







6月,汇集当今大数据界精英的Spark Summit 2017盛大召开,Spark作为当今最炙手可热的大数据技术框架,向全世界展示了最新的技术成果、生态体系及未来发展规划。
巨杉作为业内领先的分布式数据库厂商,也是Spark全球的14家发行商之一,受邀在本次大会做了题为“分布式数据库+Spark架构和应用”的分享。巨杉数据库联合创始人、CTO及总架构师也将给大家分享大会的见闻以及这一架构的发展和应用情况。
Spark全面进化
扩大生态助力人工智能
随着Spark 2.2 版本的发布,Spark性能有了更大提高。在Spark Streaming方面,最新版本在相同条件下达到了常用流处理架构(如Apache Flink以及Kafka Streaming)的5倍以上,超过6000万记录/秒。在测试中,Spark对于重要负载的端到端响应时间也已经达到了亚毫秒级别,真正实现了实时性。
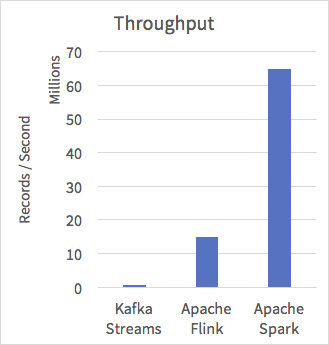
Spark 公布的流处理性能对比图
除了性能的提升,Spark的Structured Streaming体系也基本实现了产品化。在性能、稳定性的保证下,Structured Streaming支持更多的大数据体系架构,从图处理到深度学习都能提供最高性能产品级别的实时流处理支持。
此外,在大热的人工智能方面,Spark也开始了全面的支持。Spark 2.2版本加入了完整的Deep Learning Pipeline,作为深度学习的数据源,提供全面的数据支持。
王涛认为,“Data is the new oil!”十分准确地描述了大数据和人工智能间的定位问题。可以说,人工智能是新的引擎,大数据就是引擎所需要的能源。数据是深度学习技术的基础,只有两者齐备,人工智能才能真正“自我学习和自我进化”。Spark作为大数据领域最受欢迎的高性能分析处理框架和流处理框架之一,全面支撑人工智能和Deep learning也是必然的。使用Spark最新的Deep Learning Pipeline套件,用户可以在现有的Spark机器学习工作流程中调用深度学习库,对成型的模型进行迁移学习,利用Spark的分布式计算引擎通过AI处理复杂数据。Databricks首席技术专家Matei Zaharia也表示,这一套件的正式发布,是AI开发普及化、大众化的重要一步,可以帮助更多用户更好的入门AI和深度学习技术,能大大加强Spark技术在未来技术领域中的重要性。
毋庸置疑的是,Spark的产品化进度正在加快,也在不断扩大自己的技术生态。
分布式数据库+Spark架构引领主流
SequoiaDB x Spark完善大数据生态
近年来,“分布式数据库+Spark”的架构随着Spark的应用中发展成为其中一套主流架构。分布式数据库提供的海量数据存储管理能力以及高并发地实时数据查询交互,与Spark的批处理实现了完美的互补,是Spark应用架构不可或缺的重要支撑。
巨杉是国内对于“分布式数据库+Spark”这套架构最早的实践者之一,SequoiaDB的实时高性能、弹性扩展性成为了这套架构的坚实数据基础。从2015年至今,SequoiaDB分布式数据库与Spark的深度整合架构已经十分成熟,目前已经有许多银行等大型企业在数据加工、交互式访问等生产系统中应用了这种架构。
为实现SequoiaDB分布式数据库与Spark的深度整合,技术方面,通过巨杉自己的连接器将分布式数据库与Spark架构进行深度对接。
· 对接的方式同时支持文件块和datanode两种方式,并且可以很好的支持查询条件下压,通过匹配巨杉数据库自身的索引,提高查询效率。
· SequoiaDB for Spark Connector在生成查询的访问计划时,还能智能判断查询的数据和Spark 计算Worker的位置,默认优先匹配本地数据,从而减少数据在网络传输的开销。
· 连接器可以实现文件块级别的并发,充分利用分布式多节点有效提高集群整体I/O吞吐能力。
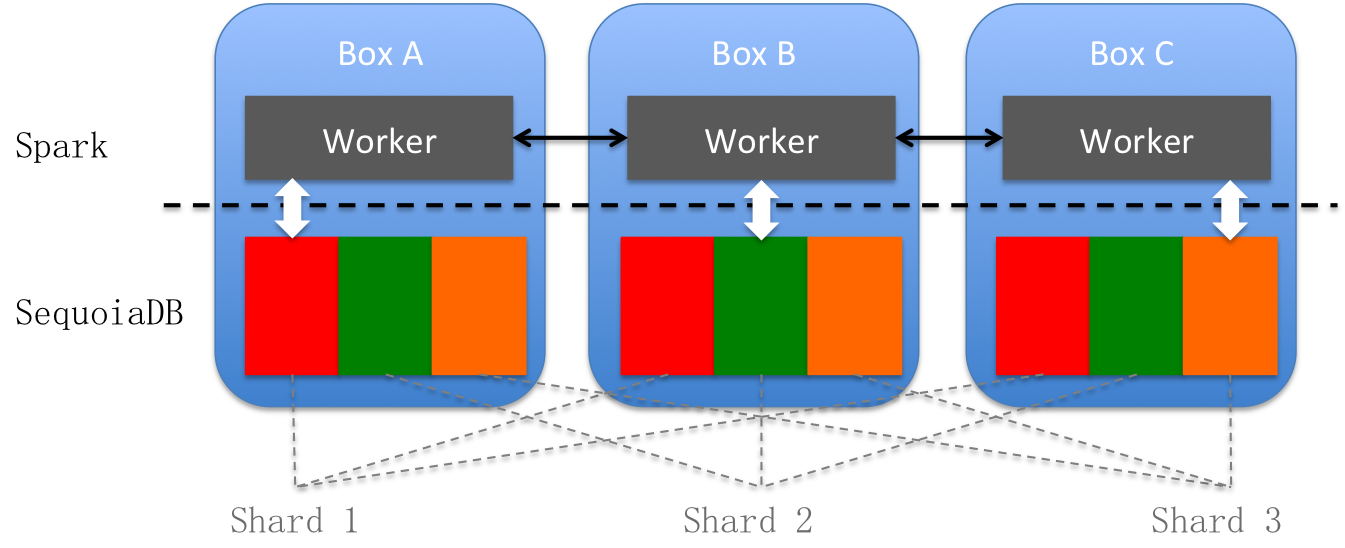
分布式数据库+Spark 技术架构图
Spark默认支持从文本文件和HDFS文件等数据源中获取计算的数据来源也支持将第三方的产品作为Spark计算框架的计算任务的数据来运之一。对于分布式数据库,除了能够支持海量数据分布式存储外,还能够为用户提供多索引功能,支持用户在高并发场景下高性能实时数据访问。
分布式数据库+Spark两者结合主要的使用场景是:在海量数据中,通过条件检索记录和在海量数据中,针对某些特定范围记录,例如针对过去一个月的记录进行统计分析。这类有明确查询条件的查询和分析,非常适合Spark+分布式数据库。分布式数据库+Spark架构将能实现从数据高并发实时交互查询,到高性能数据计算再到数据实时流处理的全功能覆盖。
在应用实践上,某股份制银行使用巨杉数据库构建近线数据平台,通过SequoiaDB+Spark架构,SequoiaDB保证了全量近线数据的存储和实时在线,同时提供了全量数据的实时查询访问,而Spark则提供了条件检索和统计分析的功能。
一方面将用户的全量历史数据做到全面在线化,使得银行客户能够通过柜面应用、手机、网银等多渠道访问到自己开户以来所有的交易行为;另一方面对银行内部的行员提供自由报表分析、支持公检法历史数据查询等多种业务。
此外,某银行通过SequoiaDB+Spark的底层数据平台,为其“实时头寸” 解决了原有报表系统只能做“T+1”的限制,为系统提供了高性能的实时数据分析、查询、展现。其中,Spark的高性能提高了分析统计的效率,而SequoiaDB的数据实时访问则保证了数据的真正“实时性”。
对于接下来和Spark合作的方向,王涛表示,随着Spark生态的不断丰富以及其技术组件对不同技术的支持不断完善,Spark生态将会是未来大数据领域最强有力的一股技术力量。
作为Spark全球发行商之一,巨杉会进一步加强与Spark/Databricks的合作,加大SequoiaDB+Spark方案并力求与Spark框架进行更深度的对接,实现从数据高并发实时交互查询访问,到高性能数据计算再到数据实时流处理的全功能覆盖,使企业用户能够获得最高性能、最全面的大数据平台。
微信客服:
sequoiadb111
















 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









