化。执行计划如图七:
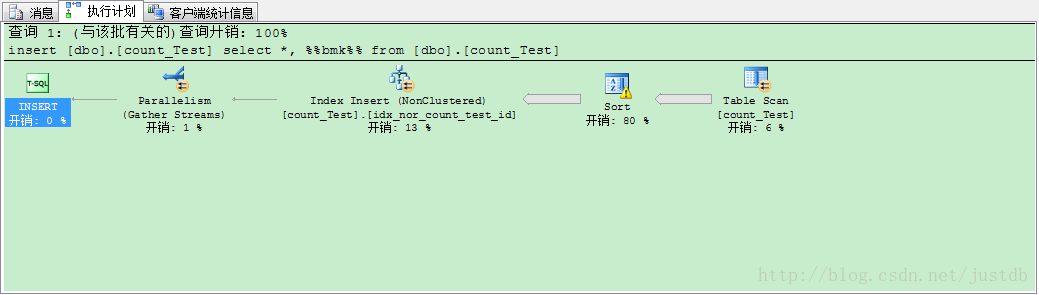
图七 创建普通索引执行计划
在有普通索引的情况下使用count(*)测试,语句和没有任何索引的情况下使用count(*)测试相同。测试结果用时1分09秒,比没有使用索引速度要快。我们查看此时的执行计划,如图八。可以看到此时走非聚集索引扫描,开销主要在此。

图八 普通索引使用count(*)执行计划
在有普通索引的情况下使用sysindexes测试,语句和没有任何索引的情况下使用sysindexes测试相同。测试结果用时290毫秒,也比没有索引时用时少。我们查看此时的执行计划,如图九,可以看到执行计划未变。
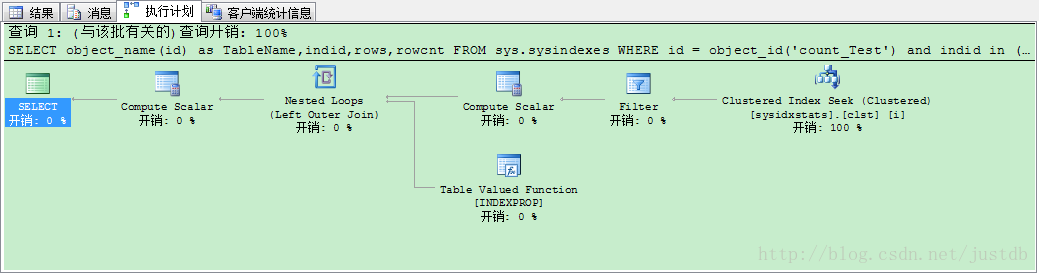
图九 普通索引使用sysindexes执行计划
普通索引测试完毕,现在我们测试聚集索引。删除普通索引,在id列上建立聚集索引,语句如下:
[sql] view plain copy
- DROP INDEX idx_nor_count_test_id ON count_Test;
- CREATE CLUSTERED INDEX idx_clu_count_test_id ON count_Test(id);
创建聚集索引用时25分53秒。数据文件占用9.38G(9839680K)。
在有聚集索引的情况下,使用count(*)测试,语句和没有任何索引的情况下使用count(*)测试相同。测试结果用时4分08秒,我们查看此时的执行计划,如图十。可以看到此时走聚集索引,开销主要花销在此。

图十 聚集索引使用count(*)测试
在有聚集索引的情况下,使用sysindexes测试。语句和没有任何索引的情况下使用sysindexes测试相同。测试结果用时790毫秒,我们查看此时的执行计划,如图十一。执行计划不变。

图十一 聚集索引使用sysindexes测试
聚集索引测试完毕,现在我们开始测试非聚集索引。删除聚集索引,建立非聚集索引,语句如下:
[sql] view plain copy
- DROP INDEX idx_clu_count_test_id ON count_Test.id;
- CREATE NONCLUSTERED INDEX idx_nonclu_count_test ON count_Test(id);
删除聚集索引用时16分37秒。创建非聚集索引用时时40分20秒,数据文件占用空间9.38G (9839680K)。
在有非聚集索引的情况下,使用count(*)测试。语句和没有任何索引的情况下使用count(*)测试相同。测试结果用时6分59秒,我们查看此时的执行计划,如图十二。此时走非聚集索引,开销主要在此。

图十二 非聚集索引使用count(*)测试
在有非聚集索引的情况下,使用sysindexes测试。语句和没有任何索引的情况下使用sysindexes测试相同。测试结果用时413毫秒,我们查看此时的执行计划,如图十三。执行计划不变。

图十三 非聚集索引使用sysindexes测试
接着我们做一个组合测试,包括有普通索引和聚集索引的情况、有普通索引和非聚集索引的情况、有普通索引、聚集索引和非聚集索引的情况。首先测试有普通索引和聚集索引的情况,我们首先删除非聚集索引,然后建立普通索引和聚集索引,语句如下:
[sql] view plain copy
- DROP INDEX idx_nonclu_count_test ON count_Test.id;
- CREATE INDEX idx_nor_count_test_id ON count_Test(id);
- CREATE CLUSTERED INDEX idx_clu_count_test_id ON count_Test(id);
删除用时1秒,空间不变。创建聚集索引和普通索引索引用时1:57:27,数据文件占用空间12.9G (13541440 )。
在有普通索引和聚集索引的情况下,使用count(*)测试。语句和没有任何索引的情况下使用count(*)测试相同。测试结果用时5分27秒,我们查看此时的执行计划,如图十四。此时走普通索引,开销主要在此。

图十四 聚集索引、普通索引使用count(*)测试
在有普通索引和聚集索引的情况下,使用sysindexes测试。语句和没有任何索引的情况下使用sysindexes测试相同。测试结果用时200毫秒,我们查看此时的执行计划,如图十五,执行计划不变。
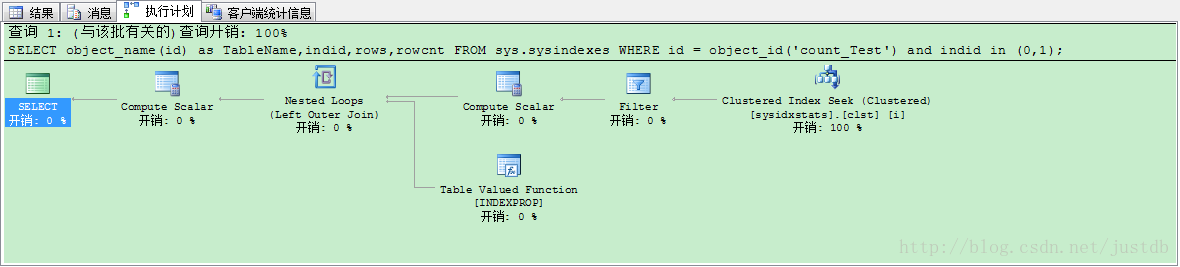
图十五 聚集索引、普通索引使用sysindexes测试
接着测试有普通索引和非聚集索引的情况,我们删除聚集索引,建立非聚集索引,语句如下:
[sql] view plain copy
- DROP INDEX idx_clu_count_test_id ON count_Test.id;
- CREATE NONCLUSTERED INDEX idx_nonclu_count_test ON count_Test(id);
删除普通索引用时1:23:10,创建非聚集索引用时6分50秒,数据文件空间占用12.9G。
在有普通索引和非聚集索引的情况下,使用count(*)测试。语句和没有任何索引的情况下使用count(*)测试相同。测试结果用时52秒,我们查看此时的执行计划,如图十六。此时走非聚集索引,开销主要在此。

图十六 非聚集索引、普通索引使用count(*)测试
在有普通索引和非聚集索引的情况下,使用sysindexes测试。语句和没有任何索引的情况下使用sysindexes测试相同。测试结果用时203毫秒,我们查看此时的执行计划,如图十七。执行计划不变。

图十七 非聚集索引、普通索引使用sysindexes测试
最后,测试有普通索引、聚集索引和非聚集索引的情况。我们创建普通索引,语句如下:
[sql] view plain copy
- CREATE NONCLUSTERED INDEX idx_nonclu_count_test ON count_Test(id);
创建普通索引用时1:11:21,数据文件占用空间16.3G(17116224KB)。
在有普通索引、聚集索引和非聚集索引的情况下,使用count(*)测试。语句和没有任何索引的情况下使用count(*)测试相同。测试结果用时2分51秒,我们查看此时的执行计划,如图十八。此时走非聚集索引,开销主要在此。

图十八 普通索引、聚集索引、非聚集索引使用count(*)测试
在有普通索引、聚集索引和非聚集索引的情况下,使用sysindexes测试。语句和没有任何索引的情况下使用sysindexes测试相同。测试结果用时203毫秒,我们查看此时的执行计划,如图十九。执行计划不变。
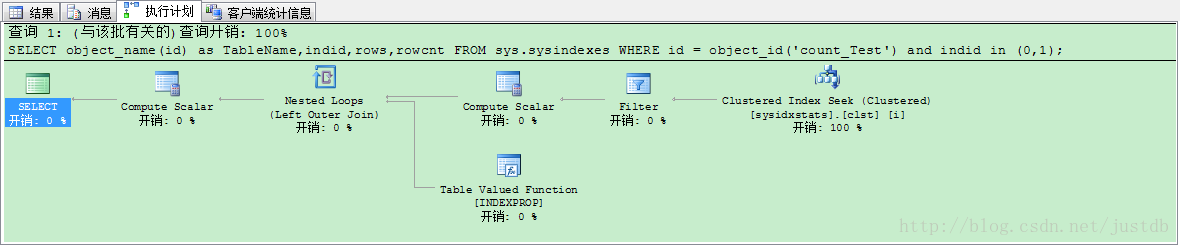
图十九 普通索引、聚集索引、非聚集索引使用sysindexes测试
加入indid大于1用时86毫秒,执行计划如图二十;加入indid等于1用时23毫秒,执行计划如图二十一。所有的测试完成后,数据文件和日志文件占用空间如图二十二。

图二十 加入indid大于1执行时间
图二十一 加入indid等于1执行时间

图二十二 所有的测试完成后,数据文件和日志文件占用空间
我们可以看出以上几种方式在效率上简直是天壤之别。count(*)不管在有什么索引的情况下都较慢,而sysindexes相对快多了。
原理分析
好了,接着我试着分析count(*)和sysindexes为什么会有那么大的差距。首先我查了下帮助文档,里面对sys.indexes 是这样介绍的:Contains one row for eachindex and table in the current database. XML indexes are not supported in thisview. Partitioned tables and indexes are not fully supported in this view; usethe sys.indexes catalog view instead.(当前数据库中的每个索引和表各对应一行。此视图不支持 XML 索引。此视图不完全支持分区表和索引;请改用 sys.indexes 目录视图)。在MS SSQL数据库中,每个数据表都在sys.sysindexes系统表中拥有至少一条记录,记录中的rows 或rowcnt字段会定时记录表的记录总数。请注意是定时,而不是实时,这说明了用这个方法得到的总记录数并不是一个精确值,原因是MS SQL并不是实时更新该字段的值,而是定时更新,但从实践来看该值和精确值误差不大,如果你希望快速粗略估算表的记录总数,建议你采用该方法。如果您希望查看实时的记录数,可以先执行DBCC UpdateUSAGE(DatabaseName,[TABLENAME])WITH ROW_COUNTS 强制更新该字段的值,再使用该SQL进行查询,这样得到的值就是实时的记录数。
在CBO的基础上,count(*)统计记录数是这样的:当对数据进行查询时,得到一条数据则对应的记录数加1,直到返回总共的记录数。在没有索引的情况下,count(*)则是Table Full Scan,也就是全表扫描,对于数据量大的表,全表扫描速度肯定慢,这一点是毋庸置疑的。如果有索引,那么会使用INDEX SCAN,速度相对较快。那如果使用count(*)统计记录数并且想使返回记录的时间变短,我们可以在表上建立聚集索引。普通索引可以在多个字段上建立,但是聚集索引一张表中只能建立一个,显然我们不能轻率地使用聚集索引。聚集索引怎么理解呢?我们可以把聚集索引想象成字典的拼音索引,这样查找单词的速度就会快很多。那问题来了,如果建立聚集索引,什么时候走索引,什么时候不走呢?如果单独的没有WHERE条件的SELECT count(*)语句想要用上索引,那么必须满足以下两个条件,第一个是CBO,第二个是存在NOT NULL属性的列。如果WHERE条件里面仅存在索引列,而不使用一些数据库内置函数或者其他连接条件,一般都会走索引。还有一个问题,为什么聚集索引快?索引是通过平衡树的结构进行描述,聚集索引的叶节点就是最终的数据节点,而非聚集索引的叶节仍然是索引节点,但它有一个指向最终数据的指针。在有聚集索引的情况下,非聚集索引的叶子节点存放的是聚集索引的键。在没有聚集索引的情况下,存放的是一个bookmark,结构是:File ID:Page ID:Row ID。所以,当一张表有聚集索引时,查询的速度会变得很快。综上,在没有索引的情况下count(*)走的是全表扫描,速度慢。
现在问题又来了,为什么使用sysindexes速度会很快?索引是为检索而存在的,就是说索引并不是一个表必须的。表索引由多个页面组成,这些页面一起组成了一个树形结构,即我们通常说的B树(平衡树),首先来看下表索引的组成部分:根极节点,root,它指向另外两个页,把一个表的记录从逻辑上分成非叶级节点Non-Leaf Level(枝),它指向了更加小的叶级节点Leaf Level(叶)。根节点、非叶级节点和叶级节点都位于索引页中,统称为索引叶节点,属于索引页的范筹。这些“枝”、“叶”最终指向数据页Page。根级节点和叶级节点之间的叶又叫数据中间页。根节点对应了sysindexes表的root字段,记载了非叶级节点的物理位置(即指针);非叶级节点位于根节点和叶节点之间,记载了指向叶级节点的指针;而叶级节点则最终指向数据页,这就是最后的B树。sysindexes中我们需要关注root字段和indid字段。我们看下官方文档中对这两个字段的解释,如图二十三:

图二十三 官方文档对root字段和indid字段的解释
从上图中我们知道,索引ID为0表示堆,也就是在没有索引下所做的全表扫描;为1是表示聚集索引,大于1表示非聚集索引。root字段在全表扫描时是不会使用到的,而只有在有索引的情况下才使用。聚集索引中,数据所在的数据页是叶级,索引数据所在的索引页是非叶级。由于记录是按聚集索引键值进行排序,即聚集索引的索引键值也就是具体的数据页。访问有聚集索引的表,步骤是这样的:首先在sysindexes表查询INDID值为1,说明表中建立了聚集索;然后从根出发,在非叶级节点中定位最接近1的值,也就是枝节点,再查到其位于叶级页面的第n页;在叶级页面第n页下搜寻值为1的条目,而这一条目就是数据记录本身;将该记录返回客户端。同样,我们查询某张表有多少记录数,我们使用到的删选条件是indid in (0,1),也就是把普通表(这里指没有聚集索引的表)和有聚集索引的表都查找到。由于sysindexes记录了每张表的记录数,无论该表是普通表还是有聚集索引的表,都可以很快地把返回结果。如上所述,这个数值并不一定准确,至于你想获得真实记录数,还是初略记录数,这就看你获得记录数的需求是什么。
综上所述,count(*)在没有索引的情况下速度慢的原因是走的全表扫描,使用sysindexes速度快的原因是直接从该视图中得到记录数。
说点题外话,在插入数据时,最开始我采用了WHILE循环插入10亿条数据,等了两个多小时还没插入完,只好停掉,改用CTE插入数据。CTE插入数据的效率很高,数据文件大小以近2M/s的速度递增,但是由于数据量太大,也只好停掉,把10亿改成1000万。插入1000万数据用时4分52秒,数据文件占用磁盘空间470M,日志文件占用磁盘空间2.3G,但做统计记录数时看不到效果,所以改成插入1亿条数据。插入1亿条数据用时47分29秒,数据文件占用磁盘空间4.54G,日志文件占用磁盘空间33.28G。从插入数据的数据量级别我们知道,每多一个数量级,插入数据的时间会成倍地增长,具体多少倍有很多因素影响,比如系统空闲率、机器CPU和IO负载、插入的数据每行占用空间是否一致等等。这里还需要搞明白一个问题,那就是为什么CTE法那么快?首先我们了解下CTE。公用表表达式(Common Table Expression)是SQL SERVER 2005版本之后引入的一个特性。CTE可以看作是一个临时的结果集,可以在接下来的一个SELECT,INSERT,UPDATE,DELETE,MERGE语句中被多次引用。使用公用表达式可以让语句更加清晰简练。本文中的插入示例使用了CTE递归查询。CTE递归查询原理是这样的:第一步,将CTE表达示拆分为“定位点成员”和“递归成员”;第二步,运行定位点成员,执行创建第一个结果集R0;第三步,运行递归成员时,将前一个结果集作为输入(Ri),将Ri+1作为输出;第四步,重复第三步,直到返回空集;第五步,返回结果集,通过UNION ALL合并R0 到 Rn的结果。熟知编程的读者清楚,递归在编程中效率也是极高的。同样,CTE采用递归后插入数据会变得相当得高,从数据文件的增长速率就可以看出,使用CTE之前数据文件增长以几K每秒的速度增长,使用CTE之后,数据文件以近2M每秒的速度增长。搞清楚CTE为什么那么快后,这里还说下清空日志文件的小技巧。我们使用DROP TABLE count_Test后,数据文件和日志文件的空间并不会真正清空,这时如果我们执行DBCC SHRINKDATABASE(db_test_wgb)(注:db_test_wgb为数据库名)后,你会发觉数据文件和日志文件从数十G一下变成几M。这和Oracle中的SHRINK TABLE有几丝类似。这里还得着重强调下,不要在生产库中执行此语句,否则会让你后悔莫及!切记!
最后说明下,本文参考了姜敏前辈的这两篇文章,软件开发人员真的了解SQL索引吗(聚集索引)和软件开发人员真的了解SQL索引吗(索引原理),还参考了宋沄剑前辈的文章:T-SQL查询进阶--详解公用表表达式(CTE)。如果想了解索引原理,强烈建议阅读姜敏前辈的这篇文章:软件开发人员真的了解SQL索引吗(索引原理)。对于什么是IAM,读者可以看下微软的官方文档,管理对象使用的空间。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









