







 本文深入探讨了分布式数据库SequoiaDB的关联查询原理,讲解了NL Join、Hash Join和Merge Join的策略。SequoiaSQL支持NL Join和Hash Join,文章详细阐述了触发NL Join的条件及优化关联查询的方法,帮助用户更好地理解和使用SequoiaSQL。
本文深入探讨了分布式数据库SequoiaDB的关联查询原理,讲解了NL Join、Hash Join和Merge Join的策略。SequoiaSQL支持NL Join和Hash Join,文章详细阐述了触发NL Join的条件及优化关联查询的方法,帮助用户更好地理解和使用SequoiaSQL。
1 前言
分布式数据库从过去成为NoSQL的数据库发展开始,底层的数据存储结构变得多样化,包括KV、文档、列式等结构。各自有自己擅长的业务应用场景,例如操作型和分析型就是最简单的区分。
然而SQL的支持成为了业界的共识。 SQL语言几十年的发展已经非常成熟,技术基础也非常广泛。全世界90%以上的开发,无论业务操作型还是分析型都以SQL的数据处理为主。无论底层数据存储结构是关系型还是非关系型都将对系统开发透明。开发者只需根据自己的业务场景来选择合适的数据库,但不需要改变自身的开发模式。
本篇文章主要是向大家介绍分布式数据库的关联查询基本原理,以及用户在使用SequoiaSQL做关联查询时应该注意哪些地方,也希望用户能够通过本篇文章了解到更多分布式数据库操作的相关知识,同时帮助用户快速掌握SequoiaSQL的开发和使用技巧。
2 关联查询介绍
2.1 关联查询在传统数据库使用
在关系型数据库中如果要介绍关联查询,那么必然会涉及到数据库范式设计的内容。那么为什么关系型数据库会有范式设计这种开发理念,这还得从关系型数据库的发展历程说起。
关系型数据库是从上世纪70年代开始发展起来的,那个时候硬件设备的成本价格是非常高的,那个时候像十几MB的存储硬件就已经是顶配级别了,即使到了90年代,硬盘的存储空间也就是达到几百兆级别,价格依然昂贵。
所以关系型数据库是在一个存储资源极度紧张的背景下诞生的,在这种情况下,数据库研发的理念理所当然的往“尽可能利用存储空间”方向发展,同样使用数据库的用户也同样想尽办法往数据库中多存储有价值数据库。
资深的DBA明白,要想数据存储冗余低,那么遵循范式设计是非常有效的方法。
范式设计,核心思想就是尽可能确保表中每一列的数据都不会产冗余,例如第一范式里要求数据库表中所有字段值都是不可分解的原子值,第二范式里要求数据库表中的每列都和主键相关,第三范式里要求数据库表中消除与主键之间的间接相关。
2.2 关联的作用
由于关系型数据库的范式设计开发理念,所以会导致过去建设一个完整的系统,会有比较复杂的数据模型,可能一个系统会包含几十甚至上百张数据表,而每张表之间都有主外建关联关系。
在这种数据模型下,用户如果要在系统中查询某些数据,则可能需要同时用到几张表甚至是几十张表的数据才能够得到完整的结果集。所以要在这种遵循范式设计的系统中操作数据表,就难以避免需要用到数据库的关联方法。
2.3 常见关联查询策略
在传统的关系型数据库中,最常见的关联策略有三种,分别是:NL Join(Nest Loop Join)、Hash Join和Merge Join。
1)NL Join
NL Join的技术原理相对来说比较好理解,实际上读者可以理解为两张表一条记录一条记录地作比对,如果符合关联条件则关联成功。
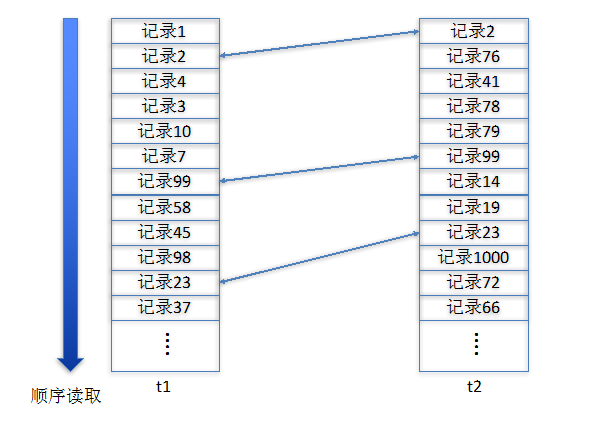
图 1
使用伪代码来表示则是
for (int i=0; i<t1.length; ++i) {
for (int j&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 406
406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









