







林轩田机器学习技法关于特征学习系列,其中涉及到
Neural Network
,
Backpropagation Algorithm
,
Deep Learning
,
Autoencoder
,
PCA
,
Radial Basis Function Network
,
K
-
- 机器学习笔记-Neural Network
- 机器学习笔记-Deep Learning
- 机器学习笔记-Radial Basis Function Network
- 机器学习笔记-Matrix Factorization
Motivation
从我们熟悉的
perceptron
说起, 在
perceptron
算法中,通过比较权重和特征的乘积与
0
的大小关系来对样本进行分类。如果我们现在将一堆的
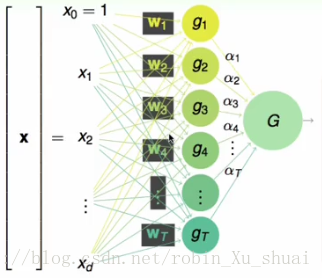
对于一个输入
X
,和第一个
通过上述的计算过程就可以得到一个样本 x 的输出
可以看到在这个模型中有
- 两组权重,第一组 w1,w2,⋯,wT 是每一个 perceptron 的权重,第二组 α1,α2,⋯,αT 用来表示每一个 g 的“票数”或者说是权重。
- 在这个模型中除了有两层权重之外,还有两层
sign 函数。也就是在每一个神经元中都有一个 sign 函数,将权重和特征的乘积映射到 {+1,−1} 然后输出。使用阶梯状来表示得到下图。
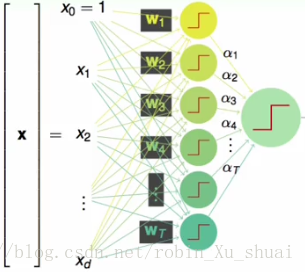
这就是一个利用
linear aggregation
将多个
perceptron
集成起来的模型,我们可以调节所有的参数
w
和
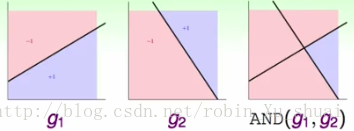
假设我们有两个
perceptron
分别是
g1
和
g2
,现在我们看看当我们使用
linear aggregation
的方式将两个感知器或者说两条线合起来也就是得到一个
aggregation of perceptron
模型的时候,这个模型可以做到一个怎么样的边界呢?可能这个模型可以做到如右图所示的逻辑操作
AND
。也就是只有当两个
g
的结果都输出
一种可能的方式是:将第二层的权重值设置为
α0=−1,α1=+1,α2=+1
,也就是两个
perceptron
g1
和
g2
的权重都是
+1
,另外假设还有一个
perceptron
g0
,它的输出是
+1
(其实是偏置
b
的角色), 它的权重是
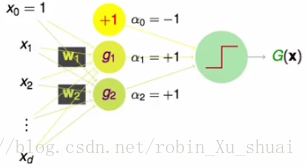
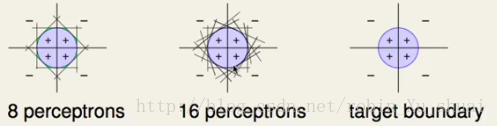
这样的模型其实是非常有能力的,例如对于下图所示的数据来说,使用任意一个单一的 perceptron 都不能将数据划分的很好,但是当使用8个不同的 perceptron 的时候可以得到一个差不多的分类边界,当使用16个不同的 perceptron 的时候就能得到一个更为平滑的分类边界。
Multi-Layer Perceptrons: Basic Neural Network
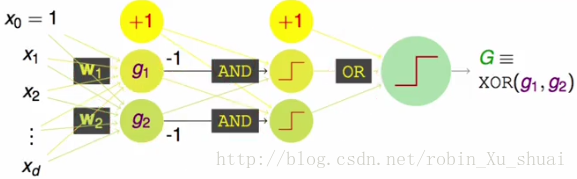
尽管这样的模型非常的 powerful ,但是仍然有些事情是做不到的, 例如同样使用上文提到的两个 perceptron g1,g2 , 想要使用上文中的模型 G(x) 做逻辑操作 XOR(g1,g2) 是不可能的。 XOR(g1,g2) 当且仅当 g1 和 g2 中只有一个为 TRUE 时,结果为 TRUE ,否则为 FALSE 。我们注意到 XOR(g1,g2)=OR(AND(−g1,g2),AND(g1,−g2)) 。即其实我们需要先经过对 g1 和 g2 的两个 AND 操作,然后再将 AND 的结果做 OR 就可以得到 XOR 。其模型的示意图如下,通过这样的模型得到的结果就和 XOR(g1,g2) 的结果是一致的。
现在从单一的
perceptron
延伸到
linear aggregation of perceptron
,然后又延伸到
Multi Layer perceptron
,这样的模型其实就是神经网络最基本的结构。需要说明的是, 虽然
Neuron Network
跟生物体中的神经网络有一定的关系,做了一定的借鉴,但是从工程学来说我们处理的是一个数学模型,不需要受到生物体的神经网络的机制的影响,就像飞机是参考鸟制造的,但却不是通过摆动机翼来飞行的。

Neural Network Hypothesis
上一小节给出了神经网络的基本长相:
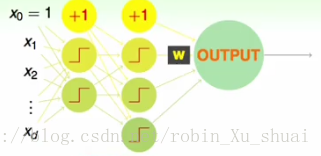
如果将每一层的计算当成是一个转化的话,那么上图中节点
OUTPUT
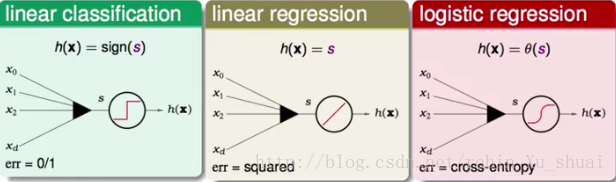
可以理解为输入是其上一层转换结果的一个线性模型:
s=wTϕ(2)(ϕ(1)(x))
。我们之前学习过的每一个线性模型都可以用在这里:如果我们想要做分类,那么就对
s
加一个
除了输出神经元部分,再来看看中间的其他神经元在做什么,通常每一个神经元会将上一层的输出(作为这个神经元的输入)和该神经元的权重的乘积
s
喂给一个函数做运算作为该神经元的输出,我们将这个函数称之为激活函数,常用的激活函数是
tanh
函数的长相如下图:

可以看到它和阶梯函数
sign
长的有点像,又比
sign
容易做最佳化,并且和我们熟悉的
logistic
函数
θ
有很大的关系。其函数的表达式为:
在以后的讲解中,每一个中间层的神经元的激活函数都默认使用 tanh 函数。
Neural Network Hypothesis
一个简单的神经网络的结构如下:
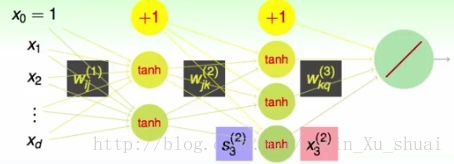
该神经网络共有
3
层,为了描述方便,我们将输入层规定为第
网络中的权重表示为
w(l)ij
。首先:
w(l)
表示第
l−1
层到第
l
层的权重,即
- 1≤l≤L ;
- 0≤i≤d(l−1) ;
- 1≤j≤d(l) 。
l−1
层中由于会多一个偏置项,所以
i
的起始值为
定义了这些权重之后,我们就可以通过这些权重来计算每一个神经元的输入
第
第
l
层第
s(l)j 和 x(l)j 的关系是: s(l)j⟶tanh(s)⟶x(l)j
通过上面的计算方法,给定一个样本
x
,我们将其作为输入层
通常我们可以神经网络中每一层的神经元的个数来描述一个神经网络的架构,例如
3
-
Neural Network Learning
现在我们已经对神经网络的基本工作方式有了直观上的了解:将输入
x
经过与第
当有多个隐藏层的时候,该如何计算其中的权重呢?在 regression 的设定下,我们希望对于某一个样本点 (xn,yn) 来说, 该模型的输出 h(xn) 和 target value yn 之间的 squared error 最小,即对于一个样本点来说, 我们想要最小化 en=(yn−h(xn))2=(yn−NNet(xn))2 。如果我们知道 en 关于每一个变量 w(l)ij 的变动是如果变化的, 那么我们就可以更新 w(l)ij 来最小化 en , 而梯度 ∂en∂w(l)ij 正好告诉了我们这件事情, 当我们知道了 en 关于每一个变量的 w(l)ij 的梯度之后, 就可以使用 gradient descent(GD) 或者 stochastic gradient descent(SGD) 来找到一步一步的更新 w(l)ij 最后找到最佳的权重。所以现在的问题只剩下如何计算 ∂en∂w(l)ij
从简单的开始算起, 首先我们计算
∂en∂w(L)i1
, 也就是
en
对于最后一层权重的偏导数。
en
和
w(L)i1
的关系如下:
根据求导的链式法则可以得到:
那么现在对于 第 L 层中的每一个权重,我们都已经可以通过上式进行计算了。
那么
其中 δ(l)j 使我们目前算不出来的, δ(l)j=∂en∂s(l)j , 表示 en 对于第 l 层第
所以现在的问题剩下如何求解 δ(l)j=∂en∂s(l)j
现在我们来分析下
s(l)j
是如何影响到
en
的,
同样使用求导的链式法则:
根据这样的推导我们发现,如果我们知道了
δ(L)
,就能计算出
δ(L−1)
,
⋯
,就能计算得到
δ(1)
, 而根据前面的计算可以知道
δ(L)=−2(yn−s(L)1)
。
另外根据
至此我们就得到了计算梯度 (2) 的方法。有了计算梯度的方法,那么我们就可以利用梯度下降类方法最小化 en 并确定最终的权重 w(l)ij 。通过上面的推导得到了一个很著名的算法: Backpropagation Algorithm
Backpropagation Algorithm
initialize all weights w(l)ij
for t=0,1,2,⋯,T
- stochastic:randomly pick n∈{1,2,⋯,N}
- forward: compute all x(l)i with x(0)=xn
- backward: compute all δ(l)j
- gradient descent: w(l)ij⟵w(l)ij−ηx(l−1)iδ(l)j
return gNNET=(⋯tanh(∑jw(2)jk⋅tanh(∑iw(1)ijxi)))
即首先初始化所有的权重
w(l)ij
,在每一轮更新中任取一个样本点
(xn,yn)
(步骤
1
)。计算梯度
考虑上面的过程我们发现,由于使用的是随机梯度下降算法, 对于仅仅一个样本点, 我们就要计算进行一次前向传播得到所有的
考虑一个问题:
根据以上的计算可以得到
∂en∂w(L)i1=−2(yn−s(L)1)⋅(x(L−1)i)
, 当什么时候
∂en∂w(L)i1=0
呢?
- yn=s(L)1
- x(L−1)i=0
- s(L−1)i=0
Optimization and Regularization
Neural network optimization
上一小节介绍了训练一个神经网络的基本方法,即通过
GD
类的算法来最小化
Ein
。需要注意的是, 由于包含了很多层的转换
tanh
,所以最终的目标函数很有可能不是
w
的凸函数,也就是说这些函数是
实际应用中我们通常使用一些技巧来得到比较好的结果, 例如,如果在初始化的时候将权重设置的过大,那么
tanh(∑wx)
的偏导就会很小,这样导致权重的更新会非常的缓慢,所以通常会初始化一些比较小的, 并且是随机的权重。 通过在不同的初始权重下进行更新,可能会得到不同的
local minimum
,这样可能会得到不错的结果。
Regularization for neural network
有理论证明在使用
tanh
作为神经网络的激活函数时, 该模型的
dvc=O(VD)
,其中
V
表示神经元的数量,
除了
weight elimination regularizer
之外, 在神经网络中还有另一个经常使用的用于
regularization
的机制:
early stopping
。简单的说,通过提前终止权重的更新,可以减少
w
的搜索范围从而做到降低模型的复杂度。提前终止这样的机制可以通用于所有使用梯度的方法中来做
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









