









网页有两种格式,一种是xml另一种是html,目前似乎好像大部分都是html格式的,查看网页格式的方法是在浏览器中右键-->查看源码
一,XML解析的三大方法
(1) SAX: Simple API for XML
SAX是一个解析速度快并且占用内存少的XML解析器。SAX解析XML文件采用的是事件驱动,也就是它并不需要解析完整个文档,
在按内容顺序解析文档的过程中,SAX会判断当前读到的字符是否符合XML语法中的某部分,如果符合则触发事件其实就是一些回调函数,
这些方法定义在ContentHandler
(2)DOM:Document Object Model
DOM解析是将XML文件全部载入,组成一颗dom树,然后通过节点以及节点之间的关系来解析XML文件。
对于特别大的文档,解析和加载整个文档可能很慢且很耗资源。
(3)pull
Pull是Android内置的xml解析器。Pull解析器的运行方式与SAX 解析器相似。它提供了类似的事件,如:开始元素和结束元素事件,使用parser.next()可以进入下一个元素并触发相应事件。事件将作为数值代码被发送,因此可以使用一个switch对感兴趣的事件进行处理。当元素开始解析时,调用parser.nextText()方法可以获取下一个Text类型节点的值。
二,HTML解析的三大方法
(1)Jsoup
(3)httpclient
HttpClient是一个很方便进行Http连接操作的工具包,用它可以设置代理和模拟浏览器下载网页。而HtmlParser则是一个开源的,可以对HTML进行处理的工具包,可以很方便的对HTML进行解析。
三,HttpClient源码讲解
本源码实现了抓取网页上的部分内容,并分栏显示出来,改进自laihuan99的博文Android抓取CSDN首页极客头条内容--网页数据抓取
MainActivity2.java
package com.example.webdatashow;
//使用HttpClient组件访问网络以及获取 网页内容的方法。
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.regex.MatchResult;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.ResponseHandler;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.BasicResponseHandler;
import org.apache.http.impl.client.DefaultHttpClient;
import android.os.Bundle;
import android.os.Handler;
import android.os.Message;
import android.app.Activity;
import android.view.View;
import android.view.View.OnClickListener;
import android.widget.Button;
import android.widget.ListView;
import android.widget.SimpleAdapter;
import android.widget.TextView;
import android.widget.Toast;
public class MainActivity2 extends Activity implements OnClickListener{
ListView listview;
private String TAG = "webdatashow";
private Button jiazai;
private TextView webDataShow;
private String pediyUrl = "http://www.stdu.edu.cn/";
Handler handler;
List<Map<String, Object>> data;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.main);
jiazai = (Button)findViewById(R.id.button1);
webDataShow = (TextView)findViewById(R.id.webDataShow1);
jiazai.setOnClickListener(this);
}
@Override
public void onClick(View view) {
handler = getHandler();
ThreadStart();
}
/*httpClientWebData()
* 返回值类型:String
* 抓取网页的document
*
* */
protected String httpClientWebData() {
String content = null;
DefaultHttpClient httpClinet = new DefaultHttpClient(); //创建一个HttpClient
HttpGet httpGet = new HttpGet(pediyUrl);//创建一个GET请求
ResponseHandler<String> responseHandler = new BasicResponseHandler();
try {
content = httpClinet.execute(httpGet, responseHandler);
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}//发送GET请求,并响应内容
return content;
}
/*getDate()
* 返回值类型:List<Map<String, Object>>
* 提取网页document的所需内容
*
* */
private List<Map<String, Object>> getDate() {
String httpstring = httpClientWebData();
List<Map<String, Object>> result = new ArrayList<Map<String, Object>>();
Pattern p = Pattern.compile("latestnewsnews | </span>\\s*<span style="white-space:pre"> </span><a href=\"(.*?)\" title=\"(.*?)\"");//正则表达式
Matcher m = p.matcher(httpstring);
while (m.find()) {
MatchResult mr=m.toMatchResult();
Map<String, Object> map = new HashMap<String, Object>();
map.put("title", mr.group(1));
map.put("url", mr.group(2));
result.add(map);
}
return result;
}
/*ThreadStart()
* 开辟新线程
*
* */
private void ThreadStart() {
new Thread() {
public void run() {
Message msg = new Message();
try {
data = getDate();
msg.what = data.size();
} catch (Exception e) {
e.printStackTrace();
msg.what = -1;
}
handler.sendMessage(msg);
}
}.start();
}
private Handler getHandler() {
return new Handler(){
public void handleMessage(Message msg) {
if (msg.what < 0) {
Toast.makeText(MainActivity2.this, "数据获取失败", Toast.LENGTH_SHORT).show();
}else {
initListview();
}
}
};
}
/*initListview()
* 在listview中显示数据
*
* */
private void initListview() {
Toast.makeText(getApplicationContext(), "doing......", Toast.LENGTH_SHORT).show();
ListView listView = (ListView) findViewById(R.id.listView1);
listView.setAdapter(new SimpleAdapter(this,data , android.R.layout.simple_list_item_2,
new String[] { "title","href" }, new int[] {
android.R.id.text1,android.R.id.text2
}));
}
}
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="fill_parent"
android:layout_height="fill_parent"
android:orientation="vertical" >
<TextView
android:id="@+id/webDataShow1"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:text="" />
<Button
android:id="@+id/button1"
android:layout_width="fill_parent"
android:layout_height="wrap_content"
android:text="加载" />
<ListView
android:id="@+id/listView1"
android:layout_width="fill_parent"
android:layout_height="wrap_content" >
</ListView>
</LinearLayout>manifest.xml
<?xml version="1.0" encoding="utf-8"?>
<manifest xmlns:android="http://schemas.android.com/apk/res/android"
package="com.example.webdatashow"
android:versionCode="1"
android:versionName="1.0" >
<uses-sdk
android:minSdkVersion="8"
android:targetSdkVersion="18" />
<uses-permission android:name="android.permission.INTERNET" />
<application
android:allowBackup="true"
android:icon="@drawable/ic_launcher"
android:label="@string/app_name"
android:theme="@style/AppTheme" >
<activity
android:name="com.example.webdatashow.MainActivity2"
android:label="@string/app_name" >
<intent-filter>
<action android:name="android.intent.action.MAIN" />
<category android:name="android.intent.category.LAUNCHER" />
</intent-filter>
</activity>
</application>
</manifest>
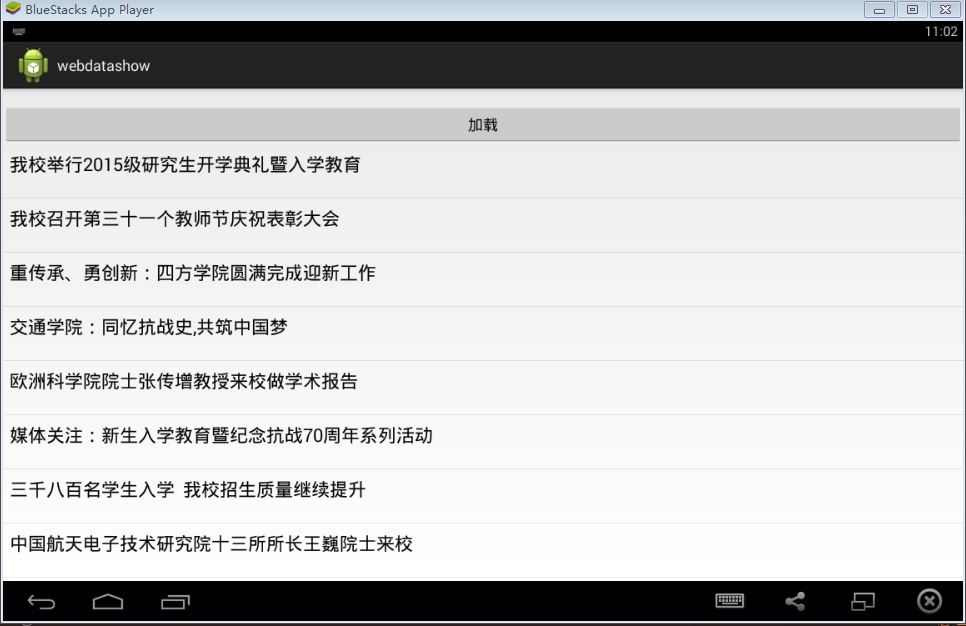
最后写一点关于正则表达式的写法:
需要下载一个工具:RegexTester.exe下载
比如提取这一段源码中的新闻标题
</div>
<div class="contentarea">
<div id="news">
<div id="news_1">
<div class="moduletablenews">
<h3>学校新闻</h3>
<div class="newnotice"><div>今日共<a href="http://xcb.stdu.edu.cn/2009-05-05-02-26-33.html"><font color="red">0</font></a>信息更新</div></div><ul class="feednews-ul">
<li class="latestnewsnews">
<span id="date">09-10 | </span>
<a href="http://xcb.stdu.edu.cn/2009-05-05-02-26-33/21883-2015-09-10-03-51-32.html" title="我校召开第三十一个教师节庆祝表彰大会" target="_blank">
我校召开第三十一个教师节庆祝表彰大会
</a></li>
<li class="latestnewsnews">
<span id="date">09-09 | </span>
<a href="http://xcb.stdu.edu.cn/2009-05-05-02-26-33/21884-2015-09-10-07-09-14.html" title="重传承、勇创新:四方学院圆满完成迎新工作" target="_blank">
重传承、勇创新:四方学院圆满完成迎...
</a></li>
<li class="latestnewsnews">
<span id="date">09-07 | </span>
<a href="http://xcb.stdu.edu.cn/2009-05-05-02-26-33/21844-2015-09-07-10-10-04.html" title="交通学院:同忆抗战史,共筑中国梦" target="_blank">
交通学院:同忆抗战史,共筑中国梦
</a></li>
<li class="latestnewsnews">
<span id="date">09-06 | </span>
<a href="http://xcb.stdu.edu.cn/2009-05-05-02-26-33/21834-2015-09-06-08-16-17.html" title="欧洲科学院院士张传增教授来校做学术报告" target="_blank">
欧洲科学院院士张传增教授来校做学术报告
</a></li>
<li class="latestnewsnews">
<span id="date">09-10 | </span>
<a href="http://xcb.stdu.edu.cn/2009-05-05-02-26-33/21883-2015-09-10-03-51-32.html" title="我校召开第三十一个教师节庆祝表彰大会" target="_blank">
我校召开第三十一个教师节庆祝表彰大会
</a></li>
class="latestnewsnews">
<span id="date">09-10 | </span>
<a href="(.*?)" title="(.*?)" target="_blank">
\2 latestnewsnews <span> | </span>
<a href=\"(.*?)\" title=\"(.*?)\" target=\"_blank\">
\2 latestnewsnews | </span>
<a href="(.*?)" title="(.*?)"latestnewsnews | </span>\\s*<span style="white-space:pre"> </span><a href=\"(.*?)\" title=\"(.*?)\"说明一下,不好的正则表达式会严重地影响匹配时间从而影响你app的运行速度,要反复研究出最好的正则表达式以便让你的app更流畅。















 2594
2594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









