






在 Java 中,内存的分配是由程序完成的,而内存的释放则是由 Garbage Collecation(GC) 完成的,Java/Android 程序员不用像 C/C++ 程序员一样手动调用相关函数来管理内存的分配和释放,虽然方便了很多,但是这也就造成了内存泄漏的可能性,所以记录一下针对 Android 应用的内存泄漏的检测,处理和优化的相关内容,上篇主要会分析 Java/Android 的内存分配以及 GC 的详细分析,中篇会阐述 Android 内存泄漏的检测和内存泄漏的常见产生情景,下篇会分析一下内存优化的内容。
上篇:Android 性能优化之内存泄漏检测以及内存优化(上)。
中篇:Android 性能优化之内存泄漏检测以及内存优化(中)。
下篇:Android 性能优化之内存泄漏检测以及内存优化(下)。
转载请注明出处:http://blog.csdn.net/self_study/article/details/61919483
对技术感兴趣的同鞋加群544645972一起交流。
Java/Android 内存分配和回收策略分析
这里需要提到的一点是在 Android 4.4 版本之前,使用的是和 Java 一样的 Dalvik rumtime 机制,但是在 4.4 版本及以后,Android 引入了 ART 机制,ART 堆的分配与 GC 就和 Dalvik 的堆的分配与 GC 不一样了,下面会介绍到(关于 Dalvik 和 ART 的对比:Android ART运行时无缝替换Dalvik虚拟机的过程分析)。
Java/Android 内存分配策略
Java/Android 程序运行时的内存分配有三种策略,分别是静态的,栈式的和堆式的,对应的三种存储策略使用的内存空间主要分别是静态存储区(方法区)、堆区和栈区:
- 静态存储区(方法区)
- 内存在程序编译的时候就已经分配好,这块内存在程序整个运行期间都存在,它主要是用来存放静态数据、全局 static 数据和常量;
- 栈区
- 在执行函数时,函数内部局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放,栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限;
- 堆区
- 亦称为动态内存分配,Java/Android 程序在适当的时候使用 new 关键字申请所需要大小的对象内存,然后通过 GC 决定在不需要这块对象内存的时候回收它,但是由于我们的疏忽导致该对象在不需要继续使用的之后,GC 仍然没办法回收该内存区域,这就代表发生了内存泄漏。
在函数中定义的一些基本类型的变量和对象的引用变量(也就是局部变量的引用)都是在函数的栈内存分配的,当在一段代码块中定义一个变量时,Java 就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java 会自动释放掉为该变量分配的内存空间,该内存空间可以立刻被重新使用;堆内存用于存放所有由 new 创建的对象(内容包括该对象其中的所有成员变量)和数组,在堆中分配的内存是由 GC 来管理的,在堆中产生了一个对象或者数组后,还可以在栈中生成一个引用指向这个堆中对象的内存区域,以后就可以通过栈中这个引用变量来访问堆中的这个引用指向的对象或者数组。下面这个图片很好的说明了它两的区别:
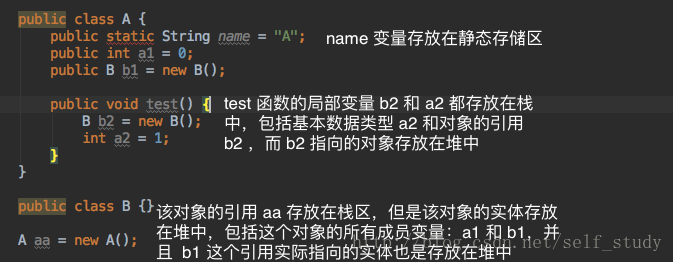
堆是不连续的内存区域(因为系统是用链表来存储空闲内存地址,所以随着内存的分配和释放,肯定是不连续的),堆的大小受限于计算机系统中有效的虚拟内存(32bit 理论上是 4G),所以堆的空间比较大,也比较灵活;栈是一块连续的内存区域,大小是操作系统预定好的,由于存储的都是基本数据类型和对象的引用,所以大小一般不会太大,在几 M 左右。上面的这些差异导致频繁的内存申请和释放造成堆内存在大量的碎片,使得堆的运行效率降低,而对于栈来说,它是先进后出的队列,不产生碎片,运行效率高。
综上所述:
- 局部变量的基本数据类型和引用存储于栈中,引用的对象实体存储于堆中,因为它们属于方法中的变量,生命周期随方法而结束;
- 成员变量全部存储于堆中(包括基本数据类型,对象引用和引用指向的对象实体),因为它们属于类,类对象终究是要被 new 出来使用的;
- 我们所说的内存泄露,只针对堆内存,他们存放的就是引用指向的对象实体。
Java 常用垃圾回收机制
- 引用计数
- 比较古老的回收算法,原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数,垃圾回收时只用收集计数为 0 的对象,此算法最致命的是无法处理循环引用的问题;
- 标记-清除收集器
- 这种收集器首先遍历对象图并标记可到达的对象,然后扫描堆栈以寻找未标记对象并释放它们的内存,这种收集器一般使用单线程工作并会暂停其他线程操作,并且由于它只是清除了那些未标记的对象,而并没有对标记对象进行压缩,导致会产生大量内存碎片,从而浪费内存;
- 标记-压缩收集器
- 有时也叫标记-清除-压缩收集器,与标记-清除收集器有相同的标记阶段,但是在第二阶段则把标记对象复制到堆栈的新域中以便压缩堆栈,这种收集器也会暂停其他操作;
- 复制收集器(半空间)
- 这种收集器将堆栈分为两个域,常称为半空间,每次仅使用一半的空间,JVM 生成的新对象则放在另一半空间中,GC 运行时它把可到达对象复制到另一半空间从而压缩了堆栈,这种方法适用于短生存期的对象,持续复制长生存期的对象则导致效率降低,并且对于指定大小堆来说需要两倍大小的内存,因为任何时候都只使用其中的一半;
- 增量收集器
- 增量收集器把堆栈分为多个域,每次仅从一个域收集垃圾,也可理解为把堆栈分成一小块一小块,每次仅对某一个块进行垃圾收集,这就只会引起较小的应用程序中断时间,使得用户一般不能觉察到垃圾收集器运行;
- 分代收集器
- 复制收集器的缺点是每次收集时所有的标记对象都要被拷贝,从而导致一些生命周期很长的对象被来回拷贝多次,消耗大量的时间,而分代收集器则可解决这个问题,分代收集器把堆栈分为两个或多个域用以存放不同寿命的对象,JVM 生成的新对象一般放在其中的某个域中,过一段时间,继续存在的对象(非短命对象)将转入更长寿命的域中,分代收集器对不同的域使用不同的算法以优化性能。
Java/Android 4.4 版本之下 Dalvik 虚拟机分析
Dalvik 堆简介
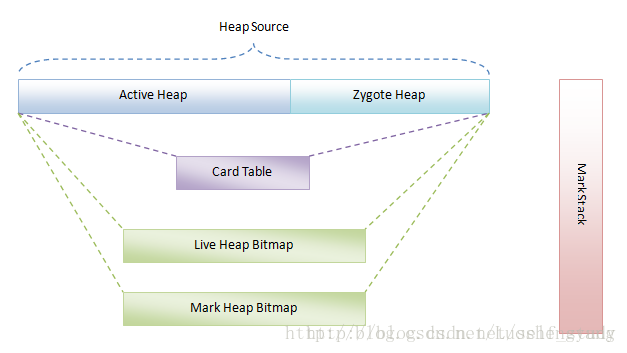
上图为 Dalvik 虚拟机的 Java 堆描述(出自:Dalvik虚拟机Java堆创建过程分析),如上图所示,在 Dalvik 虚拟机中,Java 堆实际上是由一个 Active 堆和一个 Zygote 堆组成的,其中 Zygote 堆用来管理 Zygote 进程在启动过程中预加载和创建的各种对象,而 Active 堆是在 Zygote 进程 fork 第一个子进程之前创建的,应用进程都是通过 Zygote 进程 fork 出来的(相关函数为 ZygoteInit.main 函数:Android TransactionTooLargeException 解析,思考与监控方案),之后无论是 Zygote 进程还是其子进程,都在 Active 堆上进行对象分配和释放,这样做的目的是使得 Zygote 进程和其子进程最大限度地共享 Zygote 堆所占用的内存。上面讲到应用程序进程是由 Zygote 进程 fork 出来的,也就是说应用程序进程使用了一种写时拷贝技术(COW)来复制 Zygote 进程的地址空间,这意味着一开始的时候,应用程序进程和 Zygote 进程共享了同一个用来分配对象的堆,然而当 Zygote 进程或者应用程序进程对该堆进行写操作时,内核才会执行真正的拷贝操作,使得 Zygote 进程和应用程序进程分别拥有自己的一份拷贝。拷贝是一件费时费力的事情,因此为了尽量地避免拷贝,Dalvik 虚拟机将自己的堆划分为两部分,事实上 Dalvik 虚拟机的堆最初是只有一个的,也就是 Zygote 进程在启动过程中创建 Dalvik 虚拟机的时候只有一个堆,但是当 Zygote 进程在 fork 第一个应用程序进程之前会将已经使用了的那部分堆内存划分为一部分,还没有使用的堆内存划分为另外一部分,前者就称为 Zygote 堆,后者就称为 Active 堆。以后无论是 Zygote 进程还是应用程序进程,当它们需要分配对象的时候,都在 Active 堆上进行,这样就可以使得 Zygote 堆被应用进程和 Zygote 进程共享从而尽可能少地被执行写操作,所以就可以减少执行写时的拷贝操作。在 Zygote 堆里面分配的对象其实主要就是 Zygote 进程在启动过程中预加载的类、资源和对象,这意味着这些预加载的类、资源和对象可以在 Zygote 进程和应用程序进程中做到长期共享,这样既能减少拷贝操作还能减少对内存的需求(出自:Dalvik虚拟机垃圾收集机制简要介绍和学习计划)。
Dalvik 分配内存过程分析
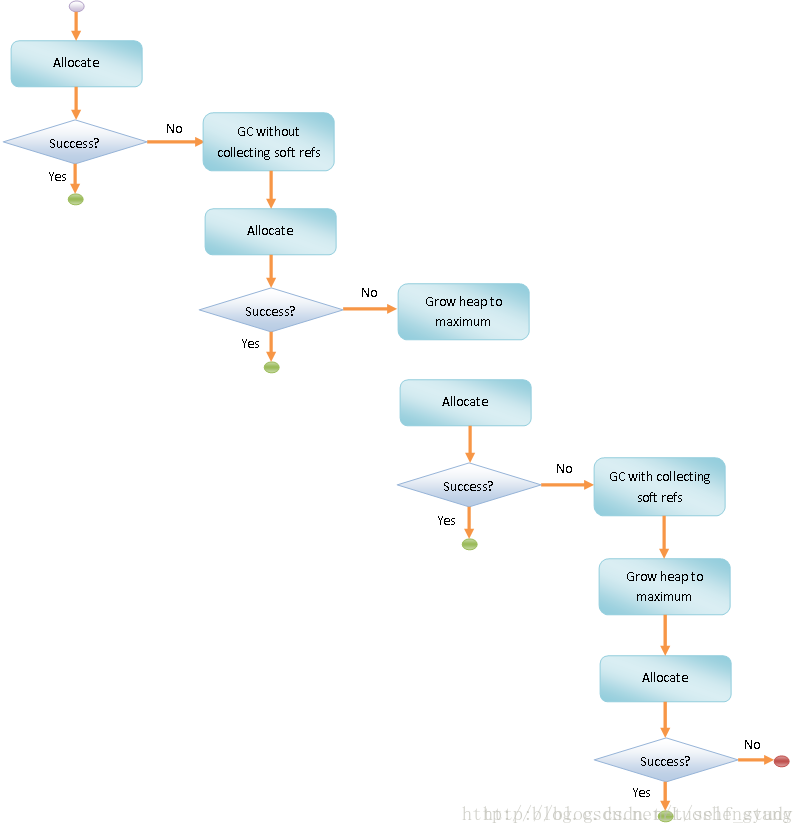
上图就是 Dalvik VM 为新创建对象分配内存的过程(出自:Dalvik虚拟机为新创建对象分配内存的过程分析),我们来看看分配的具体步骤:
- Dalvik 虚拟机实现了一个 dvmAllocObject 函数,每当 Dalvik 虚拟机需要为对象分配内存时,就会调用函数 dvmAllocObject,例如,当 Dalvik 虚拟机的解释器遇到一个 new 指令时,它就会调用函数 dvmAllocObject;
- 函数 dvmAllocObject 调用函数 dvmMalloc 从 Java 堆中分配一块指定大小的内存给新创建的对象使用,如果分配成功,那么接下来就先使用宏 DVM_OBJECT_INIT 来初始化新创建对象的成员变量 clazz,使得新创建的对象可以与某个特定的类关联起来,接着再调用函数 dvmTrackAllocation 记录当前的内存分配信息,以便通知 DDMS。函数 dvmMalloc 返回的只是一块内存地址,这是没有类型的,但是由于每一个 Java 对象都是从 Object 类继承下来的,因此函数 dvmAllocObject 可以将获得的没有类型的内存块强制转换为一个 Object 对象;
- dvmMalloc 函数接着调用到了另一个函数 tryMalloc ,真正执行内存分配操作的就是这个 tryMalloc 函数,dvmMalloc 函数操作如果分配内存成功,则记录当前线程成功分配的内存字节数和对象数等信息;否则的话,就记录当前线程失败分配的内存字节数和对象等信息,方便通过 DDMS 等工具对内存使用信息进行统计,同时会调用函数 throwOOME 抛出一个 OOM 异常;
void* dvmMalloc(size_t size, int flags)
{
void *ptr;
dvmLockHeap();
/* Try as hard as possible to allocate some memory.
*/
ptr = tryMalloc(size);
if (ptr != NULL) {
/* We've got the memory.
*/
if (gDvm.allocProf.enabled) {
Thread* self = dvmThreadSelf();
gDvm.allocProf.allocCount++;
gDvm.allocProf.allocSize += size;
if (self != NULL) {
self->allocProf.allocCount++;
self->allocProf.allocSize += size;
}
}
} else {
/* The allocation failed.
*/
if (gDvm.allocProf.enabled) {
Thread* self = dvmThreadSelf();
gDvm.allocProf.failedAllocCount++;
gDvm.allocProf.failedAllocSize += size;
if (self != NULL) {
self->allocProf.failedAllocCount++;
self->allocProf.failedAllocSize += size;
}
}
}
dvmUnlockHeap();
if (ptr != NULL) {
/*
* If caller hasn't asked us not to track it, add it to the
* internal tracking list.
*/
if ((flags & ALLOC_DONT_TRACK) == 0) {
dvmAddTrackedAlloc((Object*)ptr, NULL);
}
} else {
/*
* The allocation failed; throw an OutOfMemoryError.
*/
throwOOME();
}
return ptr;
} - 再来具体分析一下函数 tryMalloc,tryMalloc 会调用函数 dvmHeapSourceAlloc 在 Java 堆上分配指定大小的内存,如果分配成功,那么就将分配得到的地址直接返回给调用者了,函数 dvmHeapSourceAlloc 在不改变 Java 堆当前大小的前提下进行内存分配,这是属于轻量级的内存分配动作;
- 如果上一步内存分配失败,这时候就需要执行一次 GC 了,不过如果 GC 线程已经在运行中,即 gDvm.gcHeap->gcRunning 的值等于 true,那么就直接调用函数 dvmWaitForConcurrentGcToComplete 等到 GC 执行完成;否则的话,就需要调用函数 gcForMalloc 来执行一次 GC 了,参数 false 表示不要回收软引用对象引用的对象;
-
static void *tryMalloc(size_t size) { void *ptr; ...... ptr = dvmHeapSourceAlloc(size); if (ptr != NULL) { return ptr; } if (gDvm.gcHeap->gcRunning) { ...... dvmWaitForConcurrentGcToComplete(); } else { ...... gcForMalloc(false); } ptr = dvmHeapSourceAlloc(size); if (ptr != NULL) { return ptr; } ptr = dvmHeapSourceAllocAndGrow(size); if (ptr != NULL) { ...... return ptr; } gcForMalloc(true); ptr = dvmHeapSourceAllocAndGrow(size); if (ptr != NULL) { return ptr; } ...... return NULL; } - GC 执行完毕后,再次调用函数 dvmHeapSourceAlloc 尝试轻量级的内存分配操作,如果分配成功,那么就将分配得到的地址直接返回给调用者了;
- 如果上一步内存分配失败,这时候就得考虑先将 Java 堆的当前大小设置为 Dalvik 虚拟机启动时指定的 Java 堆最大值再进行内存分配了,这是通过调用函数 dvmHeapSourceAllocAndGrow 来实现的;
- 如果调用函数 dvmHeapSourceAllocAndGrow 分配内存成功,则直接将分配得到的地址直接返回给调用者了;
- 如果上一步内存分配还是失败,这时候就得出狠招了,再次调用函数 gcForMalloc 来执行 GC,不过这次参数为 true 表示要回收软引用对象引用的对象;
- 上一步 GC 执行完毕,再次调用函数 dvmHeapSourceAllocAndGrow 进行内存分配,这是最后一次努力了,如果还分配内存不成功那就是 OOM 了。
-
Dalvik GC 策略分析
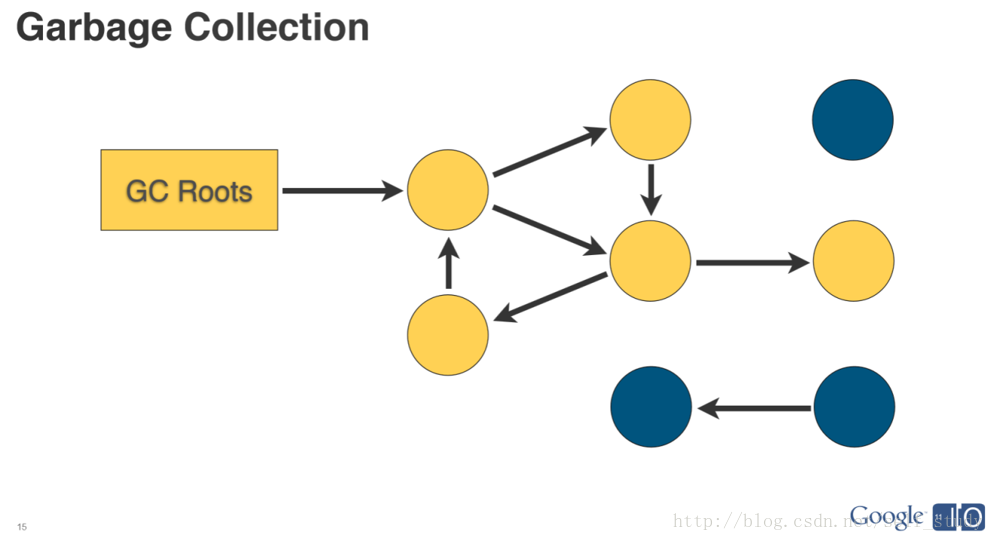
不同语言平台进行标记回收内存的算法是不一样的,Java 则是采用的 GC-Root 标记回收算法,在 Android 4,4 之下也是和 Java 一样的机制(Android 4.4 和之后都是使用了 ART,和dalvik GC 有不同的地方),下面这张来自 Google IO 2011 大会的图就很好的展示了Android 4.4 版本之下的回收策略:
图中的每个圆节点代表对象的内存资源,箭头代表可达路径,当一个圆节点和 GC Roots 存在可达的路径时,表示当前它指向的内存资源正在被引用,虚拟机是无法对其进行回收的(图中的黄色节点);反过来,如果当前的圆节点和 GC Roots 不存在可达路径,则意味着这块对象的内存资源不再被程序引用,系统虚拟机可以在 GC 的时候将其内存回收掉。具体点来说,Java/Android 的内存垃圾回收机制是从程序的主要运行对象(如静态对象/寄存器/栈上指向的内存对象等,对应上面的 GC Roots)开始检查调用链,当遍历一遍后得到上述这些无法回收的对象和他们所引用的对象链组成无法回收的对象集合,而剩余其他的孤立对象(集)就作为垃圾被 GC 回收。GC 为了能够正确释放对象,必须监控每一个对象的运行状态,包括对象的申请、引用、被引用、赋值等。监视对象状态是为了更加准确地、及时地释放对象,而释放对象的根本原则就是该对象不再被引用。
上面介绍了 GC 的回收机制,那么接下来据此说一下什么是内存泄漏,从抽象定义上讲,Java/Android 平台的内存泄漏是指没有用的对象资源仍然和 GC Roots 保持可达路径,导致系统无法进行回收,具体一点讲就是,通过 GC Roots 的调用链可以遍历到这个没有被使用的对象,导致该资源无法进行释放。最常见的比如,Android 中的 Activity 中创建一个内部类 Handler 用来处理多线程的消息,而内部类会持有外部类的引用,所以该 Handler 的对象会持有 Activity 的引用,而如果这个 Handler 对象被子线程持有,子线程正在进行耗时的操作没法在短时间内执行完成,那么一系列的引用链导致 Activity 关闭之后一直无法被释放,重复地打开关闭这个 Activity 会造成这些 Activity 的对象一直在内存当中,最终达到一定程度之后会产生 OOM 异常。
在 Java/Android 中,虽然我们有几个函数可以访问 GC,例如运行GC的函数 System.gc(),但是根据 Java 语言规范定义,该函数不保证 JVM 的垃圾收集器一定会马上执行。因为不同的 JVM 实现者可能使用不同的算法管理 GC,通常 GC 的线程的优先级别较低。JVM 调用 GC 的策略也有很多种,有的是内存使用到达一定程度时 GC 才开始工作,也有定时执行的,有的是平缓执行GC,也有的是中断式执行GC,但通常来说我们开发者不需要关心这些。Dalvik GC 日志分析
上面介绍到,虽然我们有几个函数可以访问 GC,但是该函数不会保证 GC 操作会立马执行,那么我怎么去监听系统的 GC 过程来实时分析当前的内存状态呢?其实很简单,Android 4.4 版本之下系统 Dalvik 每进行一次 GC 操作都会在 LogCat 中打印一条对应的日志,我们只需要去分析这条日志就可以了,日志的基本格式如下:
D/dalvikvm: <GC_Reason> <Amount_freed>, <Heap_stats>, <Pause_time>这段日志分为 4 个部分:
- 首先是第一部分 GC_Reason,就是触发这次 GC 的原因,一般情况下有以下几种原因:
- GC_CONCURRENT
- 当我们应用程序的堆内存快要满的时候,系统会自动触发 GC 操作来释放内存;
- GC_FOR_MALLOC
- 当我们的应用程序需要分配更多内存,可是现有内存已经不足的时候,系统会进行 GC 操作来释放内存;
- GC_HPROF_DUMP_HEAP
- 当生成内存分析 HPROF 文件的时候,系统会进行 GC 操作,我们下面会分析一下 HPROF 文件;
- GC_EXPLICIT
- 这种情况就是我们刚才提到过的,主动通知系统去进行GC操作,比如调用 System.gc() 方法来通知系统,或者在 DDMS 中,通过工具按钮也是可以显式地告诉系统进行 GC 操作的。
- 第二部分 Amount_freed,表示系统通过这次 GC 操作释放了多少的内存;
- 第三部分 Heap_stats,代表当前内存的空闲比例以及使用情况(活动对象所占内存 / 当前程序总内存);
- 第四部分 Pause_time,代表了这次 GC 操作导致应用程序暂停的时间,在 Android 2.3 版本之前 GC 操作是不能并发执行的,所以如果当系统正在 GC 的时候,应用程序只能阻塞等待 GC 结束,GC 的时间基本在几百毫秒左右,所以用户会感觉到略微明显的卡顿,体验不好,在 Android 2.3 以及之后到 4.4 版本之前,Dalvik GC 的操作改成了并发执行,也就是说 GC 的操作不会影响到主应用程序的正常运行,但是 GC 操作的开始和结束仍然会短暂的阻塞一段时间,不过时间上面就已经短到让用户无法察觉到了。
Android 4.4 及以上 ART 分析
ART 堆简介
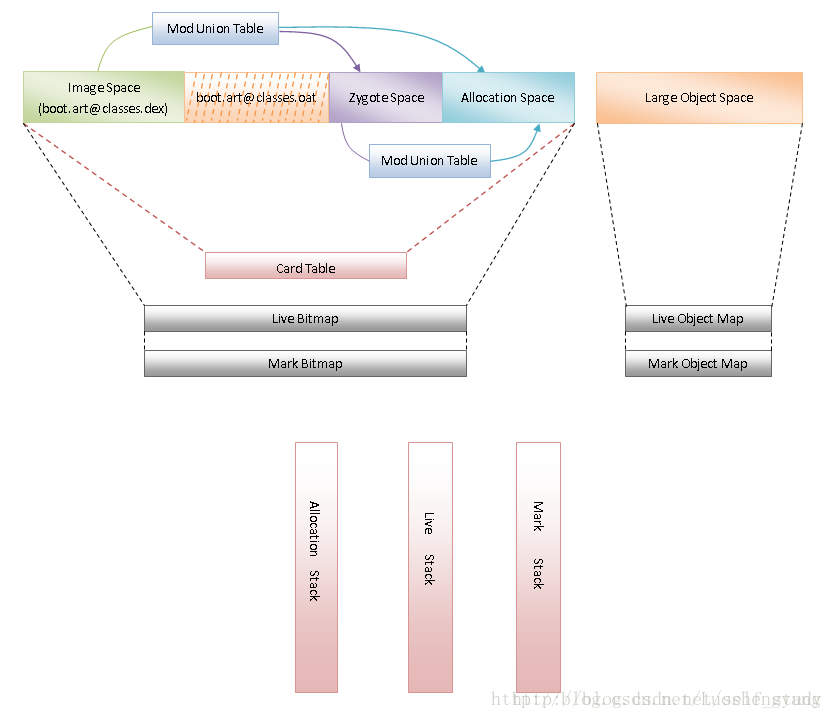
上图为 ART 堆的描述(图片出自:ART运行时垃圾收集机制简要介绍和学习计划),ART 也涉及到类似于 Dalvik 虚拟机的 Zygote 堆、Active 堆、Card Table、Heap Bitmap 和 Mark Stack 等概念。从图中可以看到,ART 运行时堆划分为四个空间,分别是 Image Space、Zygote Space、Allocation Space 和 Large Object Space,其中 Image Space、Zygote Space 和 Allocation Space 是在地址上连续的空间,称为 Continuous Space,而 Large Object Space 是一些离散地址的集合,用来分配一些大对象,称为 Discontinuous Space。
在 Image Space 和 Zygote Space 之间,隔着一段用来映射 system@framework@boot.art@classes.oat 文件的内存,system@framework@boot.art@classes.oat 是一个 OAT 文件,它是由在系统启动类路径中的所有 .dex 文件翻译得到的,而 Image Space 空间就包含了那些需要预加载的系统类对象,这意味着需要预加载的类对象是在生成 system@framework@boot.art@classes.oat 这个 OAT 文件的时候创建并且保存在文件 system@framework@boot.art@classes.dex 中,以后只要系统启动类路径中的 .dex 文件不发生变化(即不发生更新升级),那么以后每次系统启动只需要将文件 system@framework@boot.art@classes.dex 直接映射到内存即可,省去了创建各个类对象的时间。之前使用 Dalvik 虚拟机作为应用程序运行时的时候,每次系统启动都需要为那些预加载的系统类创建类对象,而虽然 ART 运行时第一次启动会和 Dalvik 一样比较慢,但是以后启动实际上会快不少。由于 system@framework@boot.art@classes.dex 文件保存的是一些预先创建的对象,并且这些对象之间可能会互相引用,因此我们必须保证 system@framework@boot.art@classes.dex 文件每次加载到内存的地址都是固定的,这个固定的地址保存在 system@framework@boot.art@classes.dex 文件头部的一个 Image Header 中,此外 system@framework@boot.art@classes.dex 文件也依赖于 system@framework@boot.art@classes.oat 文件,所以也会将后者固定加载到 Image Space 的末尾。
Zygote Space 和 Allocation Space 与上面讲到的 Dalvik 虚拟机中的 Zygote 堆和 Active 堆的作用是一样的,Zygote Space 在 Zygote 进程和应用程序进程之间共享的,而 Allocation Space 则是每个进程独占的。同样的 Zygote 进程一开始只有一个 Image Space 和一个 Zygote Space,在 Zygote 进程 fork 出第一个子进程之前,就会把 Zygote Space 一分为二,原来的已经被使用的那部分堆还叫 Zygote Space,而未使用的那部分堆就叫 Allocation Space,以后的对象都在新分出来的 Allocation Space 上分配,通过上述这种方式,就可以使得 Image Space 和 Zygote Space 在 Zygote 进程和应用程序进程之间进行共享,而 Allocation Space 就每个进程都独立地拥有一份,和 Dalvik 同样既能减少拷贝操作还能减少对内存的需求。有一点需要注意的是虽然 Image Space 和 Zygote Space 都是在 Zygote 进程和应用程序进程之间进行共享的,但是前者的对象只创建一次而后者的对象需要在系统每次启动时根据运行情况都重新创建一遍(出自:ART运行时垃圾收集机制简要介绍和学习计划)。
ART 运行时提供了两种 Large Object Space 实现,其中一种实现和 Continuous Space 的实现类似,预先分配好一块大的内存空间,然后再在上面为对象分配内存块,不过这种方式实现的 Large Object Space 不像 Continuous Space 通过 C 库的内块管理接口来分配和释放内存,而是自己维护一个 Free List,每次为对象分配内存时,都是从这个 Free List 找到合适的空闲的内存块来分配,释放内存的时候,也是将要释放的内存添加到该 Free List 去;另外一种 Large Object Space 实现是每次为对象分配内存时,都单独为其映射一新的内存,也就是说,为每一个对象分配的内存块都是相互独立的,这种实现方式相比上面介绍的 Free List 实现方式更简单一些。在 Android 4.4 中,ART 运行时使用的是后一种实现方式,为每一对象映射一块独立的内存块的 Large Object Space 实现称为 LargeObjectMapSpace,它与 Free List 方式的实现都是继承于类 LargeObjectSpace,LargeObjectSpace 又分别继承了 DiscontinuousSpace 和 AllocSpace,因此我们就可以知道,LargeObjectMapSpace 描述的是一个在地址空间上不连续的 Large Object Space。ART 分配内存过程分析
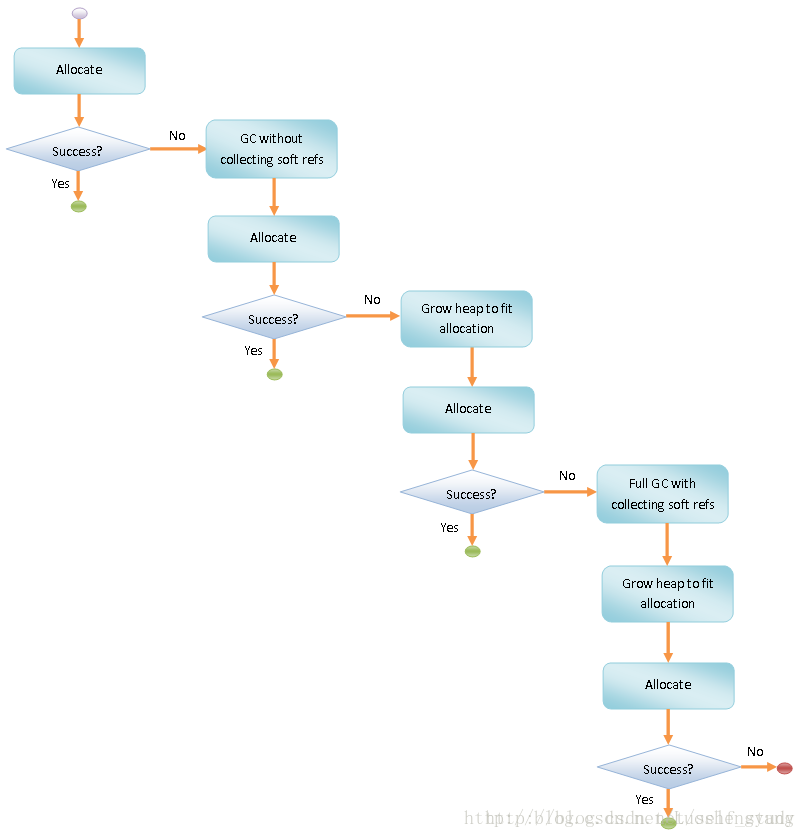
上图就是 ART 为新创建对象分配内存的过程(出自:ART运行时为新创建对象分配内存的过程分析),可以看到 ART 为新创建对象分配内存的过程和 Dalvik VM 几乎是一样的,区别仅仅在于垃圾收集的方式和策略不一样。
ART 运行时为从 DEX 字节码翻译得到的 Native 代码提供的一个函数调用表中,有一个 pAllocObject 接口是用来分配对象的,当 ART 运行时以 Quick 模式运行在 ARM 体系结构时,上述提到的 pAllocObject 接口由函数 art_quick_alloc_object 来实现,art_quick_alloc_object 是一段汇编代码,最终经过一系列的调用之后最终会调用 ART 运行时内部的 Heap 对象的成员函数 AllocObject 在堆上分配对象(具体的过程:ART运行时为新创建对象分配内存的过程分析),其中要分配的大小保存在当前 Class 对象的成员变量 object_size_ 中。 Heap 类的成员函数 AllocObject 首先是要确定要在哪个 Space 上分配内存,可以分配内存的 Space 有三个,分别 Zygote Space、Allocation Space 和 Large Object Space,不过 Zygote Space 在还没有划分出 Allocation Space 之前就在 Zygote Space 上分配,而当 Zygote Space 划分出 Allocation Space 之后,就只能在 Allocation Space 上分配,同时 Heap 类的成员变量 alloc_space_ 在 Zygote Space 还没有划分出 Allocation Space 之前指向 Zygote Space,而划分之后就指向 Allocation Space,Large Object Space 则始终由 Heap 类的成员变量 large_object_space_ 指向。只要满足以下三个条件就在 Large Object Space 上分配,否则就在 Zygote Space 或者 Allocation Space 上分配:- 请求分配的内存大于等于 Heap 类的成员变量 large_object_threshold_ 指定的值,这个值等于 3 * kPageSize,即 3 个页面的大小;
- 已经从 Zygote Space 划分出 Allocation Space,即 Heap 类的成员变量 have_zygote_space_ 的值等于 true;
- 被分配的对象是一个原子类型数组,即 byte 数组、int 数组和 boolean 数组等。
- 调用 Object 类的成员函数 SetClass 设置新分配对象 obj 的类型;
- 调用 Heap 类的成员函数 RecordAllocation 记录当前的内存分配状况;
- 检查当前已经分配出去的内存是否已经达到由 Heap 类的成员变量 concurrent_start_bytes_ 设定的阀值,如果已经达到,那么就调用 Heap 类的成员函数 RequestConcurrentGC 通知 GC 执行一次并行 GC。
mirror::Object* Heap::AllocObject(Thread* self, mirror::Class* c, size_t byte_count) { ...... mirror::Object* obj = NULL; size_t bytes_allocated = 0; ...... bool large_object_allocation = byte_count >= large_object_threshold_ && have_zygote_space_ && c->IsPrimitiveArray(); if (UNLIKELY(large_object_allocation)) { obj = Allocate(self, large_object_space_, byte_count, &bytes_allocated); ...... } else { obj = Allocate(self, alloc_space_, byte_count, &bytes_allocated); ...... } if (LIKELY(obj != NULL)) { obj->SetClass(c); ...... RecordAllocation(bytes_allocated, obj); ...... if (UNLIKELY(static_cast<size_t>(num_bytes_allocated_) >= concurrent_start_bytes_)) { ...... SirtRef<mirror::Object> ref(self, obj); RequestConcurrentGC(self); } ...... return obj; } else { ...... self->ThrowOutOfMemoryError(oss.str().c_str()); return NULL; } }函数 Allocate 首先调用成员函数 TryToAllocate 尝试在不执行 GC 的情况下进行内存分配,如果分配失败再调用成员函数 AllocateInternalWithGc 进行带 GC 的内存分配,Allocate 是一个模板函数,不同类型的 Space 会导致调用不同重载的成员函数 TryToAllocate 进行不带 GC 的内存分配。虽然可以用来分配内存的 Space 有 Zygote Space、Allocation Space 和 Large Object Space 三个,但是前两者的类型是相同的,因此实际上只有两个不同重载版本的成员函数 TryToAllocate,它们的实现如下所示:
inline mirror::Object* Heap::TryToAllocate(Thread* self, space::AllocSpace* space, size_t alloc_size, bool grow, size_t* bytes_allocated) { if (UNLIKELY(IsOutOfMemoryOnAllocation(alloc_size, grow))) { return NULL; } return space->Alloc(self, alloc_size, bytes_allocated); } // DlMallocSpace-specific version. inline mirror::Object* Heap::TryToAllocate(Thread* self, space::DlMallocSpace* space, size_t alloc_size, bool grow, size_t* bytes_allocated) { if (UNLIKELY(IsOutOfMemoryOnAllocation(alloc_size, grow))) { return NULL; } if (LIKELY(!running_on_valgrind_)) { return space->AllocNonvirtual(self, alloc_size, bytes_allocated); } else { return space->Alloc(self, alloc_size, bytes_allocated); } }Heap 类两个重载版本的成员函数 TryToAllocate 的实现逻辑都几乎是相同的,首先是调用另外一个成员函数 IsOutOfMemoryOnAllocation 判断分配请求的内存后是否会超过堆的大小限制,如果超过则分配失败;否则的话再在指定的 Space 进行内存分配。函数IsOutOfMemoryOnAllocation的实现如下所示:
inline bool Heap::IsOutOfMemoryOnAllocation(size_t alloc_size, bool grow) { size_t new_footprint = num_bytes_allocated_ + alloc_size; if (UNLIKELY(new_footprint > max_allowed_footprint_)) { if (UNLIKELY(new_footprint > growth_limit_)) { return true; } if (!concurrent_gc_) { if (!grow) { return true; } else { max_allowed_footprint_ = new_footprint; } } } return false; }成员变量 num_bytes_allocated_ 描述的是目前已经分配出去的内存字节数,成员变量 max_allowed_footprint_ 描述的是目前堆可分配的最大内存字节数,成员变量 growth_limit_ 描述的是目前堆允许增长到的最大内存字节数,这里需要注意的一点是 max_allowed_footprint_ 是 Heap 类施加的一个限制,不会对各个 Space 实际可分配的最大内存字节数产生影响,并且各个 Space 在创建的时候,已经把自己可分配的最大内存数设置为允许使用的最大内存字节数。如果目前堆已经分配出去的内存字节数再加上请求分配的内存字节数 new_footprint 小于等于目前堆可分配的最大内存字节数 max_allowed_footprint_,那么分配出请求的内存字节数之后不会造成 OOM,因此 Heap 类的成员函数 IsOutOfMemoryOnAllocation 就返回false;另一方面,如果目前堆已经分配出去的内存字节数再加上请求分配的内存字节数 new_footprint 大于目前堆可分配的最大内存字节数 max_allowed_footprint_,并且也大于目前堆允许增长到的最大内存字节数 growth_limit_,那么分配出请求的内存字节数之后造成 OOM,因此 Heap 类的成员函数 IsOutOfMemoryOnAllocation 这时候就返回 true。
剩下另外一种情况,目前堆已经分配出去的内存字节数再加上请求分配的内存字节数 new_footprint 大于目前堆可分配的最大内存字节数 max_allowed_footprint_,但是小于等于目前堆允许增长到的最大内存字节数 growth_limit_,这时候就要看情况会不会出现 OOM 了:如果 ART 运行时运行在非并行 GC 的模式中,即 Heap 类的成员变量 concurrent_gc_ 等于 false,那么取决于允不允许增长堆的大小,即参数 grow 的值,如果不允许,那么 Heap 类的成员函数 IsOutOfMemoryOnAllocation 就返回 true,表示当前请求的分配会造成 OOM,如果允许,那么 Heap 类的成员函数 IsOutOfMemoryOnAllocation 就会修改目前堆可分配的最大内存字节数 max_allowed_footprint_ 并且返回 false,表示允许当前请求的分配,这意味着在非并行 GC 运行模式中,如果分配内存过程中遇到内存不足并且当前可分配内存还未达到增长上限时,要等到执行完成一次非并行 GC 后才能成功分配到内存,因为每次执行完成 GC 之后都会按照预先设置的堆目标利用率来增长堆的大小;另一方面,如果 ART 运行时运行在并行 GC 的模式中,那么只要当前堆已经分配出去的内存字节数再加上请求分配的内存字节数 new_footprint 不超过目前堆允许增长到的最大内存字节数 growth_limit_,那么就不管允不允许增长堆的大小都认为不会发生 OOM,因此 Heap 类的成员函数 IsOutOfMemoryOnAllocation 就返回 false,这意味着在并行 GC 运行模式中,在分配内存过程中遇到内存不足,并且当前可分配内存还未达到增长上限时,无需等到执行并行 GC 后就有可能成功分配到内存,因为实际执行内存分配的 Space 可分配的最大内存字节数是足够的。ART GC 策略以及过程分析
在 Android 4.4 版本以及之后就使用了 ART 运行时,在安装的时候就将应用翻译成机器码执行,效率比起以前的 Dalvik 虚拟机更高,但是缺点就是安装之后的应用体积变大和安装的时间会变长,不过相对于优点来说,这点缺点不算什么。ART 运行时与 Dalvik 虚拟机一样,都使用了 Mark-Sweep 算法进行垃圾回收,因此它们的垃圾回收流程在总体上是一致的,但是 ART 运行时对堆的划分更加细致,因而在此基础上实现了更多样的回收策略。不同的策略有不同的回收力度,力度越大的回收策略每次回收的内存就越多,并且它们都有各自的使用情景,这样就可以使得每次执行 GC 时,可以最大限度地减少应用程序停顿:
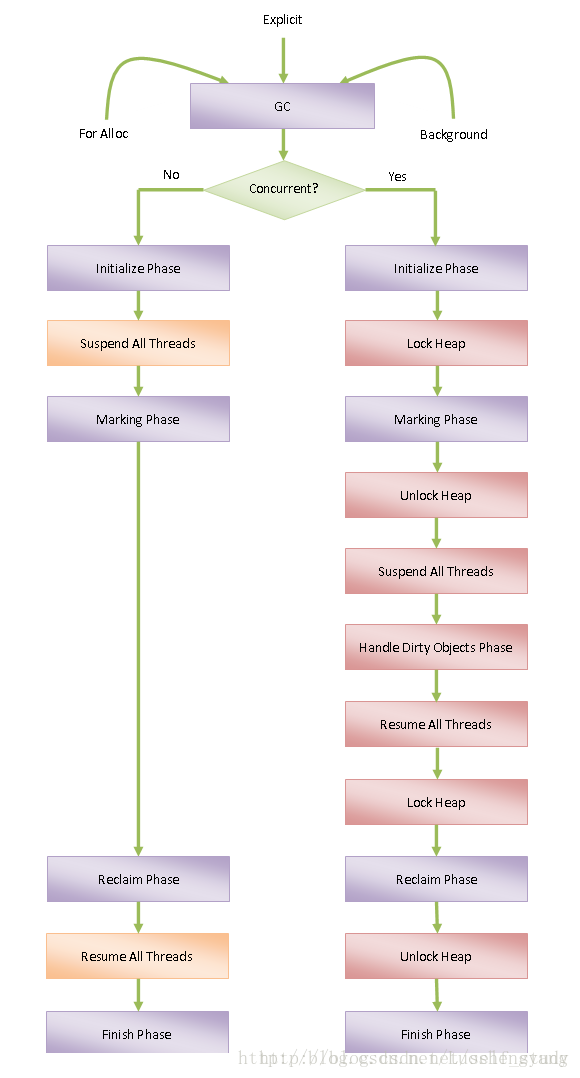
上图描述了 ART 运行时的垃圾收集收集过程(图片出自:ART运行时垃圾收集(GC)过程分析),最上面三个箭头描述触发 GC 的三种情况,左边的流程图描述非并行 GC 的执行过程,右边的流程图描述并行 GC 的执行流程,过程如下所示:- 非并行 GC :
- 调用子类实现的成员函数 InitializePhase 执行 GC 初始化阶段;
- 挂起所有的 ART 运行时线程;
- 调用子类实现的成员函数 MarkingPhase 执行 GC 标记阶段;
- 调用子类实现的成员函数 ReclaimPhase 执行 GC 回收阶段;
- 恢复第 2 步挂起的 ART 运行时线程;
- 调用子类实现的成员函数 FinishPhase 执行 GC 结束阶段。
- 并行 GC :
- 调用子类实现的成员函数 InitializePhase 执行 GC 初始化阶段;
- 获取用于访问 Java 堆的锁;
- 调用子类实现的成员函数 MarkingPhase 执行 GC 并行标记阶段;
- 释放用于访问 Java 堆的锁;
- 挂起所有的 ART 运行时线程;
- 调用子类实现的成员函数 HandleDirtyObjectsPhase 处理在 GC 并行标记阶段被修改的对象;
- 恢复第 5 步挂起的 ART 运行时线程;
- 重复第 5 到第 7 步,直到所有在 GC 并行阶段被修改的对象都处理完成;
- 获取用于访问 Java 堆的锁;
- 调用子类实现的成员函数 ReclaimPhase 执行 GC 回收阶段;
- 释放用于访问 Java 堆的锁;
- 调用子类实现的成员函数 FinishPhase 执行 GC 结束阶段。
- 非并行 GC 的标记阶段和回收阶段是在挂住所有的 ART 运行时线程的前提下进行的,因此只需要执行一次标记即可;
- 并行 GC 的标记阶段只锁住了Java 堆,因此它不能阻止那些不是正在分配对象的 ART 运行时线程同时运行,而这些同时进运行的 ART 运行时线程可能会引用了一些在之前的标记阶段没有被标记的对象,如果不对这些对象进行重新标记的话,那么就会导致它们被 GC 回收造成错误,因此与非并行 GC 相比,并行 GC 多了一个处理脏对象的阶段,所谓的脏对象就是我们前面说的在 GC 标记阶段同时运行的 ART 运行时线程访问或者修改过的对象;
- 并行 GC 并不是自始至终都是并行的,例如处理脏对象的阶段就是需要挂起除 GC 线程以外的其它 ART 运行时线程,这样才可以保证标记阶段可以结束。
上面 ART 堆内存分配的时候,我们提到了有两种可能会触发 GC 的情况,第一种情况是没有足够内存分配给请求时,会调用 Heap 类的成员函数 CollectGarbageInternal 触发一个原因为 kGcCauseForAlloc 的 GC;第二种情况下分配出请求的内存之后,堆剩下的内存超过一定的阀值,就会调用 Heap 类的成员函数 RequestConcurrentGC 请求执行一个并行 GC;此外,还有第三种情况会触发GC,如下所示:void Heap::CollectGarbage(bool clear_soft_references) { // Even if we waited for a GC we still need to do another GC since weaks allocated during the // last GC will not have necessarily been cleared. Thread* self = Thread::Current(); WaitForConcurrentGcToComplete(self); CollectGarbageInternal(collector::kGcTypeFull, kGcCauseExplicit, clear_soft_references); }当我们调用 Java 层的 java.lang.System 的静态成员函数 gc 时,如果 ART 运行时支持显式 GC,那么它就会通过 JNI 调用 Heap 类的成员函数 CollectGarbageInternal 来触发一个原因为 kGcCauseExplicit 的 GC,ART 运行时默认是支持显式 GC 的,但是可以通过启动选项 -XX:+DisableExplicitGC 来关闭。所以 ART 运行时在三种情况下会触发 GC,这三种情况通过三个枚举 kGcCauseForAlloc、kGcCauseBackground 和 kGcCauseExplicitk 来描述:
// What caused the GC? enum GcCause { // GC triggered by a failed allocation. Thread doing allocation is blocked waiting for GC before // retrying allocation. kGcCauseForAlloc, // A background GC trying to ensure there is free memory ahead of allocations. kGcCauseBackground, // An explicit System.gc() call. kGcCauseExplicit, };ART 运行时的所有 GC 都是以 Heap 类的成员函数 CollectGarbageInternal 为入口:
collector::GcType Heap::CollectGarbageInternal(collector::GcType gc_type, GcCause gc_cause, bool clear_soft_references) { Thread* self = Thread::Current(); ...... // Ensure there is only one GC at a time. bool start_collect = false; while (!start_collect) { { MutexLock mu(self, *gc_complete_lock_); if (!is_gc_running_) { is_gc_running_ = true; start_collect = true; } } if (!start_collect) { // TODO: timinglog this. WaitForConcurrentGcToComplete(self); ...... } } ...... if (gc_type == collector::kGcTypeSticky && alloc_space_->Size() < min_alloc_space_size_for_sticky_gc_) { gc_type = collector::kGcTypePartial; } ...... collector::MarkSweep* collector = NULL; for (const auto& cur_collector : mark_sweep_collectors_) { if (cur_collector->IsConcurrent() == concurrent_gc_ && cur_collector->GetGcType() == gc_type) { collector = cur_collector; break; } } ...... collector->clear_soft_references_ = clear_soft_references; collector->Run(); ...... { MutexLock mu(self, *gc_complete_lock_); is_gc_running_ = false; last_gc_type_ = gc_type; // Wake anyone who may have been waiting for the GC to complete. gc_complete_cond_->Broadcast(self); } ...... return gc_type; }参数 gc_type 和 gc_cause 分别用来描述要执行的 GC 的类型和原因,而参数 clear_soft_references 用来描述是否要回收被软引用指向的对象,Heap 类的成员函数 CollectGarbageInternal 的执行逻辑:
- 通过一个 while 循环不断地检查 Heap 类的成员变量 is_gc_running_,直到它的值等于 false 为止,这表示当前没有其它线程正在执行 GC,当它的值等于 true 时就表示其它线程正在执行 GC,这时候就要调用 Heap 类的成员函数 WaitForConcurrentGcToComplete 等待其执行完成,注意在当前 GC 执行之前,Heap 类的成员变量 is_gc_running_ 会被设置为true;
- 如果当前请求执行的 GC 类型为 kGcTypeSticky,但是当前 Allocation Space 的大小小于 Heap 类的成员变量 min_alloc_space_size_for_sticky_gc_ 指定的阀值,那么就改为执行类型为 kGcTypePartial;
- 从 Heap 类的成员变量 mark_sweep_collectors_ 指向的一个垃圾收集器列表找到一个合适的垃圾收集器来执行 GC,ART 运行时在内部创建了六个垃圾收集器,这六个垃圾收集器分为两组,一组支持并行 GC,另一组不支持;每一组都是由三个类型分别为 kGcTypeSticky、kGcTypePartial 和 kGcTypeFull 的垃垃圾收集器组成,这里说的合适的垃圾收集器是指并行性与 Heap 类的成员变量 concurrent_gc_ 一致,并且类型也与参数 gc_type 一致的垃圾收集器;
- 找到合适的垃圾收集器之后,就将参数 clear_soft_references 的值保存在它的成员变量 clear_soft_references_ 中,以便可以告诉它要不要回收被软引用指向的对象,然后再调用它的成员函数 Run 来执行 GC;
- GC 执行完毕,将 Heap 类的成员变量 is_gc_running_ 设置为false,以表示当前 GC 已经执行完毕,下一次请求的 GC 可以执行了,此外也会将 Heap 类的成员变量 last_gc_type_ 设置为当前执行的 GC 的类型,这样下一次执行 GC 时,就可以执行另外一个不同类型的 GC,例如如果上一次执行的 GC 的类型为 kGcTypeSticky,那么接下来的两次 GC 的类型就可以设置为 kGcTypePartial 和 kGcTypeFull,这样可以使得每次都能执行有效的 GC;
- 通过 Heap 类的成员变量 gc_complete_cond_ 唤醒那些正在等待 GC 执行完成的线程。
ART GC 与 Dalvik GC 对比
比起 Dalvik 的回收策略,ART 的 CMS(concurrent mark sweep,同步标记回收)有以下几个优点:
- 阻塞的次数相比于 Dalvik 来说,从两次减少到了一次,Dalvik 第一次的阻塞大部分工作是在标记 root,而在 ART CMS 中则是被每个执行线程同步标记它们自己的 root 完成的,所以 ART 能够立马继续运行;
- 和 Dalvik 类似,ART GC 同样在回收执行之前有一次暂停,但是关键的不同是 Dalvik 的一些执行阶段在 ART 中是并行同步执行的,这些阶段包括标记过程、系统 weak Reference 清理过程(比如 jni weak globals 等)、重新标记非 GC Root 节点,Card 区域的提前清理。在 ART 中仍然需要阻塞的过程是扫描 Card 区域的脏数据和重新标记 GC Root,这两个操作能够降低阻塞的时间;
- 还有一个 ART GC 比 Dalvik 有提升的地方是 sticky CMS 提升了 GC 的吞吐量,不像正常的分代 GC 机制,sticky CMS 是不移动堆内存的,它不会给新对象分配一个特定的区域(年轻代),新分配的对象被保存在一个分配栈里面,这个栈就是一个简单的 Object 数组,这就避免了所需要移动对象的操作,也就获得了低阻塞性,但是缺点就是会增加堆的对象复杂性;
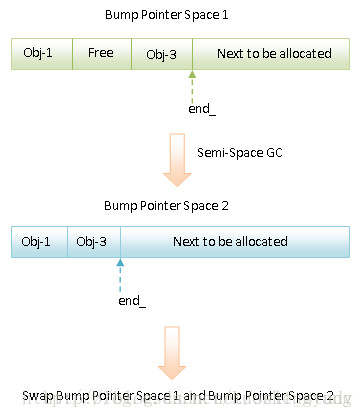
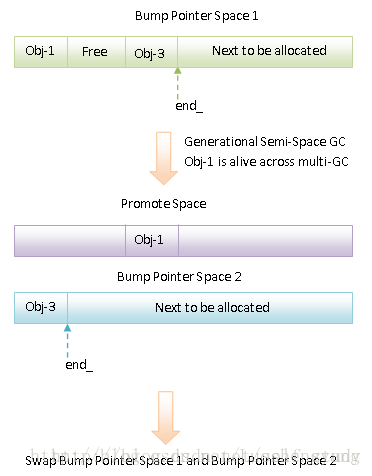
如果应用程序在前台运行时,这时候 GC 被称为 Foreground GC,同时 ART 还有一个 Background GC,顾名思义就是在后台运行的 GC,应用程序在前台运行时响应性是最重要的,因此也要求执行的 GC 是高效的,相反应用程序在后台运行时,响应性不是最重要的,这时候就适合用来解决堆的内存碎片问题,因此上面提到的所有 Mark-Sweep GC 适合作为 Foreground GC,而 Compacting GC(压缩 GC) 适合作为 Background GC。当从 Foreground GC 切换到 Background GC,或者从 Background GC 切换到 Foreground GC,ActivityManager 会通知发生一次 Compacting GC 的行为,这是由于 Foreground GC 和 Background GC 的底层堆空间结构是一样的,因此发生 Foreground GC 和 Background GC 切换时,需要将当前存活的对象从一个 Space 转移到另外一个 Space 上去,这个刚好就是 Semi-Space compaction 和 Homogeneous space compaction 适合干的事情。Background GC 压缩内存就能够使得内存碎片变少,从而达到缩减内存的目的,但是压缩内存的时候会暂时阻塞应用进程。 Semi-Space compaction 和 Homogeneous space compaction 有一个共同特点是都具有一个 From Space 和一个 To Space,在 GC 执行期间,在 From Space 分配的还存活的对象会被依次拷贝到 To Space 中,这样就可以达到消除内存碎片的目的。与 Semi-Space compaction 相比,Homogeneous space compaction 还多了一个 Promote Space,当一个对象是在上一次 GC 之前分配的,并且在当前 GC 中仍然是存活的,那么它就会被拷贝到 Promote Space 而不是 To Space 中,这相当于是简单地将对象划分为新生代和老生代的,即在上一次 GC 之前分配的对象属于老生代的,而在上一次 GC 之后分配的对象属于新生代的,一般来说老生代对象的存活性要比新生代的久,因此将它们拷贝到 Promote Space 中去,可以避免每次执行 Semi-Space compaction 或者 Homogeneous space compaction 时都需要对它们进行无用的处理,我们来看看这两种 Background GC 的执行过程图:
Semi-Space compaction
Homogeneous space compaction
以上图片来自: ART运行时Semi-Space(SS)和Generational Semi-Space(GSS)GC执行过程分析,Bump Pointer Space 1 和 Bump Pointer Space 2 就是我们前面说的 From Space 和 To Space。Semi-Space compaction 一般发生在低内存的设备上,而 Homogenous space compaction 是非低内存设备上的默认压缩模式。GC Roots 解析
GC Roots 特指的是垃圾收集器(Garbage Collector)的对象,GC 会收集那些不是 GC Roots 且没有被 GC Roots 引用的对象,一个对象可以属于多个 Root,GC Roots 有几下种:
- Class
- 由系统类加载器(system class loader)加载的对象,这些类是不能够被回收的,他们可以以静态字段的方式持有其它对象。我们需要注意的一点就是,通过用户自定义的类加载器加载的类,除非相应的 java.lang.Class 实例以其它的某种(或多种)方式成为 Roots,否则它们并不是 Roots;
- Thread
- 活着的线程;
- Stack Local
- Java 方法的 local 变量或参数;
- JNI Local
- JNI 方法的 local 变量或参数;
- JNI Global
- 全局 JNI 引用;
- Monitor Used
- 用于同步的监控对象;
- Held by JVM
- 用于 JVM 特殊目的由 GC 保留的对象,但实际上这个与 JVM 的实现是有关的,可能已知的一些类型是系统类加载器、一些 JVM 熟悉的重要异常类、一些用于处理异常的预分配对象以及一些自定义的类加载器等,然而 JVM 并没有为这些对象提供其它的信息,因此就只有留给分析分员去确定哪些是属于 “JVM 持有” 的了。
ART 日志分析
ART 的 log 不同于 Dalvik 的 log 机制,不是明确调用的情况下不会打印的 GCs 的 log 信息,GC只会在被判定为很慢时输出信息,更准确地说就是 GC 暂停的时间超过 5ms 或者 GC 执行的总时间超过 100ms。如果 app 不是处于一种停顿可察觉的状态,那么 GC 就不会被判定为执行缓慢,但是此时显式 GC 信息会被 log 出来,参考自:Investigating Your RAM Usage。
I/art: <GC_Reason> <GC_Name> <Objects_freed>(<Size_freed>) AllocSpace Objects, <Large_objects_freed>(<Large_object_size_freed>) <Heap_stats> LOS objects, <Pause_time(s)>例如:
I/art : Explicit concurrent mark sweep GC freed 104710(7MB) AllocSpace objects, 21(416KB) LOS objects, 33% free, 25MB/38MB, paused 1.230ms total 67.216ms- GC Reason :什么触发了GC,以及属于哪种类型的垃圾回收,可能出现的值包括
- Concurrent
- 并发 GC,不会挂起 app 线程,这种 GC 在后台线程中运行,不会阻止内存分配;
- Alloc
- GC 被初始化,app 在 heap 已满的时候请求分配内存,此时 GC 会在当前线程(请求分配内存的线程)执行;
- Explicit
- GC 被 app 显式请求,例如通过调用 System.gc() 或者 runtime.gc(),和 Dalvik 一样,ART 建议相信 GC,尽可能地避免显式调用 GC,不建议显式调用 GC 的原因是因为会阻塞当前线程并引起不必要的 CPU 周期,如果 GC 导致其它线程被抢占的话,显式 GC 还会引发 jank(jank是指第 n 帧绘制过后,本该绘制第 n+1 帧,但因为 CPU 被抢占,数据没有准备好,只好再显示一次第 n 帧,下一次绘制时显示第 n+1);
- NativeAlloc
- 来自 native 分配的 native memory 压力引起的 GC,比如 Bitmap 或者 RenderScript 对象;
- CollectorTransition
- heap 变迁引起的 GC,运行时动态切换 GC 造成的,垃圾回收器变迁过程包括从 free-list backed space 复制所有对象到 bump pointer space(反之亦然),当前垃圾回收器过渡只会在低 RAM 设备的 app 改变运行状态时发生,比如从可察觉的停顿态到非可察觉的停顿态(反之亦然);
- HomogeneousSpaceCompact
- HomogeneousSpaceCompact 指的是 free-list space 空间的压缩,经常在 app 变成不可察觉的停顿态时发生,这样做的主要原因是减少 RAM 占用并整理 heap 碎片;
- DisableMovingGc
- 不是一个真正的 GC 原因,正在整理碎片的 GC 被 GetPrimitiveArrayCritical 阻塞,一般来说因为 GetPrimitiveArrayCritical 会限制垃圾回收器内存移动,强烈建议不要使用;
- HeapTrim
- 不是一个真正的 GC 原因,仅仅是一个收集器被阻塞直到堆压缩完成的记录。
- GC Name:ART有几种不同的GC
- Concurrent mark sweep (CMS)
- 全堆垃圾收集器,负责收集释放除 image space(上面 ART 堆的图片中对应区域)外的所有空间;
- Concurrent partial mark sweep
- 差不多是全堆垃圾收集器,负责收集除 image space 和 zygote space 外的所有空间;
- Concurrent sticky mark sweep
- 分代垃圾收集器,只负责释放从上次 GC 到现在分配的对象,该 GC 比全堆和部分标记清除执行得更频繁,因为它更快而且停顿更短;
- Marksweep + semispace
- 非同步的,堆拷贝压缩和 HomogeneousSpaceCompaction 同时执行。
- Objects freed
- 本次 GC 从非大对象空间(non large object space)回收的对象数目。
- Size freed
- 本次 GC 从非大对象空间回收的字节数。
- Large objects freed
- 本次 GC 从大对象空间里回收的对象数目。
- Large object size freed
- 本次GC从大对象空间里回收的字节数。
- Heap stats
- 可用空间所占的百分比和 [已使用内存大小] / [ heap 总大小]。
- Pause times
- 一般情况下,GC 运行时停顿次数和被修改的对象引用数成比例,目前 ART CMS GC 只会在 GC 结束的时停顿一次,GC 过渡会有一个长停顿,是 GC 时耗的主要因素。
Java/Android 引用解析
GC 过程是和对象引用的类型是严重相关的,我们在平时接触到的一般有三种引用类型,强引用、软引用、弱引用和虚引用:
级别 回收时机 用途 生存时间 强引用 从来不会 对象的一般状态 Cool 软引用 在内存不足的时候 联合 ReferenceQueue 构造有效期短/占内存大/生命周期长的对象的二级高速缓冲器(内存不足时才清空) 内存不足时终止 弱引用 在垃圾回收时 联合 ReferenceQueue 构造有效期短/占内存大/生命周期长的对象的一级高速缓冲器(系统发生GC则清空) GC 运行后终止 虚引用 在垃圾回收时 联合 ReferenceQueue 来跟踪对象被垃圾回收器回收的活动 GC 运行后终止 在 Java/Android 开发中,为了防止内存溢出,在处理一些占内存大而且生命周期比较长对象的时候,可以尽量应用软引用和弱引用,软/弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收器回收,Java 虚拟机就会把这个软引用加入到与之关联的引用队列中,利用这个队列可以得知被回收的软/弱引用的对象列表,从而为缓冲器清除已失效的软/弱引用。
Android 内存泄漏和优化
具体的请看中篇:Android 性能优化之内存泄漏检测以及内存优化(中)和下篇:Android 性能优化之内存泄漏检测以及内存优化(下)。
引用
http://blog.csdn.net/luoshengyang/article/details/42555483
http://blog.csdn.net/luoshengyang/article/details/41688319
http://blog.csdn.net/luoshengyang/article/details/42492621
http://blog.csdn.net/luoshengyang/article/details/41338251
http://blog.csdn.net/luoshengyang/article/details/41581063
https://mp.weixin.qq.com/s?__biz=MzA4MzEwOTkyMQ==&mid=2667377215&idx=1&sn=26e3e9ec5f4cf3e7ed1e90a0790cc071&chksm=84f32371b384aa67166a3ff60e3f8ffdfbeed17b4c8b46b538d5a3eec524c9d0bcac33951a1a&scene=0&key=c2240201df732cf062d22d3cf95164740442d817864520af90bb0e71fa51102f2e91475a4f597ec20653c59d305c8a3e518d3f575d419dfcf8fb63a776e0d9fa6d3a9a6a52e84fedf3f467fe4af1ba8b&ascene=0&uin=Mjg5MDI3NjQ2Mg%3D%3D&devicetype=iMac+MacBookPro11%2C4+OSX+OSX+10.12.3+build(16D32)&version=12010310&nettype=WIFI&fontScale=100&pass_ticket=Upl17Ws6QQsmZSia%2F%2B0xkZs9DYxAJBQicqh8rcaxYUjcu3ztlJUPxYrQKML%2BUtuf
http://geek.csdn.net/news/detail/127226
http://www.jianshu.com/p/216b03c22bb8
https://zhuanlan.zhihu.com/p/25213586
https://joyrun.github.io/2016/08/08/AndroidMemoryLeak/
http://www.cnblogs.com/larack/p/6071209.html
https://source.android.com/devices/tech/dalvik/gc-debug.html
http://blog.csdn.net/high2011/article/details/53138202
http://gityuan.com/2015/10/03/Android-GC/
http://www.ayqy.net/blog/android-gc-log%E8%A7%A3%E8%AF%BB/
https://developer.android.com/studio/profile/investigate-ram.html


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









