







写在开头:初次接触Python,翻一翻网上的python文章,都说无论新手和老手都在用python网页爬虫。正好最近网课考试,这种有题库的网课,爬一下题库就在所难免,于是就用了python试一下,于是就准备写这个python网页爬虫初体验
概述
某航教务网络课程,首页需要登录,使用的cookie验证。使用的beautifulsoup4分析数据的包,正则以及网络包默认就有,所以应该要自己安装的就是beautifulsoup4包
cookie基本知识
1.什么是cookie
Cookie 是在 HTTP 协议下,服务器或脚本可以维护客户工作站上信息的一种方式。Cookie 是由 Web 服务器保存在用户浏览器(客户端)上的小文本文件,它可以包含有关用户的信息。无论何时用户链接到服务器,Web 站点都可以访问 Cookie 信息——百度文库
简而言之cookie就是网络上身份认证的一种手段,对于网络上需要登录才能提供的服务,比如博客的个人栏目,都需要使用cookie去维护用户的的登录信息(当然现在用session的也比较多)。
2.cookie的工作过程
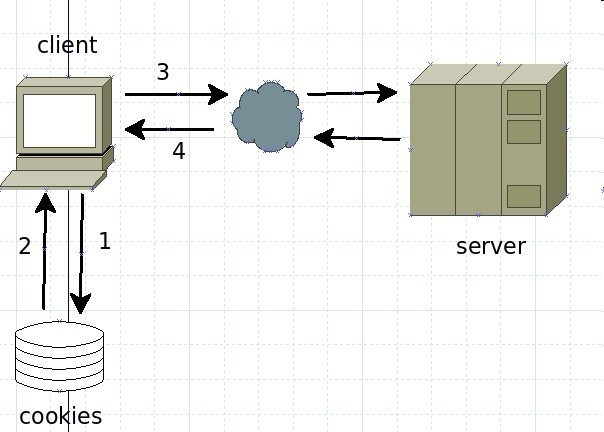
1.如果客户端根据网址查找客户端的历史文件,如果有历史的cookies,客户端会取出这个cookie发给服务器进行身份验证。
2.如果没有该cookie,服务器端将会要求客户端登录,在登录成功后在返回的包的头部字段会有set-cookie字段,client取得该cookie之后每次请求网页的时候都会携带这个cookie用于身份验证。
关于cookie字段的详细内容,在实现模拟登陆的过程中没有必要了解。
3.实现模拟登陆
注意模拟登录的网址不是你看到的网址,而是登录表单实际提交的地址,直接网页网页源码,这个很好找的
1.构造头部信息
headers = { 'Host':'hostname',
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









