







继续科普系列,用例子说明为何我们需要卷积神经网络,以及卷积在神经网络中的作用。
目前网上的卷积网络科普大多是翻译的,内容大同小异。本文会更偏重于实际例子。
如果觉得本文有帮助,请记得点个赞噢。如需转载本文,请与本人联系,谢谢。
1. 找橘猫:最简单的办法
今天我们的任务是找出图中有没有橘猫:

怎样用最简单(笨)的方法完成这个任务?那肯定是看图中的橘色占多少面积,比如说超过10%就认为有橘猫:

但怎么告诉电脑?具体来说,图像在电脑中是按像素(就是一个个点)存储的:
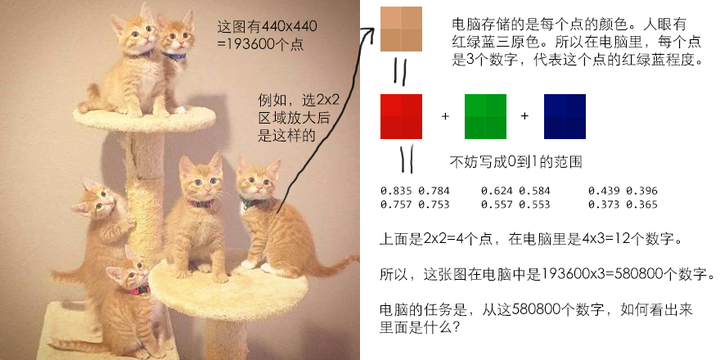
可以计算每个点的色彩与“标准橘色”的接近程度。如果足够接近,就认为属于橘色。
例如,如果我们定义标准橘色是红0.8,绿0.6,蓝0.4。 那么,如果某个点的红色在0.7到0.9范围,绿色在0.5到0.7范围,蓝色在0.3到0.5范围,就可以认为它是橘色。
然后电脑检查一遍所有点,统计有多少个橘色点。如果橘色点的个数超过全体点的10%,就认为有橘猫。这就是一个电脑可以理解的方法。
总结,这里有两个步骤:
- 对图像中的每个点进行相同的操作。
- 然后将结果汇总。
这是卷积神经网络的直观思想,我们将在下文逐步看到它的更多细节。
现在还没有出现“卷积”,不过,这样简单的方法,已经可以写成一个卷积神经网络架构(这段是写给懂神经网络的,不懂的同学可以先忽略),其中的卷积核是1x1,网络还得有几层,需要用好几个神经元,还需要做 Global Average Pooling。可以想想怎么写!
2. 找橘猫:更好的方法
上文的方法无疑是太简单了,很容易误报和漏报:

如何改进?应该再考虑其它特征,例如纹理、形状。特别是纹理。
例如,下图没有出现任何“猫头”“猫身”“猫脚”“猫尾”,但我们一看就知道是橘猫(其它动物的纹理确实不一样):

于是,一个更好的方法是:找到图中的橘猫纹理区域,然后计算区域的面积,这个区域也许有 1% 就足够我们认为图中有橘猫了。
问题是,如何教会电脑什么是“橘猫纹理”?可以用卷积。
3. 卷积操作:
纹理,就是局部的一种图案。如何快速判断图中是否有局部的一种图案?
快速的方法,是使用卷积,也是分两步:
- 对图像中的每个点进行相同的操作。
- 然后将结果汇总。
看例子,这是我在 excel 画的,可以用 SUMPRODUCT 函数做卷积:
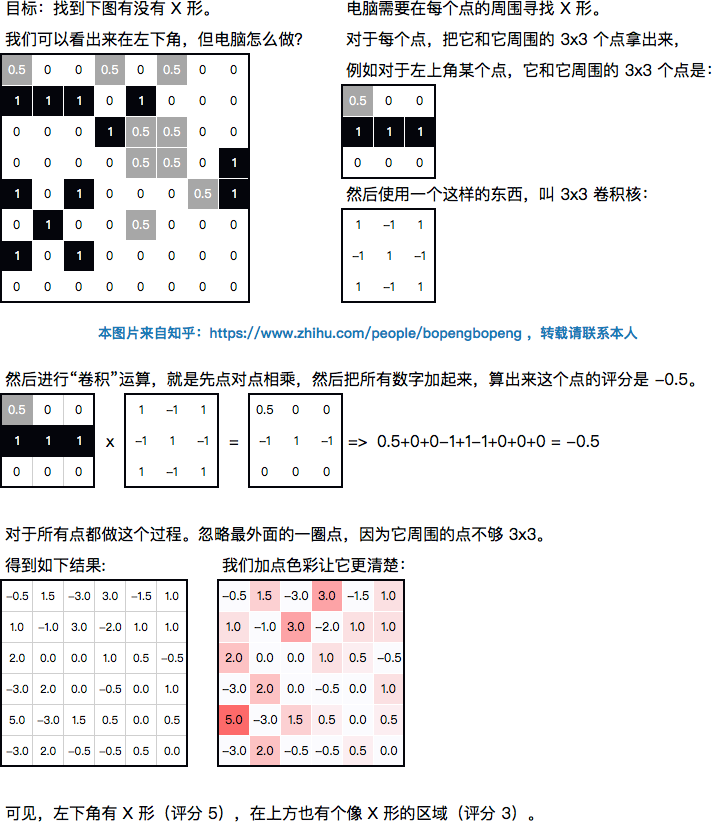
不同的卷积核,可以识别不同的目标。
卷积操作后,图像会变小一点。如果希望图像不变小,可以提前给图片加一圈0(称为padding)。
我们往往还会加入一个“偏置”(bias),就是给整个图像加上一个可以训练的数(这个思想来自于全连接神经网络)。
对于得到的图像,还可以进行进一步变换:
- 可以取最大值(此时会得到5.0),这标志着图中是否存在这个特征。
- 可以取平均值(此时会得到0.25),这标志着图中这个特征的密度。
- 还可以取"最大值"与"平均值"之间的值,会更接近我们的某种直觉。这在数学上有很多办法。
在深度卷积网络中,会经常用到如上的变换(其实就是 max pooling 和 average pooling)。
4. 卷积神经网络的结构
卷积需要卷积核,但怎么找到能有效判断“橘猫纹理”的卷积核?
首先,实际上需要多个卷积核。因为不同角度、不同位置、不同大小、不同猫的纹理都不同,所以我们要用不同的卷积核去匹配。而且不一定直接可以得到“评分”,往往还要经过更多的处理(例如,请思考如何判断纹理的颜色是橘色)。因此我们会使用一个网络结构。
举例:
- 用 A 个卷积核,把原始的图分别用每个卷积核处理,得到 A 张图。
- 然后每张图都做一个非线性操作,例如把得到的图中所有小于 0 的数设置为0。这很重要。简单地说,这是因为卷积是线性操作,如果不加入非线性的操作,最终得到的模型仍然是线性的,无法描述大自然的非线性现象。
- 下面的图是我用鼠标画的......:
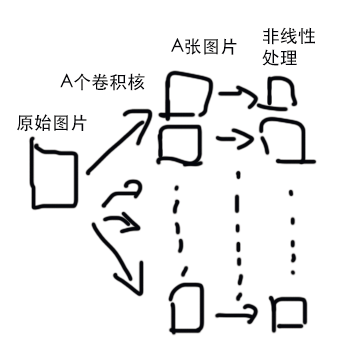
- 得到了 A 张图。那么,再用 B x A 个卷积核,把这 A 张图变成 B 张图。
- 举个例子,用 3 x 2 个卷积核,可以把 2 张图,变成 3 张图。图中的加法,是点对点相加:
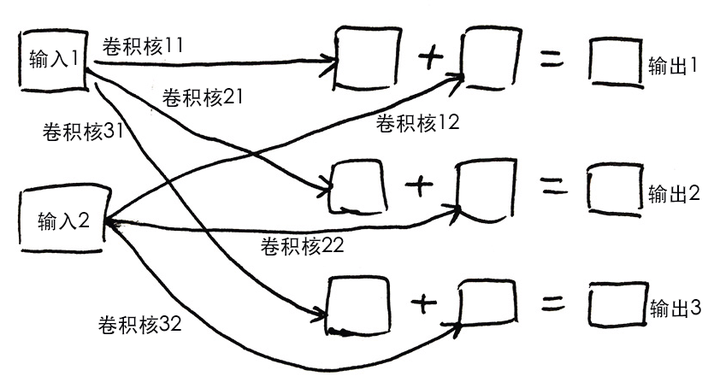
- 别忘了再做非线性处理。
- 然后用 C x B 个卷积核,又可以把 B 张图变成 C 张图。
- 经过很多层之后,我们考虑最终的 N 张图,得到最终的结果。
卷积神经网络的结构,与普通的全链接神经网络非常相似,只是把乘法换成了卷积。 其实,乘法就相当于 1x1 的卷积。
通过使用多层结构,我们可以显著提高网络的识别能力和通用性,这是因为自然界中的图像具有层次性。其实人的大脑的视觉系统也是由多层次组成,也许视觉系统是在进化中形成了这种层次性。这就像:
猫=身体+头部+四肢+尾巴,头部=毛发+眼+嘴+鼻+耳,眼=眼框+眼珠+瞳孔,眼珠=纹理+形状,眼珠形状=弧线+弧线+…
如下图所示(这里显示的不是卷积核,而是“最能激活这个卷积核的输入图像”,或者说卷积核的识别目标),这是经典的 ImageNet 网络,用于识别各种图像。第一层负责识别各种角度的边界以及某些颜色。第二层开始出现简单的形状和纹理。第三层就有更复杂的结构。随后的概念会越来越复杂。

几点补充,对于彩色图像,之前说过图片在电脑中要分红绿蓝色彩,所以其实输入的图就已经是 3 张图,我们在第一层会使用 A x 3 个滤波核,把图片变成 A 张图。
另外,对于图像的问题,我们往往希望更快地把图像变小(既可以提高运算速度,也可以匹配图像在各个尺度上的特征),因此可加入所谓 pooling 层,负责把图像快速缩小。
5. 深度学习的神奇之处
那么,如何找到这么多个卷积核(或者说特征)?
最早的时候,需要人工构造特征(实际是因为当时的电脑运算能力低,必须靠人类专家精心设计特征)。后来随着运算能力的提高,大家可以放心地让电脑半自动挖掘特征。
而现在的深度神经网络,可以全自动发现特征。
简单地说,最开始先把所有卷积核初始化为随机数。然后随机选一小批样本(称为batch),送入网络,算出来怎么微调卷积核可以让识别率提高(具体是通过求导,计算过程叫BP反向传播,其实就是求导的链式法则),于是去微调卷积核。
不断重复这个过程,最后就真的可以得到令人满意的卷积核。这过程中可能还需要实验少量训练方法的参数(这称为“调参”),但整个过程是全自动的,无需任何人工干预,就可以看到随机的卷积核慢慢成型,变为有效的卷积核。
例如下图,从左到右是随着训练的进行,某层中的卷积核的识别目标的变化。可见,一开始卷积核并没有明确的识别目标,但随后会逐渐成型,明确地针对某一种目标进行识别:

由于一开始卷积核是随机初始化,所以它们会有不同的演变方向,于是最终会分别识别多种不同的目标。
这就像在一个丘陵地带下山,如果一开始大家都在一起,那么最后也容易下到一样的地方;但如果一开始大家是随机分布的,那么就会容易到达各个不一样的山谷。















 966
966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









